

Oggigiorno le organizzazioni devono affrontare la sfida di elaborare enormi quantità di dati. I tradizionali sistemi di elaborazione batch non soddisfano più i moderni requisiti di analisi dei dati. È qui che entra in gioco Apache Flink.
Apache Flink è un framework open-source per l’elaborazione di flussi di dati che offre potenti funzionalità per l’elaborazione e l’analisi di flussi di dati in tempo reale. Tra i suoi principali punti di forza, possiamo citare:
- Scalabilità elastica per gestire carichi di lavoro su larga scala
- Flessibilità linguistica per fornire API per Java, Python e SQL
- Elaborazione unificata per eseguire calcoli in streaming, batch e analitici
Apache Flink può contare su una community attiva e solidale e offre una perfetta integrazione con Kafka, che lo rende una soluzione versatile per diversi casi d’uso. Offre un supporto completo per un’ampia gamma di scenari, tra cui streaming, batching, normalizzazione dei dati, riconoscimento dei modelli, verifica dei pagamenti, analisi del flusso di clic, aggregazione dei log e analisi delle frequenze. Inoltre, Flink è altamente scalabile e può gestire in modo efficiente carichi di lavoro di qualsiasi dimensione.
Durante il Kafka Summit 2023, Apache Flink ha ricevuto un’attenzione significativa, evidenziando la sua crescente popolarità e rilevanza. Per dimostrare ulteriormente il crescente interesse per questa tecnologia, Confluent, azienda leader nell’ecosistema Kafka, ha presentato una roadmap che illustra le prossime funzionalità alimentate da Flink per Confluent Cloud:
- Servizio SQL (anteprima pubblica autunno 2023)
- SQL (disponibilità generale inverno 2023)
- API Java e Python (2024)
Liberare la potenza di Apache Flink: il partner perfetto per Kafka
L’elaborazione dei flussi è un paradigma di elaborazione dei dati che prevede l’analisi continua di eventi provenienti da una o più fonti di dati. Si concentra sull’elaborazione dei dati in movimento, al contrario dell’elaborazione in batch.
L’elaborazione dei flussi può essere classificata in due tipi: stateless e stateful. L’elaborazione stateless comporta il filtraggio o la trasformazione di singoli messaggi, mentre l’elaborazione stateful comporta operazioni come l’aggregazione o le finestre scorrevoli.
La gestione dello stato nelle elaborazioni distribuite in streaming è un compito complesso. Tuttavia, Apache Flink mira a semplificare questa sfida offrendo funzionalità di elaborazione stateful per la creazione di applicazioni di streaming. Apache Flink fornisce API, operatori avanzati e controllo di basso livello per gli stati distribuiti. È progettato per essere scalabile, anche per complesse query JOIN in streaming.
La scalabilità e la flessibilità del motore di Flink sono fondamentali per fornire un potente framework di elaborazione di flussi per gestire carichi di lavoro di big data.
Inoltre, Apache Flink offre ulteriori funzionalità e capacità:
- API unificate per lo streaming e il batch
- Transazioni tra Kafka e Flink
- Apprendimento automatico con Kafka, Flink e Python
- Supporto SQL standard
API di Streaming e Batch Unificate
L’API DataStream di Apache Flink combina sia le funzionalità batch che quelle di streaming, offrendo il supporto per diverse modalità di esecuzione runtime e fornendo così un modello di programmazione unificato. Quando si utilizza l’API SQL/Table, la modalità di esecuzione viene determinata automaticamente in base alle caratteristiche delle fonti di dati. Se tutti gli eventi sono vincolati, viene utilizzata la modalità di esecuzione batch. Se invece almeno un evento non è vincolato, viene utilizzata la modalità di esecuzione streaming. Questa flessibilità consente ad Apache Flink di adattarsi senza problemi a diversi scenari di elaborazione dei dati.
Transazioni tra Kafka e Flink
Apache Kafka e Apache Flink sono ampiamente diffusi in architetture robuste ed essenziali. Il concetto di semantica exactly-once (EOS) garantisce che le applicazioni di elaborazione dei flussi possano elaborare i dati attraverso Kafka senza perdite o duplicazioni. Molte aziende hanno già adottato EOS in produzione utilizzando Kafka Streams. Il vantaggio è che EOS può essere sfruttato anche quando si combinano Kafka e Flink, grazie all’API Kafka connector di Flink. Questa funzionalità è particolarmente preziosa quando si utilizza Flink per carichi di lavoro transazionali. Questa funzionalità è matura e collaudata in produzione, tuttavia gestire cluster separati per i carichi di lavoro transazionali può essere ancora impegnativo e talvolta i servizi cloud con obiettivi simili possono assumersi questo onere a favore della semplicità.
Apprendimento automatico con Kafka, Flink e Python
La combinazione di streaming di dati e machine learning offre una soluzione potente per distribuire in modo efficiente modelli analitici per lo scoring in tempo reale, indipendentemente dalla scala dell’operazione. PyFlink, un’API Python per Apache Flink, consente di creare carichi di lavoro scalabili in batch e in streaming, come pipeline di elaborazione dei dati in tempo reale, analisi dei dati esplorativi su larga scala, pipeline di Machine Learning (ML) e processi ETL.
Supporto SQL standard
Il linguaggio SQL (Structured Query Language) è un linguaggio specifico utilizzato per la gestione dei dati in un sistema di gestione di database relazionali (RDBMS). Tuttavia, SQL non è limitato agli RDBMS ed è adottato anche da diverse piattaforme e tecnologie di streaming. Apache Flink offre un supporto completo per ANSI SQL, che comprende il Data Definition Language (DDL), il Data Manipulation Language (DML) e il Query Language.
Questo è un vantaggio perché SQL è già ampiamente utilizzato da diversi professionisti, tra cui sviluppatori, architetti e analisti aziendali, nel loro lavoro quotidiano.
L’integrazione di SQL è facilitata dal Flink SQL Gateway, che è un componente del framework Flink e consente ad altre applicazioni di interagire con un cluster Flink attraverso un’API REST. Questo apre la possibilità di integrare Flink SQL con i tradizionali strumenti di business intelligence.
Inoltre, Flink fornisce un’API per le tabelle che integra le funzionalità SQL offrendo funzioni dichiarative a lavori di tipo imperativo. Ciò significa che gli utenti possono combinare senza problemi le API DataStream e le API Table, come mostrato nell’esempio seguente:

Flink Runtime
Come già detto, Flink supporta lo streaming e l’elaborazione batch. È ora il momento di analizzare le principali differenze:
Lo streaming funziona con flussi delimitati o non delimitati. In altre parole:
- L’intera pipeline deve essere sempre in esecuzione
- Gli input devono essere elaborati man mano che arrivano
- I risultati vengono riportati non appena sono pronti
- Il recupero dei guasti riprende da un’istantanea recente
- Flink può garantire risultati exactly-once se correttamente configurato con Kafka
Il batch funziona solo con un flusso limitato. In altre parole:
- L’esecuzione procede per fasi e viene eseguita secondo le necessità
- L’input può essere pre-ordinato per tempo e chiave
- I risultati sono riportati alla fine del lavoro
- Il recupero in caso di fallimento prevede un reset e un riavvio completo
- Garanzia, le garanzie “exactly-once” sono più semplici
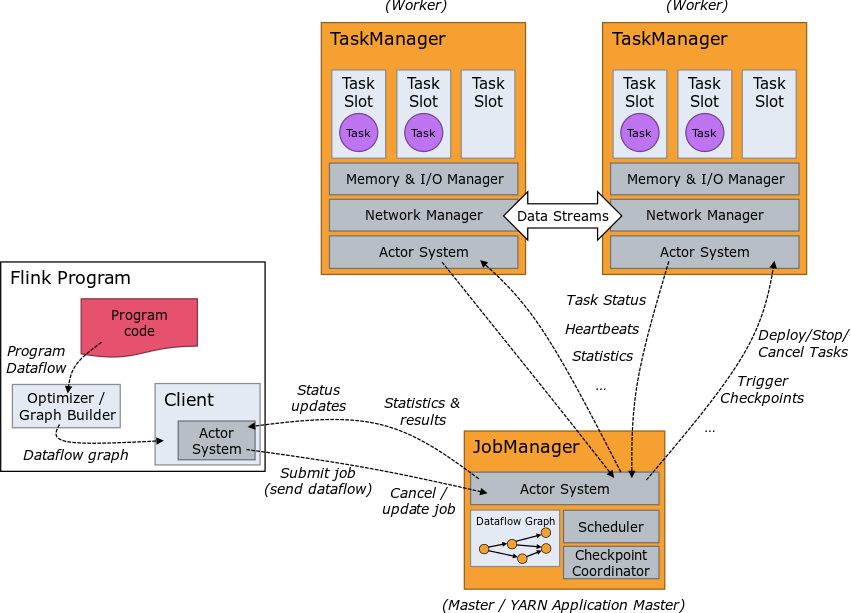
Conclusioni
Apache Flink offre numerosi vantaggi per l’elaborazione dei flussi e l’analisi dei dati in real-time. La sua perfetta integrazione con Kafka consente un’efficiente acquisizione ed elaborazione dei dati. Le capacità di elaborazione stateful di Flink semplificano la gestione delle computazioni distribuite, rendendo più facile la creazione di applicazioni di streaming complesse. La scalabilità e la flessibilità del motore di Flink consentono di gestire facilmente carichi di lavoro su larga scala.
Inoltre, Flink fornisce API unificate per lo streaming e il batch, consentendo agli sviluppatori di lavorare con entrambi i tipi di paradigmi di elaborazione dei dati senza problemi. Grazie al supporto dell’apprendimento automatico e dell’SQL standard, Flink consente agli utenti di eseguire analisi avanzate e di utilizzare linguaggi di interrogazione familiari. Nel complesso, Apache Flink è una piattaforma potente e versatile che consente alle aziende di sfruttare appieno il potenziale dei dati in tempo reale.
Autore: Luigi Cerrato, Software Engineer @ Bitrock
Si ringrazia il team tecnico della nostra consociata Radicalbit per il prezioso contributo a questo articolo.
