

Lo scorso luglio abbiamo partecipato al Lambda days 2022 di Cracovia (Polonia), una delle più grandi conferenze tecnologiche d’Europa con oltre 50 interventi e 500 partecipanti. Le due giornate si sono rivelate una grande esperienza per tutto il team: senza dubbio, un’incredibile opportunità di networking e di condivisione delle conoscenze. In questo articolo vogliamo evidenziare alcuni degli interventi che ci sono piaciuti di più. Non potete non partecipare!
Come il Cervello elabora il Codice
Partiamo da una domanda: cosa succede nel cervello quando si acquisiscono nuove informazioni? Sappiamo che quando si legge qualcosa per la prima volta, questa viene immagazzinata nella memoria a breve termine. Questo è stato scoperto da George Miller nel 1950. Dalle sue ricerche sappiamo che questo buffer è molto piccolo: può contenere da 5 a 9 cose contemporaneamente.
Quando un’informazione arriva nella memoria a breve termine, vi rimane per un breve periodo e poi viene “inviata” alla memoria di lavoro. La memoria di lavoro può essere vista come il processore del cervello, quello responsabile del processo di pensiero. Quando la memoria di lavoro elabora le informazioni, collabora con la memoria a lungo termine (che offrirà approfondimenti relativi alle informazioni presenti nella memoria di lavoro).
Fatta questa premessa, possiamo dire che, quando iniziamo a imparare un nuovo linguaggio di programmazione, possiamo sperimentare tre diverse forme di confusione legate a queste aree di memoria. Esploriamole in dettaglio.
Problemi di memoria a lungo termine
Cominciamo con questo programma in APL:

Cosa fa questo programma? Beh, se non conoscete l’APL – cosa probabilmente vera -, non ne avete la minima idea, e probabilmente poiché non riconoscete la sintassi, non avete la minima idea di cosa stia per T. È importante sottolineare la differenza tra “non so” e “non capisco”. Guardando il codice ci viene naturale dire “non capisco niente”, ma la maggior parte delle volte, sarebbe più corretto affermare che non lo si sa ancora.
Problemi di memoria a breve termine
Un altro esempio si trova in questo programma Python:
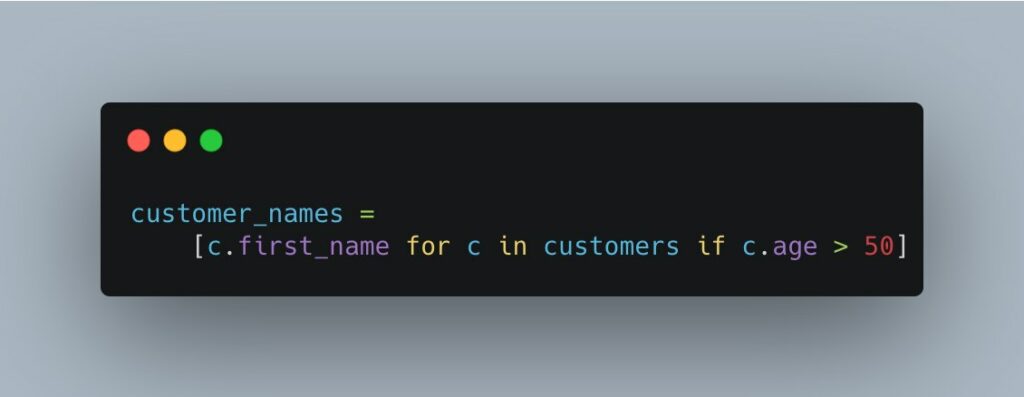
Se siete programmatori Python, questo pezzo di codice può essere facile da capire. Ma se provenite da un background diverso (ad esempio Java), questa sintassi presenta molti elementi che la vostra memoria a breve termine deve tenere sotto controllo. E se non vi è familiare, può sovraccaricare la vostra memoria di lavoro. L’effetto? Riconoscete ogni singolo elemento, ma fate fatica a capire come si combinano.
Problemi di memoria di lavoro
Prendiamo questo esempio di base:

Se prendete ogni riga singolarmente, potete capire cosa fa. Ma se vi chiedo qual è l’output di questo programma, beh, è molto più difficile da capire! Probabilmente dovrete dare un valore a N ed elaborare ogni riga con l’aiuto di un foglio di carta. In questo caso, avete tutte le informazioni per capire il programma, ma è comunque difficile.
Come affrontare ciascuno di questi problemi
La buona notizia è che esiste una soluzione specifica per tutti i problemi visti sopra:
- Se avete problemi di memoria a lungo termine, dovete esercitarvi con la sintassi. Poiché state imparando una nuova lingua, avete bisogno di un vocabolario di base.
- Se avete problemi di memoria a breve termine, potete provare a usare una sintassi più familiare al vostro background. Per esempio, questo codice ha lo stesso identico output di quello visto in precedenza, ma con una sintassi più simile a Java:
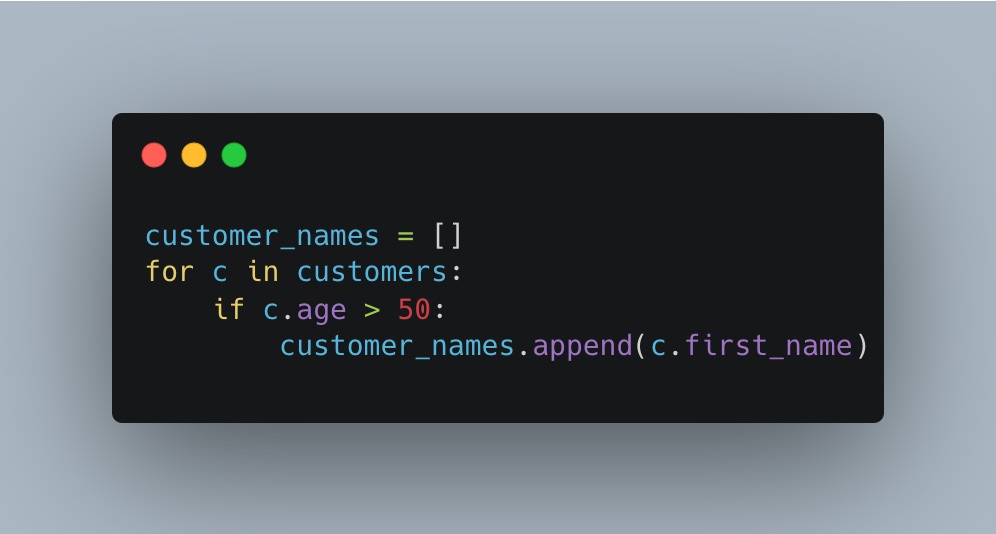
- Per quanto riguarda i problemi di memoria di lavoro, ci sono molte cose che si possono fare per supportare il processo cerebrale. Per esempio, si può usare una tabella di stato ed elaborare il codice passo per passo: con questo supporto, si può capire cosa sta succedendo.
Questo breve testo è basato su Felienne Hermans at Lambda Days 2022. Per saperne di più, potete leggere: The Programmer’s Brain: What every programmer needs to know about cognition.
Debugging per gli Amanti della Matematica
Il nostro lavoro quotidiano consiste nello scrivere codice Scala, testarlo e sperare che quel particolare pezzo di codice faccia ciò che vogliamo. Tuttavia, come ogni sviluppatore sa, non è sempre così e dobbiamo dedicare molto tempo a scoprire cosa c’è di sbagliato in ciò che abbiamo scritto.
Uno degli interventi più stimolanti che abbiamo avuto l’opportunità di vedere all’evento è quello di Michał J. Gajda: un contributo degno di nota sul debugging con una mentalità da programmatore funzionale.
Partiamo dall’inizio definendo cosa sia un errore!
Tipi di errori
Il primo tipo di errore che possiamo incontrare è uno dei più comuni quando ci avviciniamo a un nuovo linguaggio. Scriviamo del codice e non si compila: abbiamo scritto qualcosa di sintatticamente sbagliato e il compilatore semplicemente non ci capisce. Dopo aver risolto il problema, iniziamo a giocare con le librerie del linguaggio e il compilatore inizia a lamentarsi di nuovo: questa volta, per un errore di tipo. Quindi, facciamo la nostra ricerca, iniziamo a capire un po’ di più il sistema di caratteri di questo nuovo linguaggio, correggiamo l’errore e il compilatore è contento.
Il nostro prossimo passo? Dobbiamo testarlo! Scriviamo quindi alcuni test unitari – dato che siamo bravi sviluppatori -, ma il test fallisce. Il nostro codice dà un risultato sbagliato. Fortunatamente, il nostro test unitario individua il bug e possiamo risolverlo.
Ora che il nostro codice produce il risultato corretto, è il momento di preparare la produzione. Proviamo a testare il carico di dati che il nostro codice può gestire! Iniziamo con una piccola quantità di dati e, fin dall’inizio, notiamo che le prestazioni del nostro codice sono troppo lente: non riusciamo a gestire la quantità di dati che ci aspettiamo.
Vediamo uno schema comune: ogni tipo di errore è più difficile da risolvere rispetto al precedente. Proviamo a formalizzare una definizione di errore:
“L’errore è una differenza tra ciò che vogliamo e ciò che otteniamo”.Michał prosegue nel suo discorso e classifica altri tre tipi di errore (ognuno peggiore dell’altro): È stato usato un concetto sbagliato per modellare la realtà – L ‘esperienza dell’utente è frustrante – Le specifiche non corrispondono alle aspettative dell’utente.
Tempo per la correzione
Dopo la classificazione dei tipi di errore, parliamo del tempo che impieghiamo per correggere un errore. Abbiamo a disposizione diversi strumenti che possono aiutarci, come il nostro editor di testo o il nostro IDE, che possono rilevare gli errori in anticipo, cambiando i colori del testo e aiutandoci nel processo di debug.
Come abbiamo visto prima, anche il compilatore potrebbe essere uno dei nostri migliori amici, forse un po’ scortese a volte, ma cerca solo di aiutarci!
Un altro parametro importante per Michał è il tempo necessario per scoprire un errore. Quindi, facciamo un rapido elenco di errori e teniamo traccia del tempo necessario per scoprirli:
- Errore del lesser, l’editor cambia colore(t > 1s)
- Errore di sintassi, il compilatore esegue il parsing(t > 10s)
- Errore di elaborazione, dopo il completamento del programma (1min < t < 1h)
- Comportamento scorretto latente, dopo che il programma vede un nuovo input in produzione (1mo < t < 1y)
Esiste un importante risultato nel campo delle scienze cognitive che possiamo utilizzare nella nostra discussione su come fare meno errori:
Tempo per imparare dagli errori = 1/t^2
Per ottenere il nostro obiettivo principale (cioè fare meno errori), dovremmo diminuire la latenza tra di essi! Ma come possiamo ridurre la latenza? Non è un compito facile, ma possiamo affrontarlo da un altro punto di vista: gli errori rimanenti sono difficili da individuare perché il nostro sistema è troppo complesso.
Gli ultimi modi per ridurre la complessità
Siamo esseri umani: il nostro cervello ha qualche difficoltà a seguire percorsi di ragionamento complessi e lunghi. In particolare per noi, seguire uno stack di chiamate a funzioni profonde può essere complesso e noioso: abbiamo bisogno di molta memoria per memorizzare tutti i nomi delle variabili, il loro valore e il modo in cui interagiscono. E questo solo se vogliamo capire come funziona un metodo. Che dire di una complessa funzione di libreria o, peggio ancora, di una complessa interazione di un attore Akka?
Michał, alla fine del suo intervento, ci ha dato alcuni consigli per quando costruiamo un nuovo software:
- ridurre la dimensione del problema: utilizzare funzioni e moduli brevi, suddividere il problema quando possibile
- diminuire la latenza al confronto: seguire i suggerimenti dell’editor, controllare gli errori di tipo; ricordatevi che il compilatore è vostro amico
- ridurre l’interazione tra i componenti del nostro sistema: basso numero di argomenti delle funzioni, uso di interfacce di moduli, separazione delle preoccupazioni
- raggruppare e riutilizzare qualsiasi astrazione: ad esempio, monade, applicativo e matematica ci aiutano a farlo.
Sono cose che alcuni di noi possono dare per scontate, ma è sempre utile averle in mente quando dobbiamo fare il nostro lavoro. Questi principi, infatti, potrebbero aiutarci a ridurre il lungo e noioso tempo che passiamo a cercare un errore!
Questo riassunto è basato su: Debugging for math lover by Michał J. Gajda: potete trovare tutte le slide qui.
Gli Strumenti di Analisi Statica amano il FP Puro
Gli sviluppatori amano scrivere codice ma, se c’è una cosa che tutti odiamo, è quando un messaggio di errore viene lanciato dall’applicazione e non si riesce a risalire alla causa principale del bug. Uno strumento di analisi statica aiuta lo sviluppatore a trovare questi bug, eseguendo un’analisi del codice in fase di compilazione e suggerendo come risolvere il problema attraverso messaggi di errore significativi. Partecipando ai Lambda Days, abbiamo scoperto un nuovo strumento – un linter in questo caso – realizzato da Joroen Engels per il linguaggio di programmazione elm, che ora è piuttosto popolare e apprezzato all’interno della comunità.
Mal di testa da linter
Una cosa che gli sviluppatori odiano dei linter è quando segnalano falsi positivi e finiscono per inserire un mucchio di regole:
regola linter-disable
Il problema si presenta quando in progetti di grandi dimensioni il linter può segnalare migliaia di messaggi e, se solo il 10% di questi sono falsi positivi, si rischia di perdere molto tempo e di peggiorare il codice.Un linter non è uno strumento infallibile e questo tipo di errori sono causati da una mancanza di informazioni dal codice; quando mancano le informazioni, si ricorre a presunzioni basate sulla probabilità. Consideriamo un esempio in javascript eslint:
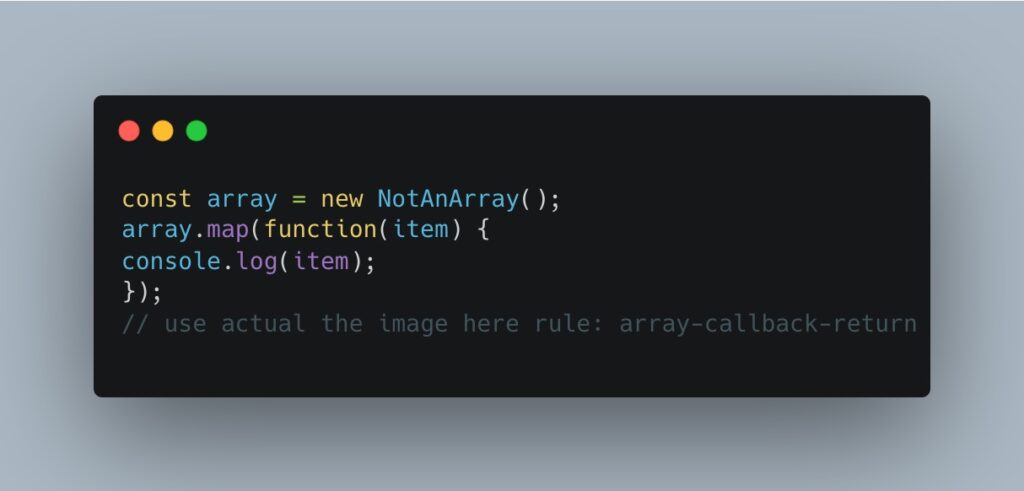
La regola viene segnalata quando si utilizza la funzione map su un array e manca l’istruzione “return”. Questo potrebbe essere un problema, dato che si vuole mappare qualcosa da A a B e non a “undefined”. In questo caso, il linter sta facendo una supposizione errata, poiché l’array non è realmente un array e quindi la funzione “map” potrebbe essere una funzione qualsiasi. Questo è dovuto a informazioni mancanti: in realtà, informazioni sul tipo che Javascript non ha.
La Via di Elm
Come fa Elm, un linguaggio funzionale puro, a risolvere il problema precedente? Ecco la stessa funzione scritta in Elm:
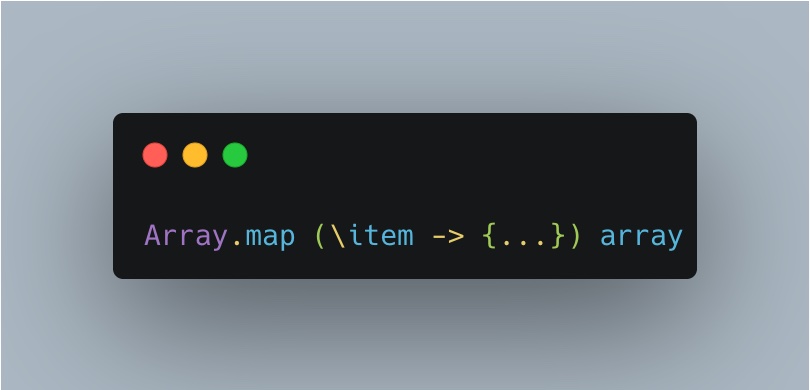
Possiamo immediatamente notare alcune differenze: “map” viene chiamato esplicitamente, non c’è ambiguità e array è garantito come array. Un altro vantaggio che abbiamo utilizzando un linguaggio funzionale puro è che non dobbiamo preoccuparci degli effetti collaterali. Guardate questo esempio:
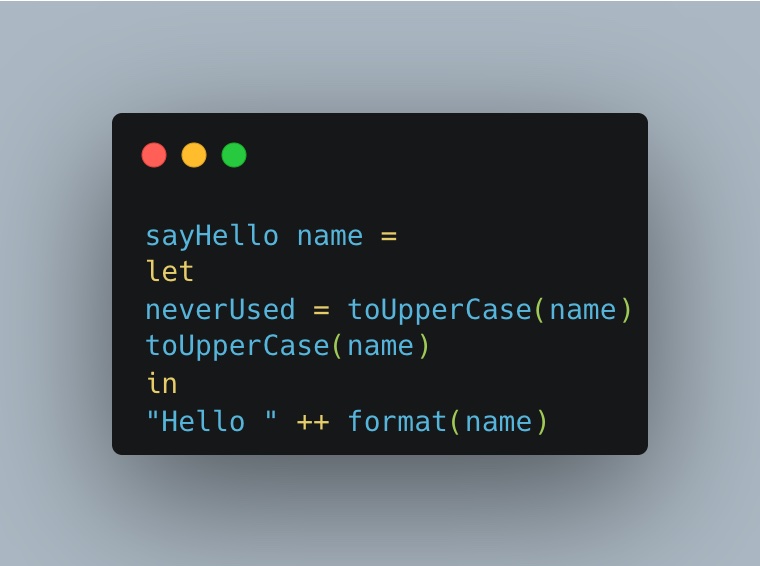
Come si può notare, la funzione toUpperCase viene chiamata due volte: l’ultima non è necessaria. Possiamo tranquillamente eliminarla senza preoccuparci di alcun problema solo perché sappiamo che non può avere effetti collaterali; questo crea un effetto domino quando è possibile rimuovere interi moduli.
Sintesi
Abbiamo visto che i compilatori e i type checker eliminano le brutte sorprese. Inoltre, la programmazione funzionale pura semplifica molte analisi, come la semplificazione del codice e l’eliminazione del codice morto, con meno falsi positivi. In un linguaggio come Javascript, abbiamo visto che dobbiamo ricreare garanzie con un sacco di regole di linterno che richiedono configurazioni che, il più delle volte, portano alla frustrazione!
Se volete saperne di più sull’intervento di Engels, non perdetevi il contenuto registrato disponibile qui.
Autori: Marco Righi, Software Engineer @ Bitrock – Alessandro Pisani, Software Engineer @ Bitrock