

Visione & Offerta
Questa è la seconda parte del nostro articolo che introduce la vision e l’offerta di Bitrock nell’area Data, AI & ML Engineering. La prima parte delimita il contesto in cui ci concentriamo e operiamo, mentre questa definisce la nostra vision e la proposta che segue.
Visione
L‘Intelligenza Artificiale (AI) sta plasmando il futuro dell’umanità in quasi tutti i settori e sta guidando i progressi in campi eterogenei come i Big Data, la robotica e l’Internet of Things. Siamo fortemente convinti che l’AI continuerà a essere una forza trainante dell’innovazione e del progresso in futuro. Come azienda, riconosciamo l’importanza vitale dell’AI e del ML per le organizzazioni, non solo per sopravvivere ma anche per prosperare sul mercato.
Per questo motivo ci impegniamo a fornire ai nostri clienti la platform, gli strumenti e le competenze per sfruttare tutto il potenziale dell’AI e aiutarli a creare soluzioni innovative, aiutandoli nell’operatività di soluzioni robuste e affidabili basate sull’AI e adattando la nostra offerta alle esigenze dei clienti in questo campo.
L’AI/ML è l’ultimo pezzo del puzzle, l’ultimo tratto di una corsa. Ha bisogno di pilastri solidi su cui basarsi: una piattaforma dati affidabile e scalabile, progettata per evolversi e non solo per l’ultima delivery, dove la sicurezza e la governance sono centrali, con test automatici e CI/CD. In effetti, a maggior ragione per i dati, vale il motto “garbage-in, garbage-out”.
Le piattaforme di dati devono essere adattate alle esigenze del cliente: non esiste un approccio unico ai problemi di Data Engineering, ma esistono aziende, clienti e partner con background ed esigenze diverse che richiedono soluzioni diverse. Parafrasando il martello di Maslow, non tutto è un chiodo e può essere affrontato solo con un martello.
Crediamo nelle soluzioni su misura per i nostri clienti, guidandoli attraverso le complessità dell’attuale panorama dei dati e progettando la piattaforma più adatta all’infrastruttura e alle esigenze esistenti.
La nostra ambizione è anche quella di aiutare i nostri clienti a definire una data strategy chiara ed efficace che si allinei con gli obiettivi aziendali generali. Le organizzazioni devono definire obiettivi, processi e target aziendali; fornire un quadro di governance dei dati e processi che bilancino sicurezza e privacy e semplifichino il processo di scoperta, accesso e utilizzo dei dati.
Per fornire i migliori servizi, diamo valore alle nostre partnership: ad oggi, siamo partner di Databricks, Confluent e HashiCorp.
Design Principles
Le nostre soluzioni seguono principi di progettazione specifici, che guidano le nostre scelte e il nostro design:
Cloud first
Cloud first significa dare priorità al cloud rispetto alle soluzioni on-premise. In altre parole, dover motivare la scelta di soluzioni on-premise piuttosto che fare un caso per quelle cloud.
Siamo consapevoli della riluttanza di alcune aziende nei confronti delle soluzioni cloud: tuttavia, al giorno d’oggi ci sono ancora pochi motivi per non abbracciare il cloud. I vantaggi offerti dal cloud sono troppi: time to market più rapido, facilità di scalabilità, nessun costo iniziale di licenza/hardware, costi operativi inferiori. In sostanza, ci permette di esternalizzare i processi non essenziali e di concentrarci su ciò che conta di più per l’azienda.
ML/AI dall’inizio
Il Machine Learning (ML) e l’intelligenza artificiale (AI) hanno registrato un enorme balzo in avanti negli ultimi anni, soprattutto grazie alla maggiore disponibilità di risorse di calcolo (GPU più veloci, memorie più grandi) e di dati. L’intelligenza artificiale ha raggiunto o superato le prestazioni umane in molti compiti complessi: la guida autonoma è ormai una realtà e i social network utilizzano abbondantemente l’intelligenza artificiale per individuare contenuti dannosi e pubblicità mirate, mentre le reti generative come GPT-3 di OpenAI o Imagen di Google potrebbero cambiare le carte in tavola nella ricerca dell’intelligenza artificiale generale (AGI).
L’AI/ML non è più il futuro a cui guardare, ma il presente.
Alcune organizzazioni la useranno come vantaggio competitivo rispetto alla concorrenza; altre la vedranno come un compito a casa per tenere il passo e rimanere competitive sul mercato. Di sicuro, nessuno può più permettersi di ignorarlo (o forse solo i monopoli e la pubblica amministrazione?).
L’AI e il ML hanno un ruolo centrale nella nostra visione e condizionano le nostre scelte architettoniche e tecnologiche.
In questo contesto, l’interpretazione continua dei dati, la scoperta di modelli e la presa di decisioni tempestive basate su dati storici e in tempo reale, la cosiddetta Continuous Intelligence, giocherà un ruolo cruciale nella definizione delle strategie aziendali e sarà una delle applicazioni più diffuse del machine learning. Infatti, Gartner stima che, entro 3 anni, più del 50% di tutte le iniziative aziendali richiederà la Continuous Intelligence e, entro il 2023, più di un terzo delle imprese avrà analisti che praticano la Decision Intelligence, compreso il Decision Modelling.
MLOps e AI Engineering
L’MLOps, o Machine Learning Operations, è un settore della comunità ML che sta rapidamente prendendo piede. Sostiene la necessità di gestire il ciclo di vita del ML seguendo le best practice ispirate al software e la filosofia DevOps. Questo approccio mira a rendere il software di ML riproducibile, testabile ed evolvibile, garantendo che i modelli siano distribuiti e aggiornati in modo controllato ed efficiente. L’importanza di MLOps risiede nella capacità di migliorare la velocità e l’affidabilità della distribuzione dei modelli di ML, riducendo al contempo il rischio di errori e migliorando le prestazioni complessive dei modelli.
Data Democratization
Abbiamo già sottolineato l’importanza della data democratization. Per ottenerla è necessario che siano presenti diversi elementi chiave. In primo luogo, è necessaria una cultura dei dati che li consideri un bene strategico valutato e sfruttato in tutta l’azienda. Ciò richiede il coinvolgimento e l’impegno del top management.
Un accesso diffuso ai dati richiede l’adozione di soluzioni di Data Governance più robuste, con funzionalità di scoperta dei dati, per gestire efficacemente i processi complessi e rendere i dati disponibili e utilizzabili da chiunque ne abbia bisogno.
Rendere i dati accessibili significa anche abbassare la barriera d’ingresso ad essi, e quindi fornire piattaforme più user-friendly, che possono essere utilizzate in autonomia, senza conoscenze avanzate (la cosiddetta piattaforma self-service).
Data Mesh è un approccio orientato agli ambienti su larga scala, che va in questa direzione. Affronta i silos e i colli di bottiglia delle grandi aziende e pone l’accento sul decentramento della proprietà dei dati, spostando la proprietà dei dati ai team del dominio aziendale.
Il Data Mesh è un approccio che aumenta la complessità complessiva e introduce nuove sfide nelle organizzazioni che lo adottano, ma può aiutarle quando la scalabilità e i silos di dati rappresentano effettivamente una barriera all’ingresso nell’utilizzo dei dati a livello aziendale.
Architettura di riferimento
Noi di Bitrock ci asteniamo dal fornire una soluzione unica; forniamo piuttosto un‘architettura di dati di riferimento modellata sulla base di stack tecnologici utilizzati in diverse aziende, aggiornati con le innovazioni più recenti.
Ci concentriamo su un‘architettura di elaborazione dati multimodale, specializzata in AI/ML e in casi d’uso operativi, in grado di supportare le esigenze analitiche tipiche dei data warehouse. Come spiegato in precedenza, si tratta di un’alternativa all’architettura orientata alla Business Intelligence, basata invece su data warehouse.
Alla base del sistema ci sono i concetti di data lake e data lakehouse.
Un data lake è un repository centralizzato che consente di archiviare e gestire tutti i dati strutturati e non strutturati su qualsiasi scala. E’ tradizionalmente orientato all’elaborazione avanzata dei dati operativi e al ML/AI. Il concetto di data lakehouse aggiunge ad esso un robusto livello di storage abbinato a un motore di elaborazione (Spark, Presto, …) per potenziarlo con capacità di data-warehousing, rendendo i data lake adatti anche a carichi di lavoro analitici.
Questa architettura è sempre più riconosciuta e supportata da un’ampia gamma di fornitori, tra cui Databricks AWS, Google Cloud, Starburst e Dremio, oltre che da fornitori di data warehouse come Snowflake. Per un’introduzione più dettagliata, si rimanda a un precedente articolo del nostro blog (Data Lakehouse, oltre l’ hype).
Il nostro motore di elaborazione preferito è Apache Spark, che è lo standard de-facto per i carichi di lavoro operazionali, abbinato al collaudato e affidabile Apache Airflow o Astronom, una versione SaaS. Nel mondo dell’orchestrazione, Dagster o Prefect sono alternative ad Airflow che stanno riscuotendo molto successo. Favoriscono il passaggio a un’astrazione di livello superiore, dalla gestione del flusso di lavoro alla gestione dei flussi di dati.
Spark è adatto sia per carichi di lavoro batch che in tempo reale, ma per l’elaborazione dei dati in tempo reale Apache Flink e Kafka Streams possono essere valide alternative, soprattutto per le applicazioni con requisiti di latenza più stringenti.
Nel mondo dello streaming applicato all’AI e al ML, un’altra opzione è Helicon di Radicalbit, una soluzione che mira a ridurre il divario tra data scientist e data engineering utilizzando un approccio no-code/low-code. C’è un rinnovato interesse per le soluzioni no-code/low-code, che stanno facendo entrare nuovi utenti (cioè analisti e sviluppatori di software) nel mercato del ML, spinti da nuove soluzioni ML a basso codice come Databricks AutoML, H2O, Datarobot, ecc.
L’esplorazione rapida dei dati può essere ottenuta sia con l’uso di motori di interrogazione ad hoc come Trino/Presto/Starburst/Databricks SQL, sia con l’uso di notebook come Jupyter o le sue versioni gestite.
L’integrazione è il compito noioso che precede la parte divertente. Tuttavia, rappresenta la parte più consistente del costo della maggior parte dei progetti di dati, che va dal 20-30% in media fino al 70% per alcuni casi pessimistici.
Da un punto di vista tecnico, l’ injection layer, è piuttosto diversificato ed è generalmente modellato in base alle fonti di dati e all’infrastruttura dell’organizzazione.
Tradizionalmente, i dati vengono estratti da fonti di dati operative e trasformati prima di essere caricati in un data warehouse, il cosiddetto ETL. Il cloud storage a basso costo e la separazione tra storage ed elaborazione hanno posto le basi per un cambio di paradigma che prevede l’anticipazione della fase di caricamento prima della fase di trasformazione (ELT). Questo modello, in realtà non del tutto nuovo per i data lake, si distingue per il fatto che rimuove la logica di business dalla fase di caricamento nel livello di injection, rendendo possibile semplificare l’integrazione esternalizzandola.
Fivetran, insieme ad Airbyte, Matillion e molti altri, sono esempi di strumenti di ELT. A rigor di termini, il termine ETL è generalmente utilizzato più nel contesto del data-warehousing, tuttavia questi strumenti di integrazione sono utili anche per le architetture lake e lakehouse: Fivetran, ad esempio, è recentemente diventata partner di Databricks.
Nell’ injection layer, Confluent sta giocando un ruolo sempre più importante con i Kafka Connectors, che consentono di copiare (sia in push che in pull) dati da una varietà di fonti. La coppia Kafka e CDC (Change Data Capture), con software come Debezium/Qlik/Fivetran, è un modello di integrazione sempre più comune utilizzato in questo contesto.
La figura seguente, basata sulla piattaforma dati unificata di Horowitz (Bornstein, Li e Casado 2020), esemplifica la nostra architettura, in particolare le caselle evidenziate in giallo:
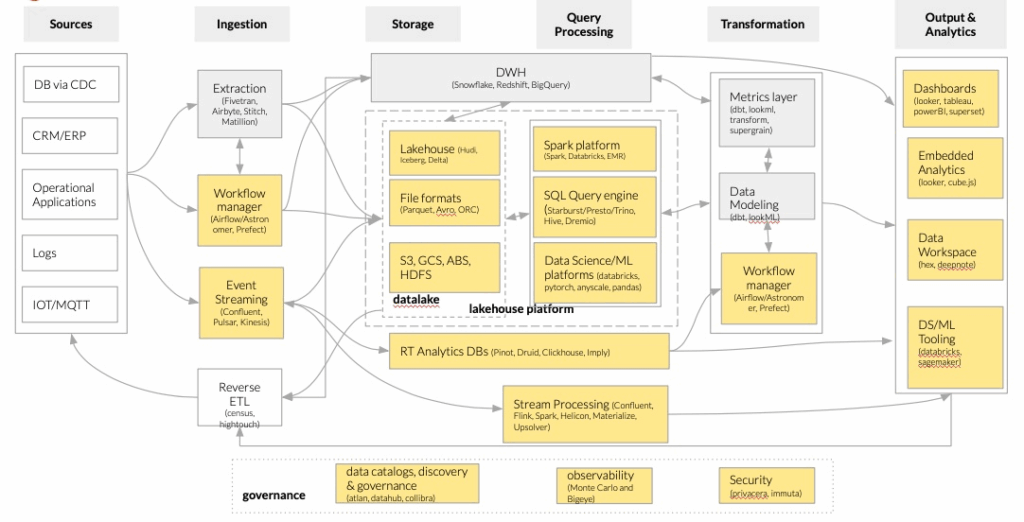
Architetture emergenti per le moderne infrastrutture di dati
Piattaforma ML
Un ruolo centrale nella nostra piattaforma è riservato all’operatività dei modelli di ML e del software basato sull’AI.
MLOps, o Machine Learning Operations, è un settore in rapida crescita nella comunità del ML che sostiene la necessità di gestire il ciclo di vita del ML seguendo le best practice ispirate al software e la filosofia DevOps. Questo approccio mira a rendere il software di ML riproducibile, testabile ed evolvibile, garantendo che i modelli siano distribuiti e aggiornati in modo controllato ed efficiente. L’importanza di MLOps risiede nella capacità di migliorare la velocità e l’affidabilità del deployment dei modelli di ML, riducendo al contempo il rischio di errori e migliorando le prestazioni complessive dei modelli. La nostra idea di una piattaforma generica per l’apprendimento automatico che fornisca tutti gli strumenti per rendere operativo il ciclo di vita del ML è meglio descritta dalla figura seguente, basata su (Bornstein, Li e Casado 2020).
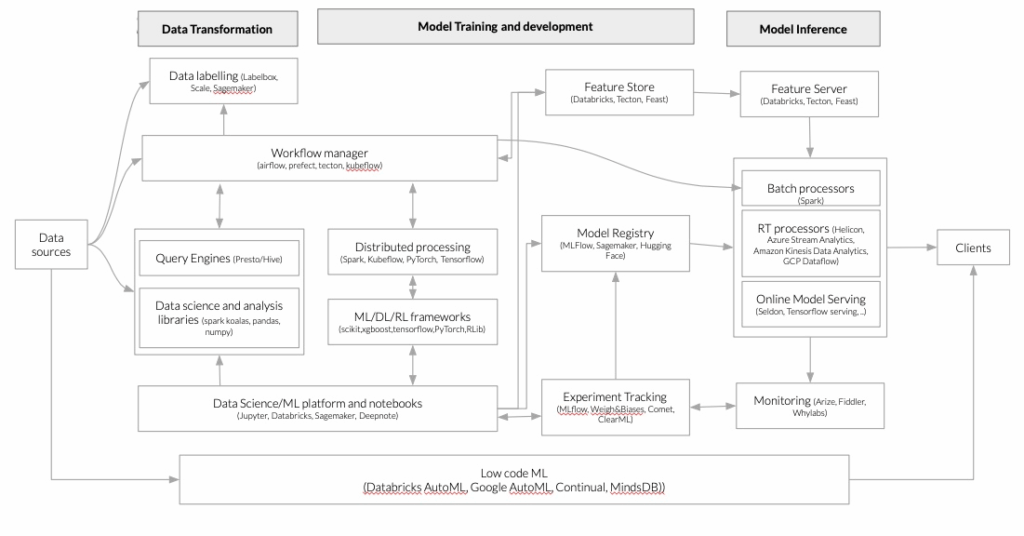
Architetture emergenti per le moderne infrastrutture di dati
Conclusioni
Riteniamo che l’AI e il ML siano cruciali per qualsiasi organizzazione e saranno fondamentali per avere successo e prosperare sul mercato.
Bitrock si impegna a fornire ai clienti la piattaforma, gli strumenti e le competenze per sfruttare tutto il potenziale dell’Intelligenza Artificiale (AI) e del Machine Learning (ML) e renderlo operativo attraverso l’ingegneria dell’AI e gli MLOps.
Personalizziamo la nostra offerta per soddisfare le esigenze uniche dei nostri clienti e crediamo nel fornire soluzioni su misura per i nostri clienti. La nostra ambizione è quella di definire insieme una strategia dei dati chiara ed efficace, in linea con gli obiettivi aziendali generali.
Se avete domande, dubbi o semplicemente volete discutere di argomenti legati ai dati, non esitate a contattarci: saremo più che felici di aiutarvi o semplicemente di chiacchierare!
Riferimenti
- Barbuzzi, Antonio. 2022. “Data Lakehouse, beyond the hype” Bitrock.
- Bornstein, Matt, Jennifer Li, and Martin Casado. 2020. “Emerging Architectures for Modern Data Infrastructure.” Andreessen Horowitz. https://future.com/emerging-architectures-modern-data-infrastructure/.
Autore: Antonio Barbuzzi, Head of Data, AI & ML Engineering @Bitrock