

Visione e Offerta
In questo blog post presentiamo la vision e l’offerta di Bitrock nell’area Data, AI & ML Engineering. Forniremo una panoramica dell’attuale scenario dei dati, delimiteremo il contesto in cui ci concentriamo e operiamo e definiremo la nostra proposta.
Questa prima parte descrive il panorama tecnico e culturale del mondo dei dati e dell’IA, con particolare attenzione alle tendenze del mercato e della tecnologia. La seconda parte, che definisce la nostra visione e la nostra offerta tecnica, è disponibile qui.
Un’Esplosione Cambriana
Il panorama dei dati e dell’IA è in rapida evoluzione, con forti investimenti nell’infrastruttura dei dati e un crescente riconoscimento dell’importanza dei dati e dell’IA nel guidare la crescita del business.
Secondo le stime di Gartner 2021, gli investimenti nella gestione dei dati hanno superato i 70 miliardi di dollari [Expert Market Research 2022], rappresentando oltre un quinto di tutte le infrastrutture aziendali spese nel 2021.
Questa tendenza è tangibile anche nel mercato del lavoro: infatti, i data scientist, i data engineer e i machine learning engineer sono elencati da Linkedin tra i ruoli in più rapida crescita a livello globale (LinkedIn 2022).
E questa tendenza non sembra destinata a rallentare. Secondo (McKinsey 2022), entro il 2025 le organizzazioni faranno leva sui dati per ogni decisione, interazione e processo, orientandosi verso l’elaborazione in tempo reale per ottenere approfondimenti più rapidi e potenti.
Questa crescita si riflette anche nel numero di strumenti, applicazioni e aziende in questo settore, e da quella che viene generalmente chiamata “esplosione cambriana”, paragonando questa crescita all’esplosione di forme di vita diverse durante il periodo Cambriano, quando apparvero molti nuovi tipi di organismi in un lasso di tempo relativamente breve. Questo è chiaramente rappresentato nella figura seguente, basata su (Turk 2021).
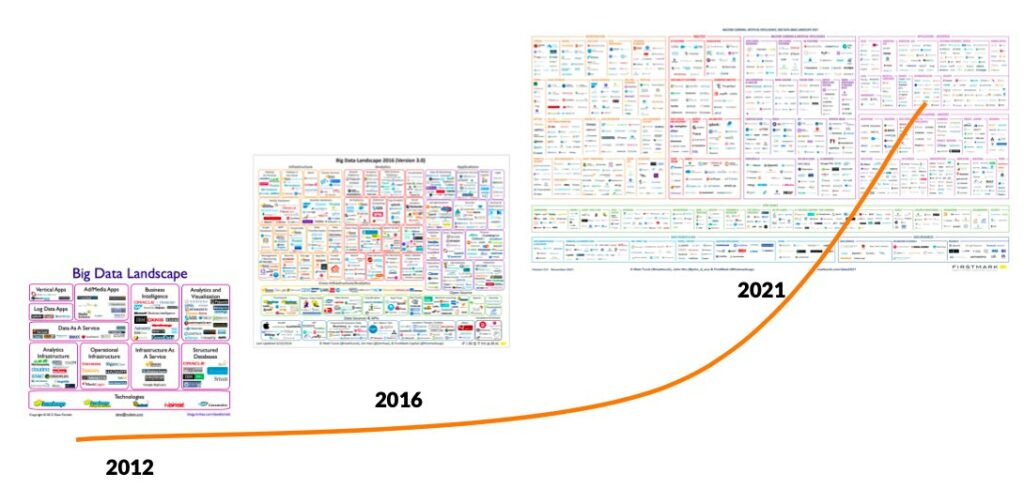
Lo Scenario Tecnologico
Le architetture di dati hanno due obiettivi principali: aiutare l’azienda a prendere decisioni migliori sfruttando e analizzando i dati – il cosiddetto piano analitico – e fornire informazioni alle applicazioni rivolte ai clienti – il cosiddetto piano operativo.
Questi due casi d’uso hanno portato a due diverse architetture ed ecosistemi intorno ad esse: i sistemi analitici, basati su data warehouse, e i sistemi operativi, basati su data lake.
I primi, basati su data warehouse, sono cresciuti rapidamente. Sono incentrati sulla Business Intelligence, sugli utenti e sugli business analyst, in genere aventi familiarità con il linguaggio SQL. I datawarehouse su cloud, come Snowflake, guidano questa crescita; il passaggio dall’on-premise al cloud è a questo punto inarrestabile.
Anche i sistemi operazionali sono cresciuti. Sono basati su data lake; la loro crescita è guidata dal modello emergente di lakehouse e dall’enorme interesse per l’AI/ML. Sono specializzati nel trattamento di dati non strutturati e strutturati, e supportano anche casi d’uso di BI.
Da qualche anno è emerso un percorso verso la convergenza di entrambe le tecnologie. I data lake hanno aggiunto transazioni ACID e funzionalità di datawarehousing ai data lake, mentre i data warehouse sono diventati capaci di gestire dati non strutturati e carichi di lavoro AI/ML. In ogni caso, i due ecosistemi sono ancora molto diversi e non è detto che in futuro possano convergere.
Per quanto riguarda l’ingestion e la trasformazione, c’è un chiaro spostamento architetturale dall’ETL all’ELT (cioè i dati vengono prima ingeriti e poi trasformati). Questa tendenza, resa possibile dalla separazione tra storage e computing portata dal cloud, è ulteriormente spinta dall’ascesa delle tecnologie CDC e dalla promessa di fare outsource degli aspetti non business a sistemi esterni.
In questo contesto Fivetran/DBT spiccano nel mondo analitico (insieme a nuovi attori come Airbyte/Matillion), mentre Databricks/Spark, Confluent/Kafka e Astronomer/Airflow sono gli standard de-facto nel mondo operativo.
È inoltre degno di nota l’aumento dell’uso dello stream processing per l’analisi dei dati in tempo reale. Ad esempio, l’uso di prodotti di stream processing di aziende come Databricks e Confluent ha preso piede.
Anche i temi relativi all’intelligenza artificiale (AI) stanno prendendo piede e Gartner, nel suo rapporto annuale sui trend tecnologici strategici (Gartner 2021), indica Decision Intelligence, AI Engineering, Generative AI come priorità per accelerare la crescita e l’innovazione.
La Decision Intelligence prevede l’uso dell’apprendimento automatico, dell’elaborazione del linguaggio naturale e della modellazione delle decisioni per estrarre informazioni e informare il processo decisionale. Secondo il rapporto, nei prossimi due anni un terzo delle grandi organizzazioni la utilizzerà come vantaggio competitivo.
L’AI Engineering si concentra sull’operatività dei modelli di AI per integrarli nel ciclo di vita dello sviluppo del software e renderli robusti e affidabili. Secondo gli analisti di Gartner, genererà un valore tre volte superiore rispetto alla maggior parte delle imprese che non la utilizzano.
L‘IA generativa è uno degli esempi più interessanti e potenti di IA. Apprende il contesto dai dati di formazione e lo utilizza per generare artefatti nuovi, completamente originali e realistici. Secondo Gartner, entro il 2025 rappresenterà il 10% di tutti i dati prodotti.
Cultura dei Dati e Democratizzazione
Nonostante l’evidente importanza dei dati, è esperienza comune che molte iniziative sui dati falliscano. Gartner ha stimato che l’85% dei progetti sui big data fallisce (O’Neill 2019) e che nel 2022 solo il 20% degli insight analitici produrrà risultati di business (White 2019).
Cosa va storto? Raramente i problemi risiedono nell’inadeguatezza delle soluzioni tecniche. I problemi tecnici sono probabilmente i più semplici. Infatti, da dieci anni a questa parte, le tecnologie si sono evolute in modo estremamente rapido e le tecnologie Big Data sono maturate molto. Più spesso, i problemi sono piuttosto culturali.
Non è un mistero che un data lake di per sé non fornisca alcun valore aziendale. Raccogliere, archiviare e gestire i dati è un costo. I dati diventano (incredibilmente) preziosi quando vengono utilizzati per produrre conoscenza, insights, azioni. Per far sì che la cosa sia possibile, i dati devono essere accessibili e disponibili a tutti in azienda. In altre parole, le organizzazioni dovrebbero investire in una cultura data-driven a livello aziendale e puntare a una vera e propria democratizzazione dei dati.
I dati devono essere considerati una risorsa strategica che viene valorizzata e sfruttata in tutta l’organizzazione. I manager, a partire dai C-level, dovrebbero rimuovere gli ostacoli e creare le condizioni per l’accesso ai dati da parte delle persone che ne hanno bisogno, eliminando gli ostacoli, i colli di bottiglia e semplificando i processi.
La creazione di una cultura dei dati e la loro democratizzazione consente alle organizzazioni di sfruttare appieno le loro risorse di dati e di fare un uso migliore degli approfondimenti basati sui dati. Dando ai dipendenti la possibilità di utilizzare i dati, le organizzazioni possono migliorare il processo decisionale, promuovere l’innovazione e stimolare la crescita aziendale.
Infine, ma non meno importante, la potenza dei Big Data non cancella la necessità di una visione o di un’intuizione umana (Waller 2020). È fondamentale avere in mente una strategia dei dati per definire come l’azienda deve utilizzare i dati e il collegamento con la strategia aziendale. E, naturalmente, un coinvolgimento e un impegno da parte di tutti i livelli manageriali, a partire dal vertice.
La seconda parte di questo articolo è disponibile qui
Riferimenti
- Expert Market Research. 2022. “Enterprise Data Management Market Size, Share, Price, Demand 2023-2028.” Expert Market Research. https://www.expertmarketresearch.com/reports/enterprise-data-management-market.
- Gartner. 2021. “Gartner Identifies the Top Strategic Technology Trends for 2022.” Gartner. https://www.gartner.com/en/newsroom/press-releases/2021-10-18-gartner-identifies-the-top-strategic-technology-trends-for-2022.
- Gartner. 2021. “Forecast: Enterprise Infrastructure Software, Worldwide, 2019-2025, 4Q21 Update.” Gartner. https://www.gartner.com/en/documents/4009669.
- LinkedIn. 2022. “The Fastest-Growing Jobs Around the World.” LinkedIn. https://www.linkedin.com/business/talent/blog/talent-strategy/fastest-growing-jobs-global.
- McKinsey. 2022. “The data-driven enterprise of 2025.” McKinsey. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-data-driven-enterprise-of-2025.
- O’Neill, Brian T. 2019. “Failure rates for analytics, AI, and big data projects = 85% – yikes!” Designing for Analytics. https://designingforanalytics.com/resources/failure-rates-for-analytics-bi-iot-and-big-data-projects-85-yikes/.
- Turk, Matt. 2021. “Red Hot: The 2021 Machine Learning, AI and Data (MAD) Landscape.” Matt Turck. https://mattturck.com/data2021/
- Waller, David. 2020. “10 Steps to Creating a Data-Driven Culture.” Harvard Business Review. https://hbr.org/2020/02/10-steps-to-creating-a-data-driven-culture.
Autore: Antonio Barbuzzi, Head of Data, AI & ML Engineering @ Bitrock