

Il recente clamore suscitato da Apache Flink, soprattutto dopo il Kafka Summit 2023 di Londra, ha suscitato la nostra curiosità e ci ha spinto a comprendere meglio le ragioni di tale entusiasmo. In particolare, volevamo sapere quanto Flink differisce da Kafka Streams, la curva di apprendimento e i casi d’uso in cui queste tecnologie possono essere applicate. Entrambe le soluzioni offrono strumenti potenti per l’elaborazione dei dati in tempo reale, ma presentano differenze significative in termini di finalità e funzionalità.
Elaborazione dei dati: Apache Flink vs Kafka Streams
Apache Flink è un framework open-source unificato per l’elaborazione di dati stream e batch. È un sistema di calcolo distribuito in grado di elaborare grandi quantità di dati in tempo reale con tolleranza agli errori e scalabilità.
D’altra parte, Kafka Streams è una libreria specifica integrata in Apache Kafka che fornisce un quadro per la costruzione di diverse applicazioni e microservizi che elaborano dati in tempo reale.
Kafka Streams fornisce un modello di programmazione che consente agli sviluppatori di definire operazioni di trasformazione sui flussi di dati utilizzando API funzionali di tipo DSL. Questo modello si basa su due tipi di API: l’API DSL e l’API Processor. L’API DSL è costruita sopra l’API Processor ed è consigliata soprattutto ai principianti. L’API Processor è destinata allo sviluppo di applicazioni avanzate e comporta l’impiego di funzionalità Kafka di basso livello.
Kafka Streams è stato creato per fornire un’opzione nativa per l’elaborazione di dati in streaming senza la necessità di framework o librerie esterne. Un lavoro Kafka Streams è essenzialmente un’applicazione autonoma che può essere orchestrata a discrezione dell’utente.
Principali differenze
Come già accennato, Flink è un motore di esecuzione su cui vengono eseguiti i lavori di elaborazione, mentre Kafka Streams è una libreria Java che consente alle applicazioni client di eseguire lavori di streaming senza la necessità di sistemi distribuiti aggiuntivi oltre a un cluster Kafka in esecuzione. Ciò implica che se gli utenti vogliono sfruttare Flink per l’elaborazione dei flussi, dovranno lavorare con due sistemi.
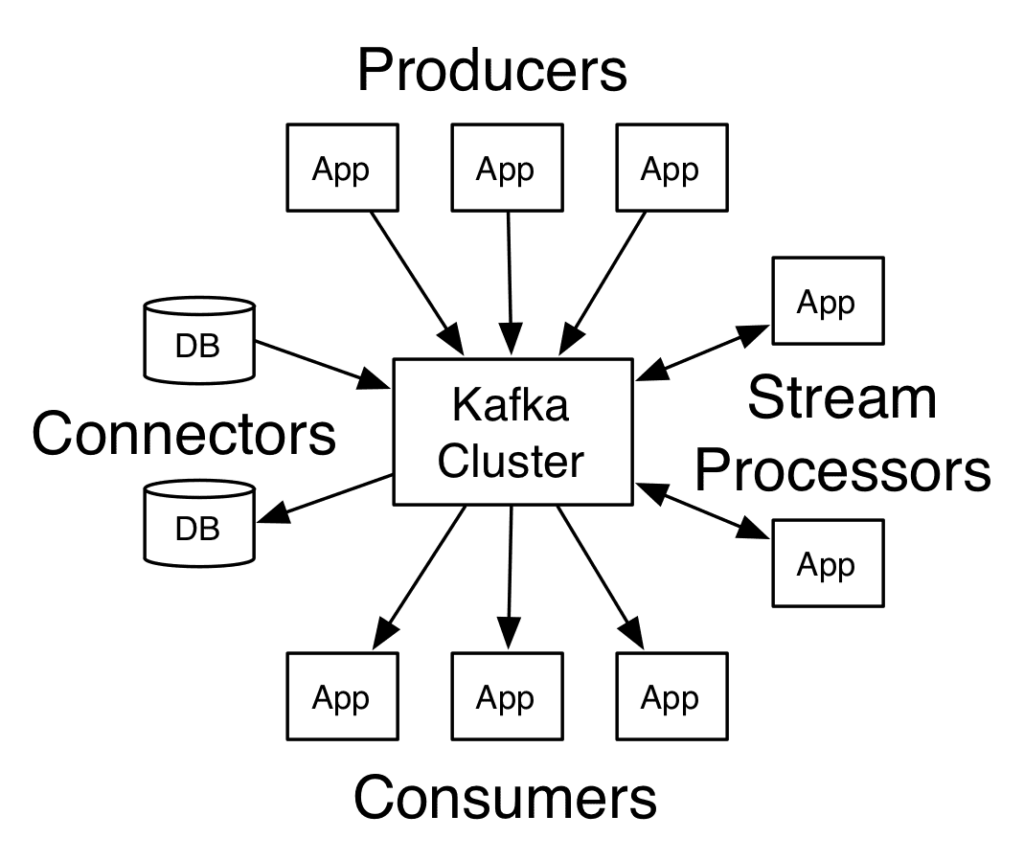
Inoltre, sia Apache Flink che Kafka Streams offrono API di alto livello (Flink DataStream API, Kafka Streams DSL) e API avanzate per implementazioni più complesse, come le Kafka Streams Processor API.
Ora diamo uno sguardo più da vicino alle principali differenze tra Apache Kafka e Flink.
- Integrazioni
Come fanno questi sistemi a stabilire connessioni con il mondo esterno?
Apache Flink offre un’integrazione nativa con un’ampia gamma di tecnologie, tra cui Hadoop, RDBMS, Elasticsearch, Hive e altre ancora. Questa integrazione è resa possibile dall’utilizzo della suite Flink Connectors, dove questi connettori funzionano come sorgenti all’interno delle pipeline di Flink.
Kafka Streams è strettamente integrato con Kafka per l’elaborazione dei dati in streaming. L’ecosistema Kafka fornisce Kafka Connect, che consente l’integrazione di fonti di dati esterne, in quanto gli eventi vengono suddivisi in topic. Ad esempio, utilizzando il connettore Kafka Connect Debezium, gli utenti possono trasmettere gli eventi del flusso Change Data Capture in un topic Kafka. Una topologia Kafka Stream può quindi consumare questo topic e applicare la logica di elaborazione per soddisfare i requisiti aziendali specifici.
- Scalabilità
Apache Flink è un motore progettato per scalare su un cluster di macchine e la sua scalabilità è limitata solo dalla definizione del cluster. D’altra parte, mentre è possibile scalare orizzontalmente le applicazioni Kafka Streams, la scalabilità potenziale è limitata al numero massimo di partizioni possedute dai topic di origine.
- Tolleranza ai guasti e affidabilità
Sia Kafka Streams che Apache Flink garantiscono un’elevata disponibilità e tolleranza ai guasti, ma utilizzano approcci diversi. Kafka Streams delega le capacità dei broker Kafka. Apache Flink dipende da sistemi esterni per la gestione dello stato persistente utilizzando uno storage a livelli e
- Funzionamento
Kafka Streams, in quanto libreria, richiede che gli utenti scrivano le loro applicazioni e le gestiscano come farebbero normalmente. A questo scopo si può utilizzare, ad esempio, un deployment Kubernetes e, aggiungendo Horizontal Pod Autoscaling (HPA), si può abilitare lo scale-out orizzontale.
Apache Flink è un motore che deve essere orchestrato per consentire i carichi di lavoro Flink. Attualmente, gli utenti di Flink possono sfruttare un operatore Kubernetes Flink sviluppato dalla comunità per integrare le esecuzioni di Flink in modo nativo su cluster Kubernetes.
- Windowing
Sia Kafka Streams che Flink supportano il windowing, ovvero la capacità di ricevere gli eventi in un determinato arco temporale, (tumbling, sliding, session) con alcune differenze:
- Kafka Streams gestisce il windowing in base al tempo degli eventi e al tempo di elaborazione.
- Apache Flink gestisce un windowing flessibile basato sul tempo degli eventi, sul tempo di elaborazione e sul tempo di ingestione.
Casi d’uso
Sebbene entrambi i framework offrano caratteristiche e vantaggi unici, hanno punti di forza diversi quando si tratta di casi d’uso specifici.
Apache Flink è la scelta ideale per:
- Elaborazione di dati in real-time: analisi di eventi in tempo reale, monitoraggio delle prestazioni, rilevamento di anomalie ed elaborazione di dati di sensori IoT.
- Elaborazione di eventi complessi: riconoscimento di pattern, aggregazione ed elaborazione di eventi correlati, come il rilevamento di sequenze di eventi o la gestione di finestre temporali.
- Elaborazione di dati batch: generazione di report ed elaborazione di archivi di dati.
- Machine Learning su dati in streaming: addestramento e applicazione di modelli di machine learning su dati in streaming, consentendo l’elaborazione in tempo reale dei risultati e delle previsioni del machine learning.
Kafka Streams è la scelta ideale per:
- Architetture a microservizi: particolarmente utilizzate per l’implementazione di modelli event-driven come event sourcing o CQRS.
- Elaborazione dei dati di input e output di Kafka: trasformare, filtrare, aggregare o arricchire i dati di input e produrre dati di output in tempo reale.
- Elaborazione dei dati di log: analisi dei log di accesso ai siti web, monitoraggio delle prestazioni dei servizi o rilevamento di eventi significativi dai log di sistema.
- Real-time analytics: aggregazione dei dati, creazione di rapporti in tempo reale e attivazione di azioni basate su eventi.
- Machine Learning: addestramento e applicazione di modelli di apprendimento automatico su dati in streaming per l’assegnazione di punteggi in tempo reale.
Curva di apprendimento e risorse
La curva di apprendimento di una tecnologia non è sempre un dato oggettivo e può variare in base a diversi fattori. Tuttavia, abbiamo cercato di fornire una panoramica generale basata su fattori quali la disponibilità di risorse e gli esempi.
I concetti di base di Kafka Streams, come KStreams (flussi di dati) e KTables (tabelle di dati), possono essere facilmente afferrati. Mentre la padronanza di funzioni avanzate, come l’aggregazione di finestre temporali o l’elaborazione di eventi correlati, può richiedere ulteriori approfondimenti. La documentazione ufficiale di Kafka Streams, disponibile sul sito web di Kafka all’indirizzo https://kafka.apache.org/documentation/streams/, è un riferimento prezioso per imparare, esplorare e sfruttare tutte le sue capacità.
Per iniziare con Apache Flink, si consiglia di imparare il modello di programmazione di base, compreso il lavoro con i flussi e gli insiemi di dati. Anche in questo caso, la padronanza di concetti avanzati come la gestione degli stati, le finestre temporali o il raggruppamento può richiedere ulteriore studio e pratica. La documentazione ufficiale di Flink, disponibile sul sito web di Confluent all’indirizzo https://nightlies.apache.org/flink/flink-docs-stable/, costituisce una risorsa completa per l’apprendimento e l’esplorazione.
Conclusioni
Per farla breve, Apache Flink e Kafka Streams sono due framework open-source con i loro punti di forza e di debolezza per l’elaborazione di flussi in grado di elaborare grandi quantità di dati in tempo reale.
Apache Flink è un framework completamente statico che può memorizzare lo stato dei dati durante l’elaborazione, il che lo rende ideale per le applicazioni che richiedono calcoli complessi o consistenza dei dati. Kafka Streams è un framework parzialmente statico ed è ideale per le applicazioni che richiedono una bassa latenza o per elaborare grandi quantità di dati. Apache Flink è un framework più generalizzato che può essere utilizzato per diverse applicazioni, tra cui l’elaborazione dei log, l’elaborazione dei dati in tempo reale e l’analisi dei dati. Kafka Streams è più specifico per l’elaborazione dei flussi.
Possiamo concludere affermando che il framework migliore per un’applicazione specifica dipenderà dalle esigenze specifiche dell’applicazione.
Autore: Luigi Cerrato, Software Engineer @ Bitrock
Si ringrazia il team tecnico della nostra consociata Radicalbit per il prezioso contributo a questo articolo.