

Nowadays organizations are facing the challenge to process massive amounts of data. Traditional batch processing systems don’t meet the modern data analytics requirements anymore. And that’s where Apache Flink comes into play.
Apache Flink is an open-source stream processing framework that provides powerful capabilities for processing and analyzing data streams in real-time. Among its key strengths, we can mention:
- Elastic scalability to handle large-scale workloads
- Language flexibility to provide API for Java, Python and SQL
- Unified processing to perform streaming, batch and analytics computations
Apache Flink can rely on a supportive and active community as well as offers seamless integration with Kafka, making it a versatile solution for various use cases. It provides comprehensive support for a wide range of scenarios, including streaming, batching, data normalization, pattern recognition, payment verification, clickstream analysis, log aggregation, and frequency analysis. Additionally, Flink is highly scalable and can efficiently handle workloads of any size.
During the Kafka Summit 2023, Apache Flink received significant attention, highlighting its increasing popularity and relevance. To further demonstrate the growing interest in this technology, Confluent, a leading company in the Kafka ecosystem, presented a roadmap outlining upcoming Flink-powered features for Confluent Cloud:
- SQL Service (public preview fall 2023)
- SQL (general availability winter 2023)
- Java and Python API (2024)
Unleashing the power of Apache Flink: the perfect partner for Kafka
Stream processing is a data processing paradigm that involves continuously analyzing events from one or multiple data sources. It focuses on processing data in motion, as opposed to batch processing.
Stream processing can be categorized into two types: stateless and stateful. Stateless processing involves filtering or transforming individual messages, while stateful processing involves operations like aggregation or sliding windows.
Managing state in distributed streaming computations is a complex task. However, Apache Flink aims to simplify this challenge by offering stateful processing capabilities for building streaming applications. Apache Flink provides APIs, advanced operators, and low-level control for distributed states. It is designed to be scalable, even for complex streaming JOIN queries.
The scalability and flexibility of Flink’s engine are crucial in providing a powerful stream processing framework for handling big data workloads.
Furthermore, Apache Flink offers additional features and capabilities:
- Unified Streaming and Batch APIs
- Transactions Across Kafka and Flink
- Machine Learning with Kafka, Flink, and Python
- Standard SQL support
Unified Streaming and Batch APIs
Apache Flink’s DataStream API combines both batch and streaming capabilities by offering support for various runtime execution modes and by doing so providing a unified programming model. When using the SQL/Table API, the execution mode is automatically determined based on the characteristics of the data sources. If all events are bound, the batch execution mode is utilized. On the other hand, if at least one event is unbounded, the streaming execution mode is employed. This flexibility allows Apache Flink to seamlessly adapt to different data processing scenarios.
Transactions Across Kafka and Flink
Apache Kafka and Apache Flink are widely deployed in robust and essential architectures. The concept of exactly-once semantics (EOS) ensure that stream processing applications can process data through Kafka without loss or duplication. Many companies have already adopted EOS in production using Kafka Streams. The advantage is that EOS can also be leveraged when combining Kafka and Flink, thanks to Flink’s Kafka connector API. This capability is particularly valuable when using Flink for transactional workloads. This feature is mature and battle-tested in production, however operating separate clusters for transactional workloads can still be challenging and sometimes cloud services with similar aimings can take over this burden in favor of simplicity.
Machine Learning with Kafka, Flink, and Python
The combination of data streaming and machine learning offers a powerful solution to efficiently deploy analytical models for real-time scoring, regardless of the scale of the operation. PyFlink, a Python API for Apache Flink, allows you to build scalable batch and streaming workloads, such as real-time data processing pipelines, large-scale exploratory data analysis, Machine Learning (ML) pipelines, and ETL processes.
Standard SQL Support
Structured Query Language (SQL) is a domain-specific language used for managing data in a relational database management system (RDBMS). However, SQL is not limited to RDBMS and is also adopted by various streaming platforms and technologies. Apache Flink offers comprehensive support for ANSI SQL, encompassing the Data Definition Language (DDL), Data Manipulation Language (DML), and Query Language.
This is advantageous because SQL is already widely used by different professionals including developers, architects, and business analysts, in their daily work.
The SQL integration is facilitated through the Flink SQL Gateway, which is a component of the Flink framework and allows other applications to interact with a Flink cluster through a REST API. This opens up the possibility of integrating Flink SQL with traditional business intelligence tools.
Additionally, Flink provides a Table API that complements the SQL capabilities by offering declarative features to imperative-like jobs. This means that users can seamlessly combine the DataStream APIs and Table APIs as shown in the following example:

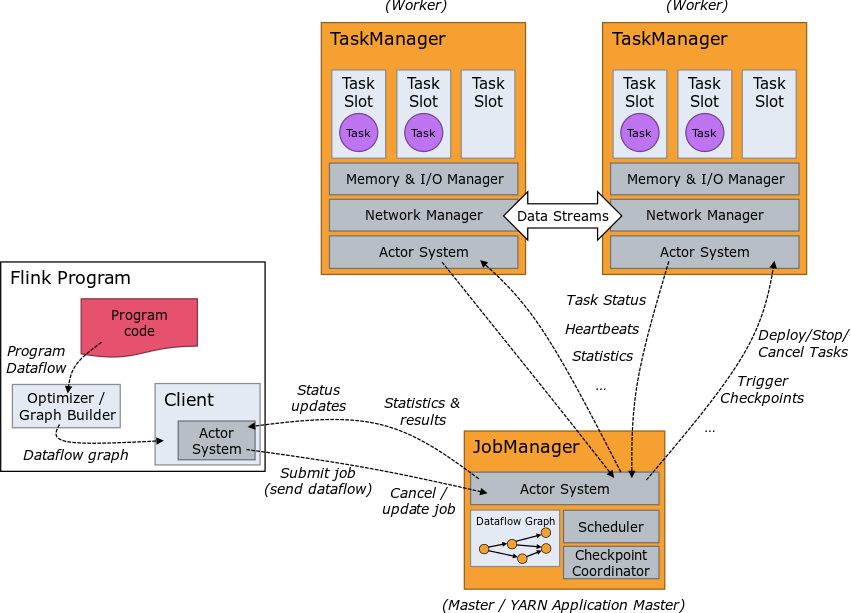
Flink Runtime
As mentioned, Flink supports streaming and batch processing. It’s now time to delve into the analysis of the main difference:
Streaming works with bounded or unbounded streams. In other words:
- Entire pipeline must always be running
- Input must be processed as it arrives
- Results are reported as they become ready
- Failure recovery resumes from a recent snapshot
- Flink can guarantee effectively exactly-once results when properly set up with Kafka
Batch works only with a bounded stream. In other words:
- Execution proceeds in stages and running as needed
- Input may be pre-sorted by time and key
- Results are reported at the end of the job
- Failure recovery does a reset and full restart
- Effectively exactly-once guarantees are more straightforward
Conclusions
In a nutshell, Apache Flink offers numerous benefits for stream processing and real-time data analytics. Its seamless integration with Kafka allows for efficient data ingestion and processing. Flink’s stateful processing capabilities simplify the management of distributed computations, making it easier to build complex streaming applications. The scalability and flexibility of Flink’s engine enable it to handle large-scale workloads with ease.
Additionally, Flink provides unified streaming and batch APIs, enabling developers to work with both types of data processing paradigms seamlessly. With the support of machine learning and standard SQL, Flink empowers users to perform advanced analytics and leverage familiar query languages. Overall, Apache Flink is a powerful and versatile platform that enables organizations to unlock the full potential of their real-time data.
Author: Luigi Cerrato, Software Engineer @ Bitrock
Thanks to the technical team of our sister’s company Radicalbit for their valuable contributions to this article.