

Why the Lakehouse is here to stay
Introduction
The past few years witnessed a contraposition between two different ecosystems, the data warehouses and the data lakes – the former designed as the core for analytical and business intelligence, generally SQL centred, and the latter based on data lakes, providing the backbone for advanced processing and AI/ML, operating on a wide variety of languages ranging from Scala to Python, R and SQL.
Despite the contraposition between respective market leaders, thinking for example to Snowflake vs Databricks, the emerging pattern shows also a convergence between these two core architectural patterns [Bor20].
The lakehouse is the new concept that moves data lakes closer to data warehouses, making them able to compete in the BI and analytical world.
Of course, as with any emerging technical innovations, it is hard to separate the marketing hype from the actual technological value, which, ultimately, only time and adoption can prove. While it is undeniable that marketing is playing an important role in spreading the concept, there’s a lot more in this concept than just buzzwords.
Indeed, the Lakehouse architecture has been introduced separately and basically in parallel by three important and trustworthy companies, and with three different implementations.
Databricks published its seminal paper on data lake [Zah21], followed by open sourcing Delta Lake framework [Delta, Arm20].
In parallel Netflix, in collaboration with Apple, introduced Iceberg [Iceberg], while Uber introduced Hudi [Hudi] (pronounced “Hoodie”), both becoming top tier Apache projects in May 2020.
Moreover, all major data companies are competing to support it, from AWS to Google Cloud, passing through Dremio, Snowflake and Cloudera, and the list is growing.
In this article, I will try to explain, in plain language, what a lakehouse is, why it is generating so much hype, and why it is rapidly becoming a centerpiece of modern data platform architectures.
What is a Lakehouse?
In a single sentence, a lakehouse is a “data lake” on steroids, unifying the concept of “data lake” and “data warehouse”.
In practice, the lakehouse leverages a new metadata layer providing a “table abstraction” and some features typical of data warehouses on top of a classical Data Lake.
This new layer is built on top of existing technologies in particular on a binary, often columnar, file format, which can be either Parquet, ORC or Avro, and on a storage layer.
Therefore, the main building blocks of a lakehouse platform (see figure 1.x), from a bottom-up perspective, are:
- A File Storage layer, generally cloud based, for example AWS S3 or GCP Cloud Storage or Azure Data Lake Storage Gen2.
- A binary file format like Parquet or ORC used to store data and metadata
- The new table file format layer, Delta Lake, Apache Iceberg or Apache Hudi
- A processing engine supporting the above table format, for example Spark or Presto or Athena, and so on.
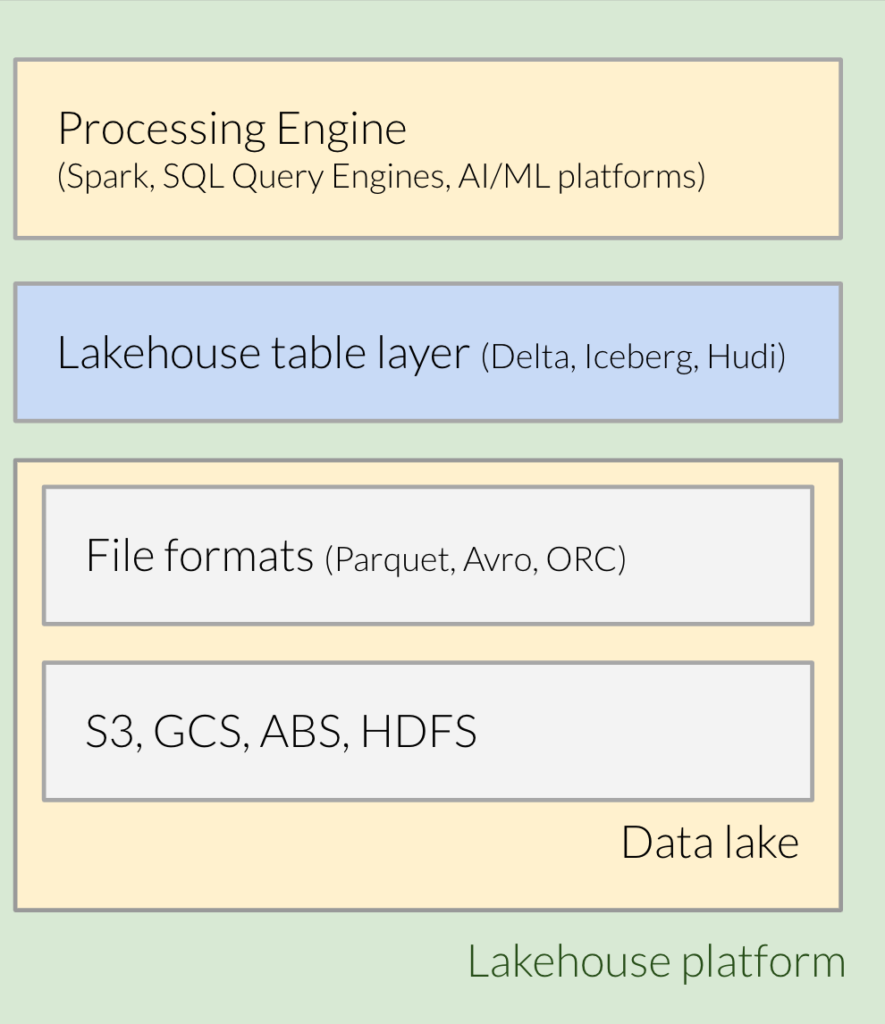
To better understand the idea behind the lakehouse and the evolution towards it, let’s start with the background.
First generation, the data warehouse
Data Warehouses have been around for 40+ years now.
They were invented to answer some business questions which were too computational intensive for the operational databases and to be able to join datasets coming from multiple sources.
The idea was to extract data from the operational systems, transform them in the more suitable format to answer those questions and, finally, load them into a single specialised database. Incidentally, this process is called ETL (Extract, Transform, Load).
This is sometimes also referred to as the first generation.
To complete the concept, a data mart is a portion of a data warehouse focused on a specific line of business or department.
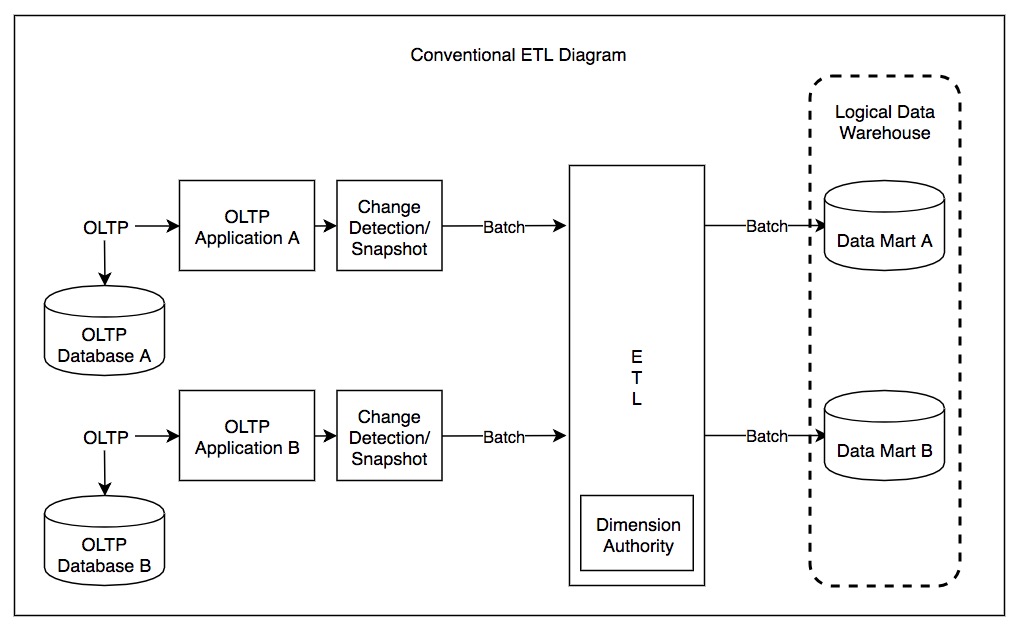
The second generation, data lakes
The growing volume of data to handle, along with the need to deal with unstructured data (i.e. images, videos, text documents, logs, etc) made data warehouses more and more expensive and inefficient.
To overcome these problems, the second generation data analytics platforms started offloading all the raw data into data lakes, low-cost storage systems providing a file-like API.
Data lakes started with Mapreduce and Hadoop (even if the name data lake came later) and were successively followed up by cloud data lakes, such as the one based on S3, ADLS and GCS.
Lakes feature low cost storage, higher speed, and greater scalability, but, on the other hand, they gave up many of the advantages of warehouses.
Data Lakes and Warehouses
Lakes did not replace warehouses: they were complementary, each of them addressed different needs and use cases. Indeed, raw data was initially imported into data lakes, manipulated, transformed and possibly aggregated. Then, a small subset of it would later be ETLed to a downstream data warehouse for decision intelligence and BI applications.
This two-tier data lake + warehouse architecture is now largely used in the industry, as you can see in the figure below:
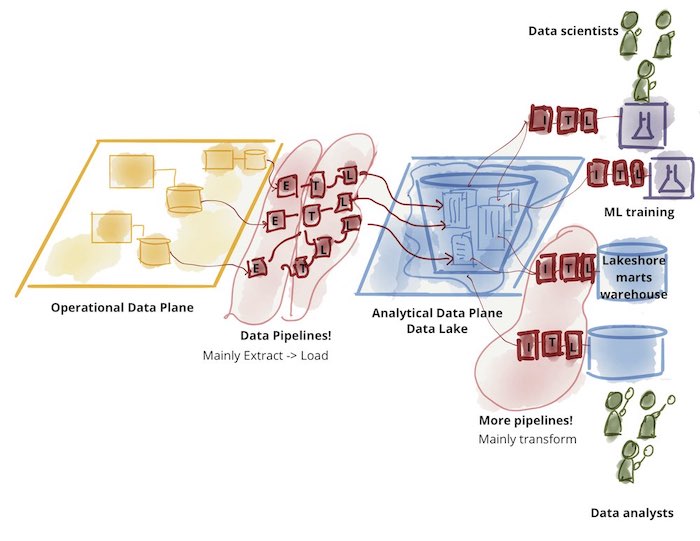
Problems with two-tiered Data Architectures
A two-tier architecture comes with additional complexity and in particular it suffers from the following problems:
- Reliability and redundancy, as more copies of the same data exist in different systems and they need to be kept available and consistent across each other;
- Staleness, as the data needs to be loaded first in the data lakes and, only later, into the data warehouse, introducing additional delays from the initial load to when the data is available for BI;
- Limited support for AI/ML on top of BI data: business requires more and more predictive BI analysis, for example, “which customers should we offer discounts”. AI/ML libraries do not run on top of warehouses, so vendors often suggest offloading data back to the lakes, adding additional steps and complexity to the pipelines.
Modern data warehouses are adding some support for AI/ML, but they’re still not ideal to cope with binary formats (video, audio, etc). - Cost: of course, keeping up two different systems increases the total cost of ownership, which includes administration, licences cost, additional expertise cost.
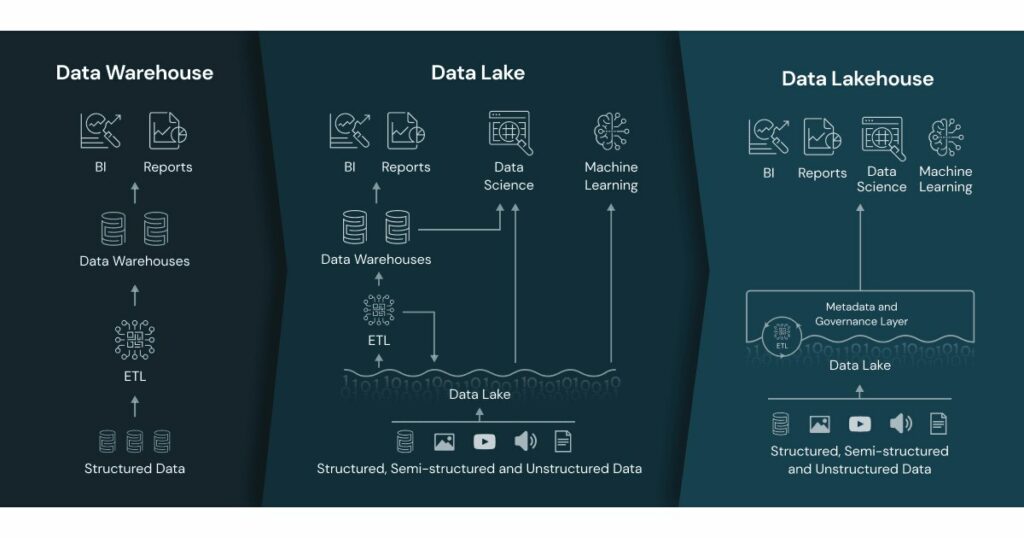
The third generation, the Data Lakehouse
A data lakehouse is an architectural paradigm adding a table layer backed up by file-metadata to a data lake, in order to provide traditional analytical DB features such as ACID transactions, data versioning, auditing, indexing, caching and query optimization.
In practice, it may be considered as a data lake on steroids, a combination of both data lakes and data warehouses.
This pattern allows to move many of the use cases traditionally handled by data warehouses into data lakes, it simplifies the implementation by moving from a two-tier pipeline to a single tier one.
In the following figure you can see a summary of the three different architectures.
Additionally, lakehouses move the implementation and support of data warehouses features from the processing engine to the underlying file format. As such, more and more processing engines are able to capitalise on the new features. Indeed most engines are coming up with a support for lake houses format (Presto, Starburst, Athena, …), contributing to the hype. The benefits for the users is that the existence of multiple engines featuring data warehouses capabilities allows them to pick the best solution suitable for each use case. For example, exploiting spark for more generic data processing and AI/ML problems, or Trino/Starburst/Athena/Photon/etc for quick SQL queries.
Characteristics of Data Lakehouse
For those who may be interested, let’s dig (slightly) more into the features provided by lake houses and on their role.
ACID
The most important feature, available across all the different lakehouse implementations, is the support of ACID transactions.
ACID, standing for atomicity, consistency, isolation, durability, is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps.
Indeed, cloud object stores haven’t always provided strong consistency, so stale reads were possible – this is called eventual consistency.
Anyway, there’s no mutual exclusion guarantees, so that multiple writers can update the same file without external coordination and there’s no atomic update support across multiple keys, so that updates to multiple files may be seen at different times.
Lakehouse implementations guarantee ACID transactions on a single table, despite the underlying used storage and regardless of the number of files used underlying.
This is achieved in different ways in the three major players, but generally speaking, they all use metadata files to identify which files are part of a table snapshot and some WAL-like file to track all the changes applied to a table.
Note that there are alternative ways to provide ACID consistency, in particular by using an external ACID consistent metadata storage, like an external DB. This is what HIVE 3 ACID does for example, or Snowflake. However, not having to depend on an external system removes a bottleneck, a single point of failure, and allows multiple processing engines to leverage on the data structure.
Partitioning
Automatic partitioning is another fundamental feature, used to reduce queries’ process requirements and simplify table maintenance. This feature is implemented by partitioning data into multiple folders and while it can be easily implemented at application level, this is easily provided transparently by the lakehouse. Moreover some lakeshouses (see Iceberg) can support partitioning evolution automatically.
Time Travel
Time Travel is the ability to query/restore a table to a previous state in time.
This is achieved by keeping metadata containing snapshot information for longer time periods.
Time travel is a feature provided by traditional DBs oriented to OLAP workloads too, as this feature may be implemented relying on write-ahead-logs. Indeed it was available also in Postgres DB for example, until version 6.2, SQL Server. The separation between storage and processing makes this feature easier to support in lake houses, relying them on cheap underlying storage.
Of course, to reduce cost/space usage, you may want to periodically clean up past metadata, so that time travel is possible up to the oldest available snapshot.
Schema Evolution and Enforcement
Under the hood, Iceberg, Delta and Hudi rely on binary file formats (Parquet/ORC/Avro), which are compatible with most of the data processing frameworks.
Lakehouse provides an additional abstraction layer allowing in-place schema evolution, a mapping between the underlying files’ schemas and the table schema, so that schema evolution can be done in-place, without rewriting the entire dataset.
Streaming support
Data Lakes are not well suited for streaming applications for multiple reasons, to name a few cloud storages do not allow to append data to files for example, they haven’t provided for a while a consistent view on written files, etc. Yet this is a common need and, for example, offloading kafka data into a storage layer is a fundamental part of the lambda architecture.
The main obstacles are that object stores do not offer an “append” feature or a consistent view across multiple files.
Lake Houses make it possible to use delta tables as both input and output. This is achieved by an abstraction layer masking the use of multiple files and a background compassion process joining small files into larger ones, in addition to “Exactly-Once Streaming Writes” and “efficient log tailing”. For details please see [Arm20].
The great convergence
Will lake house-based platforms completely get rid of data warehouses? I believe this is unlikely. What’s sure at the moment is that the boundaries between the two technologies are becoming more and more blurred.
Indeed, while data lakes, thanks to Deta Lake, Apache Iceberg and Apache Hudi are moving into data warehouses territory, the opposite is true as well.
Indeed, Snowflake has added support for the lakehouse table layer (Apache Iceberg/Delta at the time of writing), becoming one of the possible processing engines supporting the lakehouse table layer.
At the same time, warehouses are moving into AI/ML applications, traditionally a monopoly of data-lakes: Snowflake released Snowpark, a AI/ML python library, allowing to write data pipelines and ML workflow directly in Snowflake. Of course it will take a bit of time for the data science community to accept and master yet another library, but the directions are marked.
But what’s interesting is that warehouses and lakes are becoming more and more similar: they both rely on commodity storage, offer native horizontal scaling, support semi-structured data types, ACID transactions, interactive SQL queries, and so on.
Will they converge to the point where they’ll become interchangeable in the data stacks? This is hard to tell and experts have different opinions: while the direction is undeniable, differences in languages, use cases or even marketing will play an important role in defining how future data stacks will look like. Anyway, it is a safe bet to say that the lakehouse is here to stay.
References
- [Bor20] Matt Bornstein, Jennifer Li, and Martin Casado, Emerging Architectures for Modern Data Infrastructure, 2020, online article, https://future.com/emerging-architectures-modern-data-infrastructure/
- [Zah21] Matei Zaharia, Ali Ghodsi 0002, Reynold Xin, Michael Armbrust, Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, in 11th Conference on Innovative Data Systems Research, CIDR 2021, Virtual Event, January 11-15, 2021, Online Proceedings. www.cidrdb.org, 2021.
- [Delta] Delta Lake – https://delta.io/
- [Arm20] Michael Armbrust et al., Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores, PVLDB, 13(12):3411-3424, 2020.
- [Iceberg] Apache Iceberg – https://iceberg.apache.org/
- [Hudi] Apache Hudi – https://hudi.apache.org/
- [Postgresql] Time Travel – https://www.postgresql.org/docs/6.3/c0503.htm
- [Microsoft Learn] Temporal tables – https://learn.microsoft.com/en-us/sql/relational-databases/tables/temporal-tables?view=sql-server-ver16
Author: Antonio Barbuzzi, Head of Data, AI & ML Engineering @ Bitrock