
Last July we attended Lambda days 2022 in Krakow (Poland), one of the largest tech conferences in Europe with more than 50 talks and 500 attendees. The two-day event turned out to be a great experience for the whole team: undoubtedly, an incredible opportunity for networking and knowledge sharing. In this article, we now want to highlight some of the talks we enjoyed the most. You can’t skip it!
How your Brain Processes Code
Let’s start with a question: what happens in your brain when you acquire new information? We know that, when you first read something, this is stored in your short-term memory. This was discovered by George Miller in 1950. From his research, we know that this buffer is very small: it can hold between 5 and 9 things at the same time.
When information comes into your short-term memory, it stays there for a brief period, and then it’s sort of “sent over” to your working memory. Your working memory can be seen as the processor in your brain, the one responsible for the thinking process. When your working memory processes information, it cooperates with your long-term memory (which will offer you insights related to the information present in your working memory).
Given this introduction, we can say that, when we start learning a new programming language, here’s three different forms of confusion that are related to these memory areas. Let’s explore them in detail.
Long-term memory issues
Let’s start by looking at this program in APL:

What does this program do? Well, if you don’t know APL – which is perhaps true -, you have no clue, and it’s probably because you don’t recognize the syntax: you have no clue what the T stands for. It’s important here to point out the difference between “I don’t know” and “I don’t understand”. It is common, looking at code we are familiar with, to say “oh I don’t understand anything”; most of the time, you definitely can learn it, but you just don’t know it yet.
Short-term memory issues
Another example can be found in this Python program:
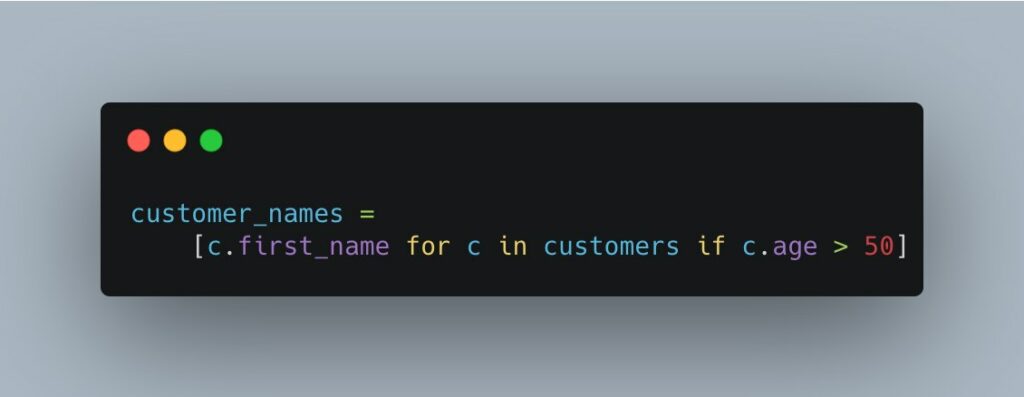
If you’re a Python programmer, this piece of code may be easy to understand. But if you come from a different background (for example Java), this syntax has a lot of elements for your short-term memory to keep track of. And if this is not familiar to you, it can overload your working memory. The effect? Easy: you recognize each single element, but you struggle in understanding how they come together.
Working memory issues
Let’s take this example in basic:

If you take each line individually, you may understand what it does. But if I ask you what’s the output of this program, well, that’s much harder to figure out! You will probably have to give N a value and process each line with the help of a piece of paper. In this case, you have all the information to understand the program, but it’s still hard.
How to approach each of those issues
Good news: there is a specific solution for all the above-mentioned issues:
- If you have long term memory issues, you must practice the syntax. Since you are learning a new language, you need a basic vocabulary.
- If you are struggling with short term memory, what you can do is try to use a syntax more familiar with your background. For example, this code has the exact same output that the one we saw earlier, but with a more Java friendly syntax:
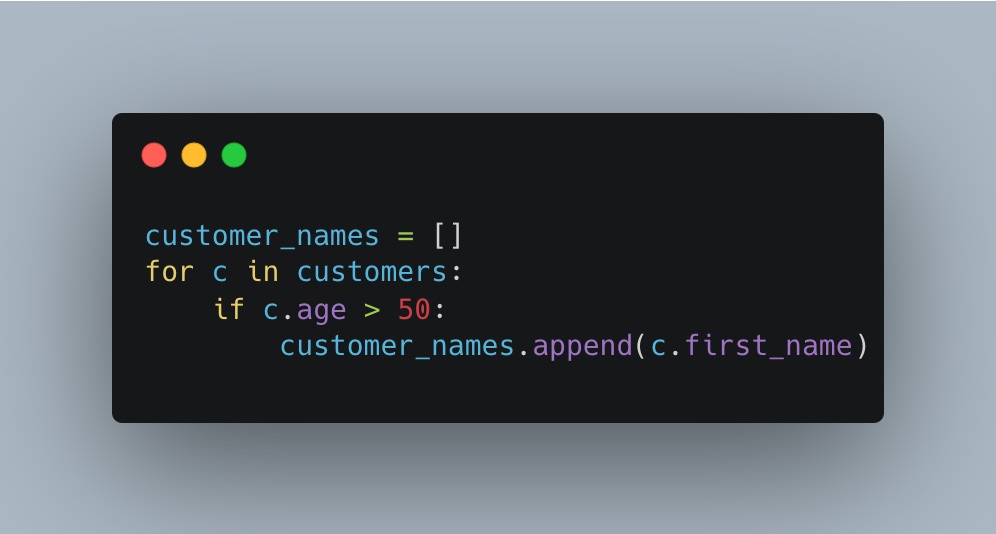
- As for the working memory issues, there are many things you can do to support your brain process. For instance, you can use a state table and process the code step by step: with this support, you can understand what’s going on.
This brief text is based on Felienne Hermans at Lambda Days 2022. To know more, you can read The Programmer’s Brain: What every programmer needs to know about cognition.
Debugging for Math Lovers
Our day-to-day jobs involve writing Scala code, testing it, and hoping that particular piece of code does what we intended. However, as any developer knows, this is not always the case, and we must spend a lot of time finding out what is wrong with what we have written.
One of the most inspiring talks we had the opportunity to see at the event is the one by Michał J. Gajda: a noteworthy contribution about debugging with a functional programmer mindset.
Let’s start from the beginning by defining what an error is!
Types of errors
The first type of error we can encounter is one of the most common ones when we approach a new language. We write some code, and it does not compile: we have written something that is syntactically wrong, and the compiler simply does not understand us. After fixing it, we start to play with some language libraries and the compiler starts to complain again: this time, about a type error. So, we do our search, we start to understand a little more about this new language type system, we fix the error, and the compiler is happy.
Our next step? We must test it! We thus write some unit tests – since we are good developers -, but the test fails. Our code gives the wrong result. Thankfully, our unit test catches the bug, and we can fix it.
Now that our code produces the correct result, it is time to make the production ready. Let’s try to test the load of data that our code can handle! We start with a small amount of data, and, from the beginning, we see that our code performance is too slow: we can’t handle the amount of data that we are expecting.
We see a common pattern here: each type of error is more difficult to fix than the previous one. Let’s try to formalize a definition of an error:
“Error is a difference between what we want, and what we got.”
Michał goes forward in his talk and classifies three other types of error (each of them worse than the other): Wrong concept was used to model reality – User experience is frustrating – Specification does not match user expectations.
Time-to-fix
After our classification of error types, let’s talk about the time we spend fixing an error. We have different tools at our disposal that can help, like our awesome text editor or our IDE, which can detect errors early, by changing the text colors or helping us in the debugging process.
As seen before, even the compiler could be one of our best friends, maybe a little rude sometimes, but it’s just trying to help us!
Another important metric to Michał is the time we need to discover an error. So, let’s do a quick list of errors and track the time needed to discover them:
- Lexer error, editor changes color (t > 1s)
- Syntax error, compiler parses (t > 10s)
- Processing error, after program is complete (1min < t < 1h)
- Latent misbehavior, after program sees new input in production (1mo < t < 1y)
There is an important result in the cognitive science field that we can bring to the table in our discussion on how to make less mistakes:
Time to learn from errors = 1/t^2
To obtain our main goal (i.e., do less errors), we should decrease latency between them! But how can we reduce the latency? This is not an easy task, but we can address it from a different point of view: the remaining errors are difficult to spot because our system is too complex.
Ultimate ways of reducing complexity
We are humans: our brain has some difficulties in following complex and long paths of reasoning. Especially for us, following a deep function call stack can be confusing and tedious: we need a lot of brain memory to maintain all the variables names, their value and how they interact. And this is only if we want to understand how a method works. What about a complex library function or, even worse, a complex Akka actor’s interaction?
Michał, at the end of his talk, gives some tips for when we are building new software:
- decrease the size of the problem: use short functions and modules, divide the side of the problem whenever possible
- decrease latency to comparison: follow editor hints, check type errors; the compiler is your friend
- reduce interaction between components of our system: low number of function arguments, use module interfaces, separation of concern
- group and reuse any abstraction: for example, monad, applicative and mathematics help us do it
These are things that some of us may take for granted, but it’s always helpful to have them in mind when we must do our job. These principles, indeed, could help us reduce the long and boring time we spend looking for an error!
This sum-up is based on Debugging for math lover by Michał J. Gajda: you can find all the slides here.
Static Analysis Tools Love Pure FP
Developers love writing code but, if there’s one thing that we all hate, this is when an error message is thrown by the application, and we can’t track the root cause of the bug. A static analysis tool helps the developer find these bugs, performing an analysis on the code at compilation time and suggesting how to address the problem through meaningful error messages. By attending Lambda Days, we discovered a new tool – a linter in this case – made by Joroen Engels for the elm programming language, which is now quite popular and appreciated within the community.
Linter headache
One thing that developers hate about linters is when they report false positives, and they end up inserting a bunch of:
linter-disable rule
The problem comes out when in big projects the linter can report thousands of messages, and, if only 10% of these are false positives, you’re going to waste a lot of time and make your code worse.
A linter is not an infallible tool, and those kinds of errors are caused by a lack of information from the code; when we miss information, it turns out to use presumptions based on probability. Let’s consider an example in javascript eslint:
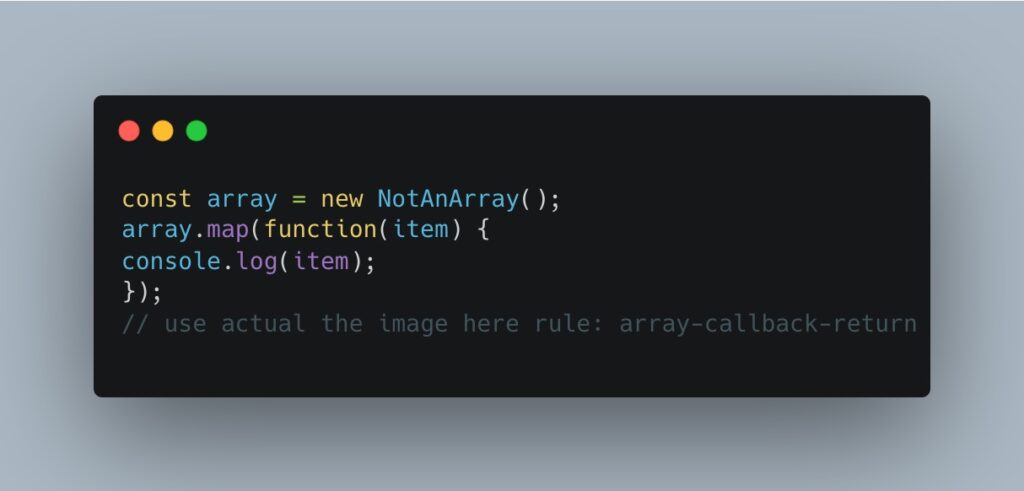
The rule reports when you’re using the function map over an array, and you miss the “return” statement. This could be a problem since you want to map something from A to B and not to “undefined”. In this case, the linter is making an incorrect presumption, since the array is not really an Array, and so the “map” function could be any function. This is due to missing information: actually, type information that Javascript doesn’t have.
The Elm way
How does Elm, a pure functional language, help solve the previous problem? Here’s the same function written in Elm:
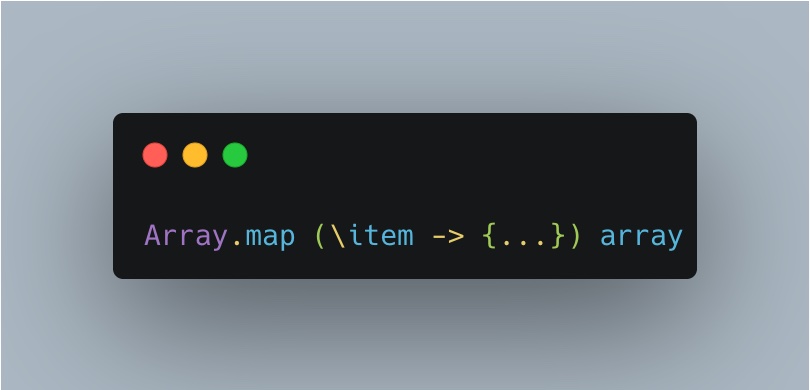
We can immediately spot some differences: “map” is explicitly called, there is no ambiguity, and array is guaranteed to be an Array. Another advantage we have using a pure functional language is that we don’t have to worry about side effects. Just look at this example:
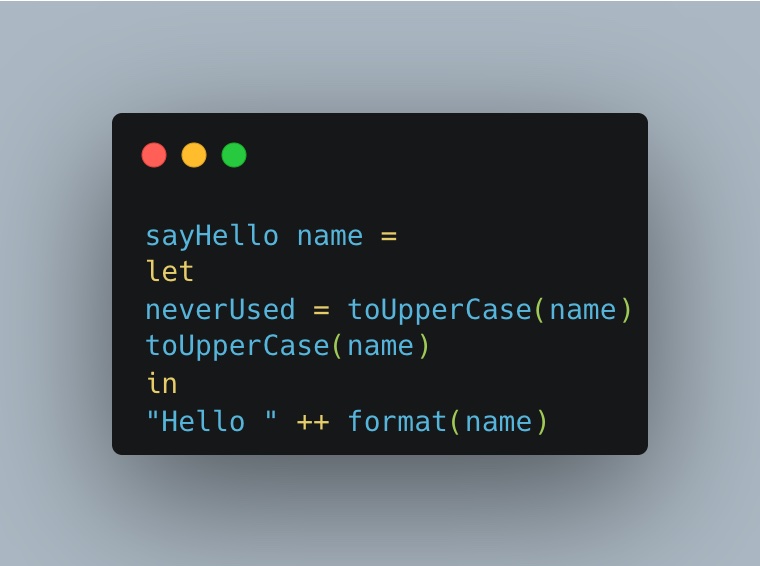
As you can see here, the function toUpperCase is called twice: the last one is unnecessary. We can safely delete it without worrying about any issue just because we know that it cannot have any side effects; this creates a domino effect when it’s possible to remove entire modules.
Summary
We’ve seen that compilers and type checkers remove surprises. Furthermore, pure functional programming simplifies a lot of analysis – such as code simplifications and dead code elimination – with less false positives. In a language like Javascript, we’ve seen that we must recreate guarantees with a lot of linter rules requiring configurations which, most of the time, will lead to frustration!
If you want to know more about Engels’ talk, don’t miss the recorded content available here.
Authors: Marco Righi, Software Engineer @ Bitrock – Alessandro Pisani, Software Engineer @ Bitrock