

Vision & Offering
This is the second part of our article which introduces Bitrock’s vision and offering in the Data, AI & ML Engineering area. The first part delimits the context where we focus and operate, while this one defines our vision and the proposition that follows.
Vision
Artificial Intelligence (AI) is shaping the future of mankind in nearly all industries, and it is driving advancements in heterogeneous fields such as big data, robotics, and Internet of Things. We have a strong conviction that AI will continue to be a driving force of innovation and progress in the future. As a company, we recognize the vital importance of AI and ML for organizations to not just survive but thrive in the market.
That’s why we’re committed to providing our customers with the platform, tools, and expertise to harness the full potential of AI and help them create innovative solutions, helping them with operationalization of robust and reliable AI-based solutions, and we tailor our offering to meet the needs of customers in this field.
AI/ML is the last piece of the puzzle, the last stretch in a race. It needs strong pillars to build upon: a reliable and scalable data platform, designed to evolve and not just for latest delivery, where security and governance are central, with automatic tests, continuous integration/deployment in place. Indeed, for data even more so, the motto “garbage-in, garbage-out” is valid.
Data platforms should be tailored to the customer needs: there is no one-size-fit-all approach to data engineering problems, rather there are companies, customers, partners with different backgrounds and needs requiring different solutions. Paraphrasing Maslow’s hammer, not everything is a nail and can be pounded using a hammer.
We believe in bespoke solutions for our clients, driving them through the intricacies of the current data landscape, and designing the platform better fitting their existing infrastructure and needs.
Our ambition is also to help our clients to define a clear and effective data strategy that aligns with the overall business objective. Organizations should define goals, processes and business targets; provide data governance framework and processes balancing security, privacy concerns and simplifying the process to discover, access and use data.
In order to provide the best services, we value our partnerships: as of today, we’re partners with Databricks, Confluent and HashiCorp.
Design Principles
Our solutions follow specific design principles, driving our choices and design:
Cloud first
Cloud first means prioritizing cloud over on-premise solutions. In other words, having to justify picking on-premise solutions rather than making a case for cloud ones.
We’re aware of the reluctance of some companies towards cloud solutions: nevertheless, nowadays there are still very few reasons to not embrace cloud. The advantages provided by the cloud are too many: faster time to market, easy scaling, no upfront license/hardware costs, lower operative cost. Basically, it allows us to outsource non-core processes and focus on what matters the most to the business.
ML/AI from the beginning
Machine Learning (ML) and Artificial Intelligence (AI) have witnessed a tremendous leap forward in the latest years, mainly due to the increased availability of computing resources (faster GPUs, bigger memories) and data. Artificial intelligence has reached or surpassed human-level performances in many complex tasks: autonomous driving is now a reality and social networks use ML profusely to detect harmful content and target advertisements, while generative networks such as OpenAI’s GPT-3 or Google’s Imagen could be game changers in the quest toward artificial general intelligence (AGI).
AI/ML is no longer the future to look at, it’s the present.
Some organizations will use it as a competitive advantage over its competitors; others will see it as a homework to keep up and remain competitive on the market. For sure, no one can really afford to ignore it anymore (or maybe just monopolies and the public administration?).
AI and ML have a central role in our vision and shape our architectural and technological choices.
In this context, continuously interpreting data, discovering patterns and making timely decisions based on historical and real-time data, the so-called Continuous Intelligence, will play a crucial role in defining the business strategies and will be one of the most widespread applications of machine learning. Indeed, Gartner estimates that, within 3 years, more than 50% of all business initiatives will require continuous intelligence and, by 2023, more than one-third of enterprises will have analysts practising decision intelligence, including decision modelling.
MLOps and AI Engineering
MLOps, or Machine Learning Operations, is a field in the ML community that is rapidly gaining momentum. It advocates for the need to manage the ML lifecycle following software-inspired best practices and DevOps philosophy. This approach aims to make ML-powered software reproducible, testable, and evolvable, ensuring that models are deployed and updated in a controlled and efficient manner. The importance of MLOps lies in the ability to improve the speed and reliability of ML model deployment, while reducing the risk of errors and improving the overall performance of models.
Data democratization
We’ve already underlined the importance of data democratization. Achieving it requires several key elements to be in place. Firstly, it requires a data culture where data is seen as a strategic asset valued and leveraged throughout the company. This requires a buy-in and commitment from top management.
A widespread access to data urges for a widespread adoption of more robust Data Governance solutions, with data discoverability features, to effectively manage complex data processes and make data available and usable by everybody in need.
Making data accessible means also lowering the entry-barrier to it, and therefore providing more user-friendly platforms, which can be usable in autonomy, without advanced knowledge (the so-called self-service platform).
Data Mesh is an approach oriented towards large-scale environments, going in this direction. It addresses silos and bottlenecks in large companies and emphasises the decentralization of data ownership, moving data ownership to the business domain teams.
Data mesh is an approach which increases overall complexity and introduces new challenges in organizations adopting it, but it may help them when scalability and data silos effectively represent an entry barrier to a company-wide data usage.
Reference Architecture
We at Bitrock refrain from providing a one-size-fit-all solution; we rather provide a reference data architecture modelled after technology stacks used across multiple companies, updated with more recent innovations.
We focus on a Multimodal data processing architecture, specialized in AI/ML and operational use-cases, able to support analytical needs typical of data warehouses. As previously explained, this is an alternative to a Business Intelligence oriented alternative, based on data warehouses.
At the core of the system there are the concepts of data lake and data lakehouse.
A data lake is a centralised repository that allows you to store and manage all your structured and unstructured data at any scale. They are traditionally oriented towards advanced data processing of operational data and ML/AI. The data lakehouse concept adds to them a robust storage layer paired with a processing engine (spark, presto, …) to enhance it with data-warehousing capabilities, making data lakes suitable for analytical workloads too.
There is growing recognition for this architecture, which is supported by a wide range of vendors, including Databricks AWS, Google Cloud, Starburst, and Dremio – and by data warehouses vendors like Snowflake too.
For a more detailed introduction to it, please refer to a previous article on our Blog (Data Lakehouse, beyond the hype).
Our processing engine of choice is Apache Spark, which is the de-facto standard for operational workloads – paired with the battle-tested and reliable Apache Airflow or Astronom, a SaaS version. In the orchestration world, Dagster or Prefect are alternatives to Airflow which are gaining a lot of traction. They foster a switch to a higher-level abstraction, from managing workflow to handling dataflows.
Spark is suitable for both batch and real-time workloads, but for real-time data processing Apache Flink and Kafka Streams may be good alternatives, especially for applications with more stringent latency requirements.
In the streaming world applied to AI and ML, another option is Helicon from Radicalbit, which is a solution aimed at reducing the gap between data scientist and data engineering using a no-code/low-code approach. There’s a revived interest in the no-code/low-code solutions, which are ringing new users (i.e. analysts and software developers) into the ML market, pushed by new low code ML solutions like Databricks AutoML, H2O, Datarobot, etc.
Quick data exploration may be achieved by either the use of ad-hoc query engines like Trino/Presto/Starburst/Databricks SQL or using notebooks like Jupyter or their managed versions.
The integration is the boring homework preceding the fun part. However, it represents the largest fraction of cost of most data projects, ranging from 20-30% on average up to 70% for some pessimistic cases.
From a technical point of view, the injection layer is quite diversified and it is generally shaped following the organization’s data sources and infrastructure.
Traditionally, data is extracted from operational data sources and transformed before being loaded into a data warehouse, the so called ETL. Cheap cloud storage and the separation of storage and computing laid the foundation for a paradigm shift advocating the anticipation of the loading phase before the transformation phase (ELT). This pattern, actually not totally new for data lakes, shines as it removes the business logic from loading phase in the injection layer, making it possible to simplify the integration by outsourcing it.
Fivetran, along with Airbyte, Matillion and many others, are examples of ELT tools. Strictly speaking, ETL term usually is generally used more in data-warehousing context, however those integration tools are beneficial to lakes and lakehouse architectures too: Fivetran has recently become a partner of Databricks too for example.
In the injection layer, Confluent is also playing a more and more important role with Kafka Connectors, allowing it to pull (and push too) data from a variety of sources. The pair Kafka and CDC (Change Data Capture), with software like Debezium/Qlik/Fivetran, is a more and more common integration pattern used in this context.
The following figure, based on the unified data platform from Horowitz (Bornstein, Li, and Casado 2020), exemplifies our architecture, in particular the boxes highlighted in yellow:
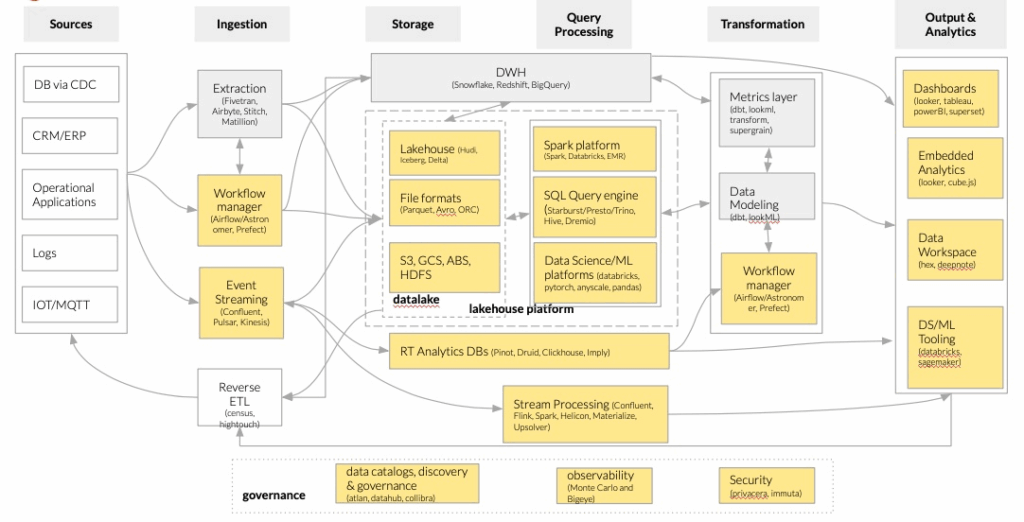
Emerging architectures for modern data infrastructures
ML-platform
A central role in our platform is reserved to the operationalization of ML models and AI-based software.
MLOps, or Machine Learning Operations, is a rapidly growing field in the ML community that advocates for the need to manage the ML lifecycle following software-inspired best practices and DevOps philosophy. This approach aims to make ML-powered software reproducible, testable, and evolvable, ensuring that models are deployed and updated in a controlled and efficient manner. The importance of MLOps lies in the ability to improve the speed and reliability of ML model deployment, while reducing the risk of errors and improving the overall performance of models. Our idea of a generic platform for machine learning providing all the tools to operationalize ML lifecycle is best described by the following figure, based on (Bornstein, Li, and Casado 2020).
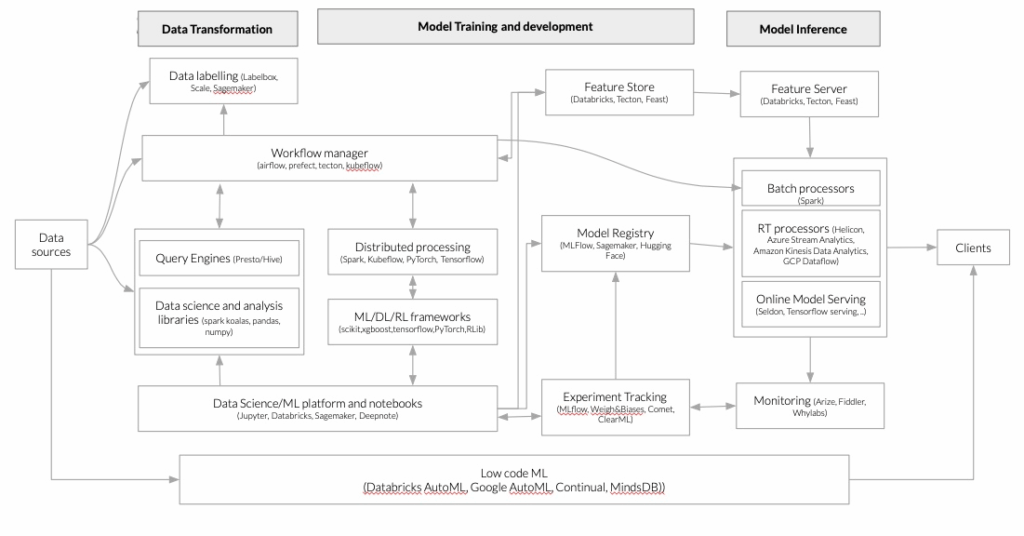
Emerging architectures for modern data infrastructures
Conclusions
We believe AI and ML are crucial for any organization and will be fundamental to succeed and thrive in the market.
Bitrock is committed to providing customers with the platform, tools, and expertise to harness the full potential of Artificial Intelligence (AI) and Machine Learning (ML) and operationalize it through AI engineering and MLOps.
We tailor our offering to meet the unique needs of our customers and believe in providing bespoke solutions for our clients. Our ambition is to jointly define a clear and effective data strategy that aligns with their overall business objectives.
If you have any questions, doubts or just want to discuss data-related topics, please feel free to get in touch: we’d be more than happy to help or just chat!
References
- Barbuzzi, Antonio. 2022. “Data Lakehouse, beyond the hype” Bitrock.
- Bornstein, Matt, Jennifer Li, and Martin Casado. 2020. “Emerging Architectures for Modern Data Infrastructure.” Andreessen Horowitz. https://future.com/emerging-architectures-modern-data-infrastructure/.
Author: Antonio Barbuzzi, Head of Data, AI & ML Engineering @Bitrock