
Perchè il Lakehouse è destinato a restare
Introduzione
Negli ultimi anni si è assistito a una contrapposizione tra due diversi ecosistemi, i data warehouse ed i data lake: il primo concepito come il sistema core per l’analisi e la business intelligence, generalmente incentrato su SQL, e il secondo basato sui data lake, che fornisce la spina dorsale per l’elaborazione avanzata e l’AI/ML, operando su un’ampia varietà di linguaggi che vanno da Scala a Python, R e SQL.
Nonostante la contrapposizione tra i rispettivi leader di mercato, pensiamo per esempi a Snowflake e Databricks, il pattern emergente si muove verso una convergenza tra questi due modelli architetturali [Bor20].
Il lakehouse è il nuovo concetto che avvicina i data lake ai data warehouse, rendendoli in grado di competere nel mondo della BI e dell’analisi.
Naturalmente, come per tutte le innovazioni tecniche emergenti, è difficile separare il marketing dal valore tecnologico effettivo che, in ultima analisi, solo il tempo e l’adozione possono dimostrare. E sebbene sia innegabile che il marketing stia svolgendo un ruolo importante nella diffusione del concetto, c’è molto di più in questo concetto rispetto alle semplici buzzword.
Infatti, l’architettura Lakehouse è stata introdotta separatamente e sostanzialmente in parallelo da tre importanti e affidabili aziende, e con tre diverse implementazioni.
Databricks ha pubblicato il paper seminale sui data lake [Zah21], e ha di seguito reso open source Delta Lake [Delta, Arm20].
Parallelamente Netflix, in collaborazione con Apple, ha introdotto Iceberg [Iceberg], mentre Uber ha presentato Hudi [Hudi] (pronunciato “Hoodie”, /ˈhʊdɪ/), entrambi diventati progetti Apache di primo livello nel maggio 2020.
Inoltre, tutte le principali aziende operanti nel mondo dei dati stanno facendo a gara per supportarlo, da AWS a Google Cloud, passando per Dremio, Snowflake e Cloudera, e l’elenco è in continua crescita.
In questo articolo cercherò di spiegare, con un linguaggio schietto, che cos’è una lakehouse, perché sta generando così tanto clamore e perché sta rapidamente diventando il fulcro delle moderne architetture di piattaforme dati.
Cos’è un Lakehouse?
In una sola frase, un lakehouse è un “data lake” con gli steroidi che unifica il concetto di “data lake” e “data warehouse”.
In pratica, il lakehouse sfrutta un nuovo livello di metadati che fornisce un’astrazione del concetto di “tabella” e di alcune funzionalità tipiche dei data warehouse in aggiunta ad un classico Data Lake.
Questo nuovo livello si basa su tecnologie esistenti, in particolare su un formato di file binario, spesso colonnare, che può essere Parquet, ORC o Avro, e su un livello di storage.
Pertanto, i principali elementi costitutivi di una piattaforma lakehouse (vedi figura 1.x), da una prospettiva bottom-up, sono:
- Un layer di archiviazione dei file, generalmente basato su cloud, ad esempio AWS S3 o GCP Cloud Storage o Azure Data Lake Storage Gen2.
- Un formato di file binario come Parquet o ORC utilizzato per memorizzare dati e metadati.
- Il nuovo layer fatto da un formato di file tabellare, quale per esempio Delta Lake, Apache Iceberg o Apache Hudi.
- Un motore di elaborazione che supporti il formato tabellare di cui sopra, ad esempio Spark o Presto o Athena e così via.
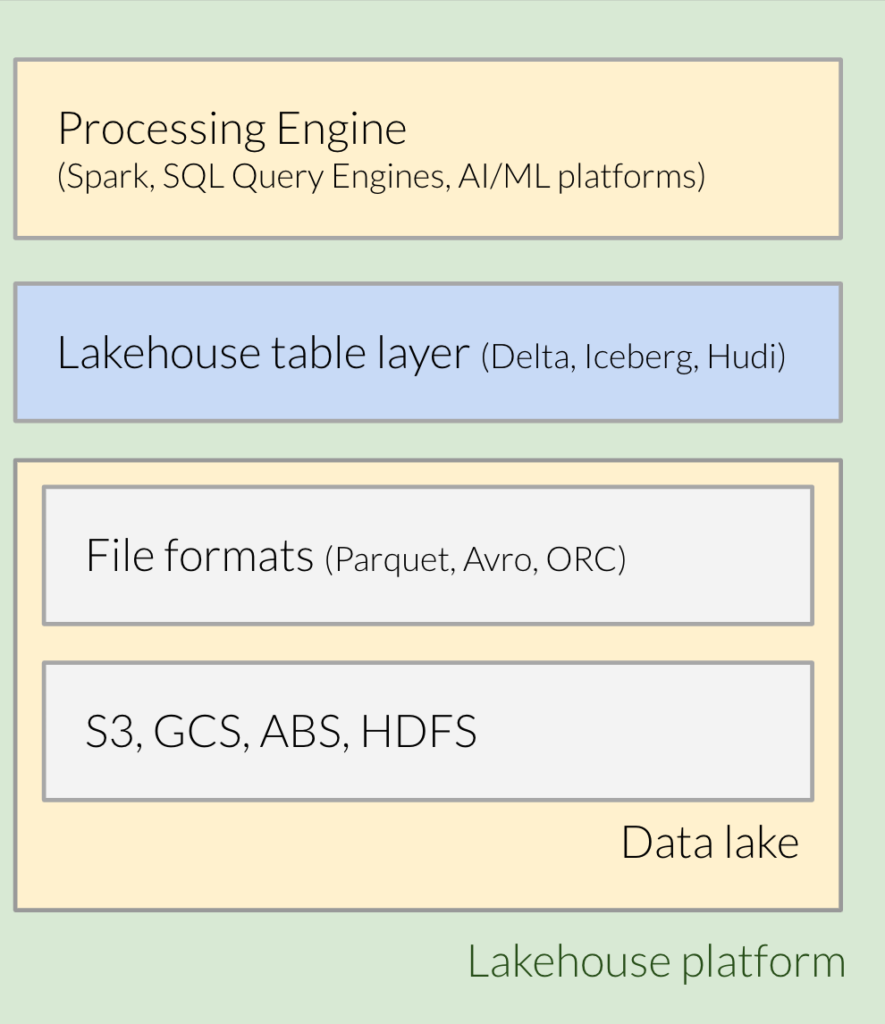
Per comprendere meglio l’idea alla base del lakehouse e l’evoluzione verso di esso, iniziamo con il background.
Prima generazione, il data warehouse
I data warehouse esistono da oltre 40 anni.
Sono stati inventati per rispondere ad alcune domande di business troppo impegnative per i database operazionali e per poter fare il join di dati provenienti da più sorgenti.
L’idea era quella di astrarre i dati dai sistemi operazionali, trasformarli nel formato più adatto a rispondere alle domande e, infine, caricarli su un unico database specializzato. Per inciso, questo processo si chiama ETL (Extract, Transform, Load).
Questo è talvolta anche indicato come la prima generazione.
Per completare il concetto, un data mart è una porzione di data warehouse focalizzata su una specifica linea di business o reparto.
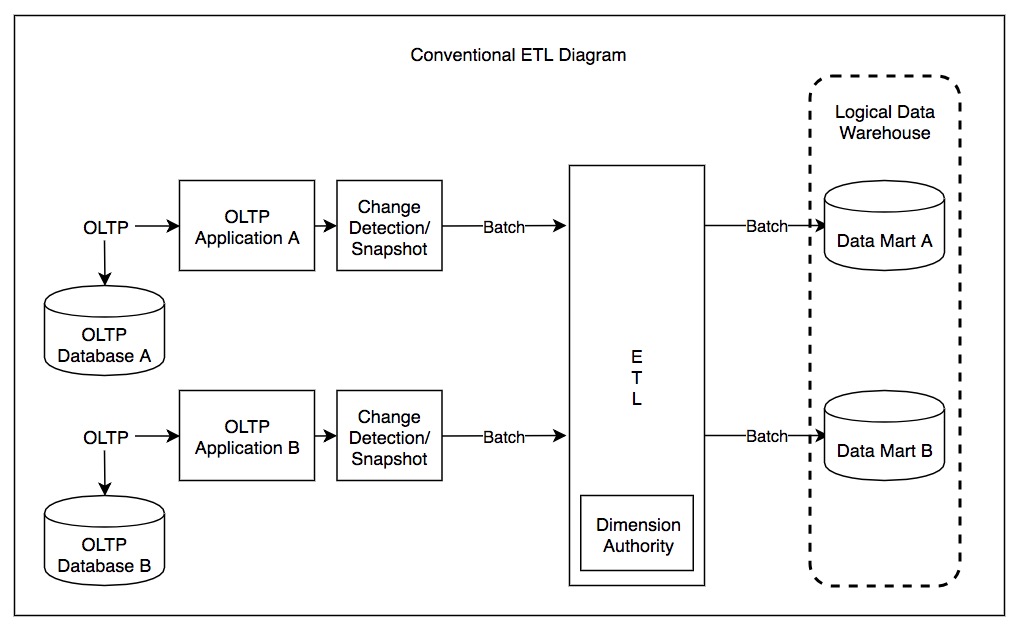
La seconda generazione, i data lake
Il crescente volume di dati da gestire e la necessità di gestire dati non strutturati (immagini, video, documenti di testo, log, ecc.) hanno reso i data warehouse sempre più costosi e inefficienti.
Per superare questi problemi, le piattaforme di analisi dei dati di seconda generazione hanno iniziato a scaricare tutti i dati grezzi nei data lake, sistemi di archiviazione a basso costo che forniscono un’API simile a quella di un filesystem.
I data lake sono nati con Mapreduce e Hadoop (anche se il nome data lake è arrivato più tardi) e sono stati successivamente seguiti da data lake su cloud, come quelli basati su S3, ADLS e GCS.
I data lake sono caratterizzati da uno storage a basso costo, una maggiore velocità e una maggiore scalabilità, ma, d’altro canto, hanno rinunciato a molti dei vantaggi dei data warehouses.
Data Lakes e Warehouses
I data lakes non hanno sostituito i data warehouse: sono stati complementari, ognuno dei due ha risposto a esigenze e casi d’uso diversi. Infatti, inizialmente i dati grezzi venivano importati nei data lake, manipolati, trasformati ed eventualmente aggregati. Quindi, un piccolo sottoinsieme di essi veniva successivamente trasferito a un data warehouse a valle per applicazioni di decision intelligence e BI.
Questa architettura a due livelli di data lake e warehouse è oggi ampiamente utilizzata nel settore, come si può vedere nella figura seguente:
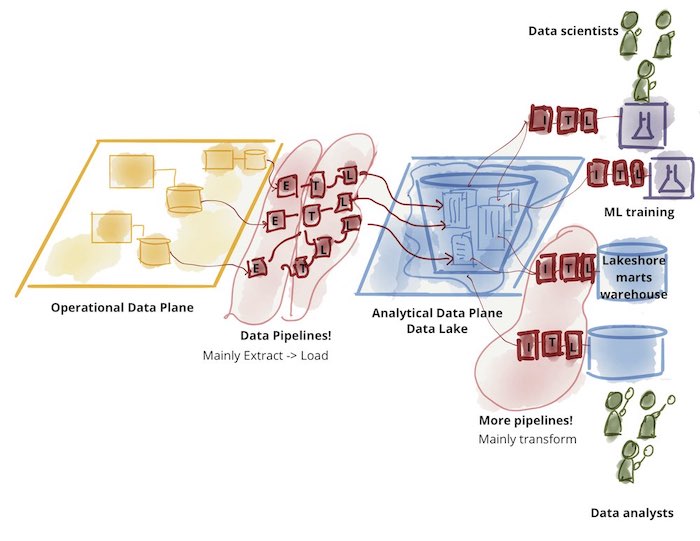
Problemi con le architetture dati a due livelli
Un’architettura a due livelli comporta un’ulteriore complessità e in particolare soffre dei seguenti problemi:
- Affidabilità e ridondanza, poiché più copie degli stessi dati esistono in sistemi diversi e devono essere mantenute disponibili e coerenti tra loro;
- Obsolescenza, in quanto i dati devono essere caricati prima nei data lake e solo successivamente nel data warehouse, introducendo ulteriori ritardi da caricamento iniziale al momento in cui i dati sono disponibili per la BI;
- Supporto limitato per l’AI/ML sui dati di BI: il business richiede sempre più analisi predittive di BI, ad esempio “a quali clienti offrire sconti”. Le librerie AI/ML non supportano i normali datawarehouse, quindi i fornitori spesso suggeriscono di scaricare i dati nei data lake, aggiungendo ulteriori passaggi e complessità alle pipeline.
- I moderni data warehouse stanno aggiungendo un certo supporto per l’AI/ML, ma non sono ancora ideali per gestire i formati binari (video, audio, ecc.).
- Costi: ovviamente, mantenere due sistemi diversi aumenta il costo totale di proprietà, che comprende l’amministrazione, il costo delle licenze, il costo delle competenze aggiuntive.
La terza generazione, il Data Lakehouse
Un data lakehouse è un paradigma architettonico che aggiunge a un data lake un livello di tabelle supportato da file di metadati, al fine di fornire le tradizionali caratteristiche dei DB analitici, come transazioni ACID, versioning dei dati, auditing, indicizzazione, caching e ottimizzazione delle query.
In pratica, può essere considerato un data lake con gli steroidi, una combinazione di data lake e data warehouse.
Questo modello consente di spostare molti dei casi d’uso tradizionalmente gestiti dai data warehouse nei data lake, e semplifica l’implementazione passando da una pipeline a due livelli a una a un solo livello.
Nella figura seguente è riportata una sintesi delle tre diverse architetture.
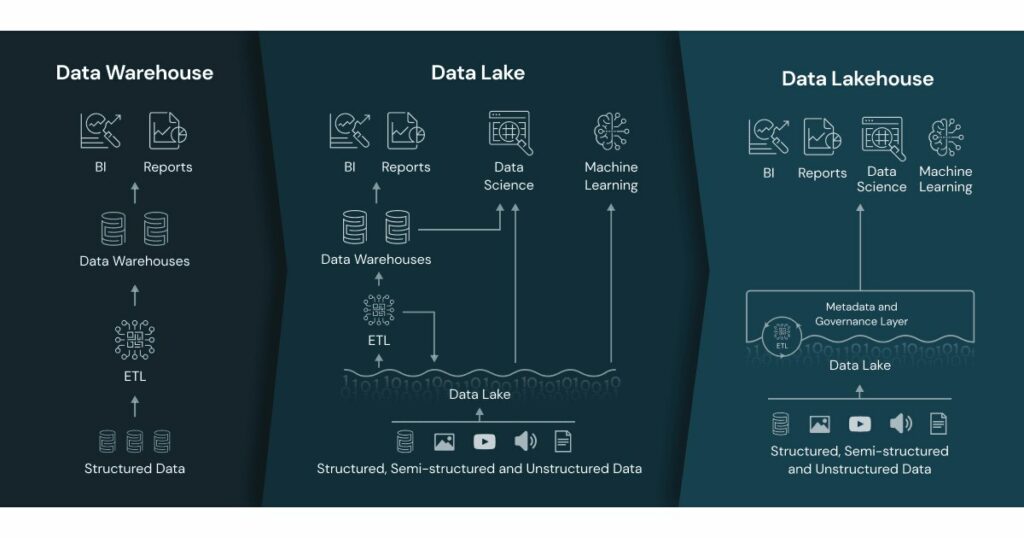
Inoltre, i lakehouse spostano l’implementazione e il supporto delle funzionalità dei data warehouse dal motore di elaborazione al formato di file sottostante. Per questo motivo, sempre più motori di elaborazione sono in grado di sfruttare le nuove funzionalità. In effetti, la maggior parte dei motori sta offrendo un supporto per il formato lakehouse (Presto, Starburst, Athena, …), contribuendo ad aumentare l’hype. I vantaggi per gli utenti sono che l’esistenza di più motori con funzionalità di data warehouse permette di scegliere la soluzione migliore per ogni caso d’uso. Ad esempio, sfruttando Spark per l’elaborazione di dati più generici e per problemi di AI/ML, o Trino/Starburst/Athena/Photon/etc per rapide query SQL.
Charatteristiche del Data Lakehouse
Per chi fosse interessato, approfondiamo (ma non troppo) le caratteristiche fornite dai data lakehouse e il loro ruolo.
ACID
La caratteristica più importante, disponibile in tutte le diverse implementazioni di lakehouse, è il supporto delle transazioni ACID.
ACID, acronimo di atomicità, consistenza, isolamento, durabilità, è un insieme di proprietà delle transazioni su database volte a garantire la validità dei dati nonostante errori, interruzioni di corrente e altri inconvenienti.
In effetti, i cloud object stores non hanno sempre garantito una consistenza forte, per cui era possibile leggere dati non aggiornati (stale reads) – questa è chiamata consistenza eventuale.
In ogni caso, non ci sono garanzie di mutua esclusione, e più scrittori possono aggiornare lo stesso file senza un coordinamento esterno, e non c’è supporto per l’aggiornamento atomico su più chiavi, pertanto gli aggiornamenti che coinvolgono più file possano essere eseguiti in momenti diversi.
Le implementazioni di Lakehouse garantiscono transazioni ACID su una singola tabella, nonostante lo storage sottostante utilizzato e indipendentemente dal numero di file utilizzati.
Questo obiettivo viene raggiunto in modi diversi dai tre principali player, ma in generale tutti utilizzano file di metadati per identificare quali file fanno parte di un’istantanea della tabella e un file di tipo di log chiamato write-ahead-log (WAL) per tenere traccia di tutte le modifiche applicate ad una tabella.
Si noti che esistono modi alternativi per garantire consistenza ACID, in particolare utilizzando uno storage esterno per i metadati avente consistenza ACID, come un DB esterno. Questo è ciò che fa HIVE 3 ACID, ad esempio, o Snowflake. Tuttavia, il fatto di non dover dipendere da un sistema esterno elimina un collo di bottiglia, un single point of failure e consente a più motori di elaborazione di sfruttare la stessa struttura dei dati.
Partizionamento
Il partizionamento automatico è un’altra caratteristica fondamentale, utilizzata per ridurre i requisiti di processamento delle query e semplificare la manutenzione delle tabelle. Questa funzione è implementata partizionando i dati in più cartelle e, sebbene possa essere facilmente implementata a livello applicativo, è fornita in modo trasparente dal lakehouse. Inoltre, alcuni lakehouse (vedi Iceberg) possono supportare automaticamente il partition evolution, ovvero l’evoluzione dello schema usato per il partizionamento, alla stregua dello schema evolution.
Time Travel
Il time-travel (viaggio nel tempo in italiano) è la possibilità di interrogare/ripristinare una tabella a uno stato precedente nel tempo.
Ciò si ottiene mantenendo i metadati contenenti snapshot di informazioni per periodi di tempo più lunghi.
Il time travel è una caratteristica fornita anche dai DB tradizionali orientati ai workload di tipo OLAP, in quanto questa funzione può essere implementata facendo affidamento sui write-ahead logs. In effetti era disponibile anche in Postgres DB, ad esempio, fino alla versione 6.2, e in SQL Server. La separazione tra archiviazione ed elaborazione rende questa funzionalità più facile da supportare nei lakehouse facendo affidamento su uno storage sottostante a basso costo.
Naturalmente, per ridurre i costi e l’utilizzo dello spazio di storage, si potrebbe voler ripulire periodicamente i metadati piu’ vecchi, in modo da poter tornare indietro nel tempo fino al più vecchio snapshot disponibile.
Schema Evolution ed Enforcement
Iceberg, Delta e Hudi si basano su formati di file binari (Parquet/ORC/Avro), compatibili con la maggior parte dei framework di elaborazione dati.
Lakehouse fornisce un ulteriore livello di astrazione che consente l’evoluzione dello schema in-place, una mappatura tra gli schemi dei file sottostanti e lo schema delle tabelle, in modo che l’evoluzione dello schema possa essere effettuata in-place, senza riscrivere l’intero set di dati.
Supporto per lo streaming
I Data Lake non sono adatti alle applicazioni di streaming per diversi motivi: per citarne alcuni, i servizi di cloud storage non permettono di aggiungere dati ai file, per esempio, non a lungo non hanno forniscono una vista consistente dei file scritti, ecc. Eppure si tratta di un’esigenza comune e, per esempio, l’offload dei dati di Kafka su uno storage layer una parte fondamentale dell’architettura lambda.
Gli ostacoli principali sono rappresentati dal fatto che gli object store non offrono una funzione di “append” o una vista consistente su più file.
I Lake House consentono di utilizzare le loro tabelle sia come input che come output. Questo risultato è ottenuto grazie a un livello di astrazione che maschera l’uso di file multipli e a un processo di compressione in background che unisce i file piccoli, oltre a “Exactly-Once Streaming Writes” e “efficient log tailing”. Per i dettagli si veda [Arm20].
La grande convergenza
Le piattaforme basate su lake house elimineranno completamente i data warehouse? Credo che sia improbabile. Quello che è certo al momento è che i confini tra le due tecnologie stanno diventando sempre più labili.
Infatti, mentre i data lake, grazie a Delta Lake, Apache Iceberg e Apache Hudi si stanno spostando nel territorio dei data warehouse, è vero anche il contrario.
Infatti, Snowflake ha aggiunto il supporto per il il formato di metadati del lakehouse (Apache Iceberg/Delta al momento in cui scriviamo), diventando uno dei possibili motori di elaborazione che supportano tale formato.
Allo stesso tempo, i data warehouse si stanno muovendo verso le applicazioni AI/ML, tradizionalmente monopolio dei data-lake: Snowflake ha rilasciato Snowpark, una libreria Python di AI/ML che permette di scrivere pipeline di dati e workflow di ML direttamente in Snowflake. Naturalmente ci vorrà un po’ di tempo prima che la comunità dei data scientist accetti e padroneggi un’altra libreria, ma la direzione è segnata.
L’aspetto interessante è che i data warehouse ed i data lake stanno diventando sempre più simili: entrambi si basano su commodity storage, offrono uno scaling orizzontale nativo, supportano tipi di dati semi-strutturati, transazioni ACID, query SQL interattive e così via.
Riusciranno a convergere al punto da diventare intercambiabili negli stack di dati? È difficile dirlo e gli esperti hanno opinioni diverse: anche se la direzione è innegabile, le differenze nei linguaggi, nei casi d’uso o persino nel marketing giocheranno un ruolo importante nel definire l’aspetto dei futuri data stack. In ogni caso, si può affermare con sicurezza che il lakehouse è qui per restare.
Riferimenti
- [Bor20] Matt Bornstein, Jennifer Li, and Martin Casado, Emerging Architectures for Modern Data Infrastructure, 2020, online article, https://future.com/emerging-architectures-modern-data-infrastructure/
- [Zah21] Matei Zaharia, Ali Ghodsi 0002, Reynold Xin, Michael Armbrust, Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, in 11th Conference on Innovative Data Systems Research, CIDR 2021, Virtual Event, January 11-15, 2021, Online Proceedings. www.cidrdb.org, 2021.
- [Delta] Delta Lake – https://delta.io/
- [Arm20] Michael Armbrust et al., Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores, PVLDB, 13(12):3411-3424, 2020.
- [Iceberg] Apache Iceberg – https://iceberg.apache.org/
- [Hudi] Apache Hudi – https://hudi.apache.org/
- [Postgresql] Time Travel – https://www.postgresql.org/docs/6.3/c0503.htm
- [Microsoft Learn] Temporal tables – https://learn.microsoft.com/en-us/sql/relational-databases/tables/temporal-tables?view=sql-server-ver16
Autore: Antonio Barbuzzi, Head of Data, AI & ML Engineering @ Bitrock
