

Il problema
La popolarità dell’architettura a microservizi è aumentata enormemente negli ultimi tempi, ma questo comporta nuove sfide.
Una di queste è il monitoraggio. In uno dei nostri progetti, abbiamo utilizzato un connettore Kafka per intercettare le modifiche nel nostro database e scrivere i dati in un topic. Si trattava di un componente molto importante del sistema, quindi dovevamo valutare attentamente il suo stato di salute.
Soluzione
Nella nostra prima versione, abbiamo creato un CronnJob di Kubernetes con un semplice script di shell che controlla lo stato del connettore e, alla fine, lo cancella e lo riavvia.
Questo ha funzionato abbastanza bene; tuttavia, è diverso da come gli altri servizi vengono controllati con Kubernetes.
Il connettore è stato distribuito con Kubernetes; la cosa più naturale da fare è quindi usare k8s per monitorare i pod ed eventualmente riavviarlo.
Il framework Kafka Connect è dotato di API Rest e una di queste fornisce lo stato dei connettori:
cioè: https: //bitrock.it/wp-content/blog/monitoring-kafka-connector-with-kubernetes/
Questo sembra risolvere il nostro problema… Ma è davvero così?
Il controllo dello stato di salute di Kubernetes controlla il codice di stato HTTP; il problema è che l’API del connettore Kafka restituisce lo stato HTTP 200.
Ad esempio, se il task è faliito, l’API restituirà:
HTTP/1.1 200 OK
{“state”:”FAILED”,”id”:1,”worker_id”:”192.168.86.101:8083″}
In questo caso, dal punto di vista di Kubernetes, tutto va bene.
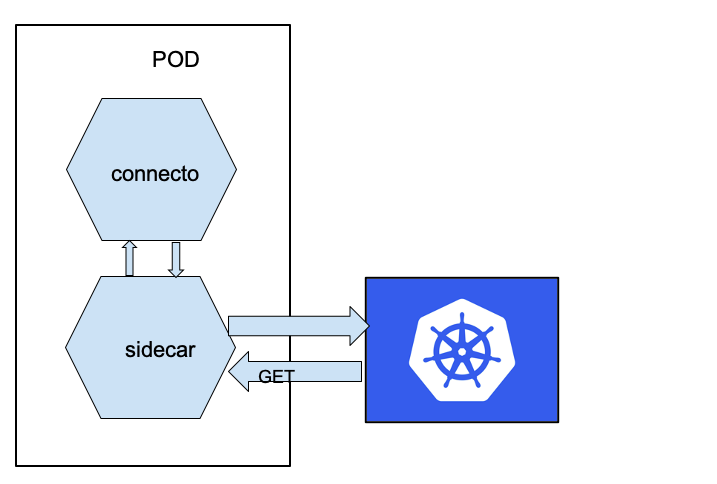
La soluzione che ha funzionato bene per noi consiste nell’aggiungere un contenitore sidecar che si assume la responsabilità di esporre lo stato del task del connettore.
Il pattern sidecar consente di estrarre alcune funzionalità dell’applicazione in un componente diverso. Per esempio, possiamo separare il livello di autenticazione dal nostro componente “principale” che contiene la logica di business o, come nel nostro caso, estrae la parte di monitoraggio.
Il nostro obiettivo è ottenere qualcosa di simile:
Prima di tutto, abbiamo creato una semplice applicazione che si occupa di chiamare l’API del connettore e di esporre un’API per Kubernetes (abbiamo usato una semplice applicazione Python usando Flask – ma si può usare quello che si vuole). Qualcosa del genere:
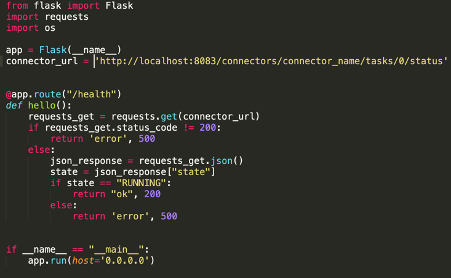
Come si può vedere, il codice è molto semplice.
L’applicazione svolge due compiti diversi: innanzitutto, espone un endpoint al percorso “/health” che sarà richiamato periodicamente da Kubernetes; in secondo luogo, controlla lo stato di un task ed eventualmente restituisce un Internal Server Error, nel caso in cui lo stato HTTP del connettore non fosse 200 o se lo stato non fosse “RUNNING”.
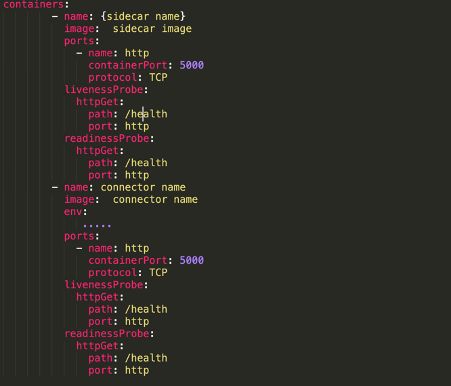
Ora, questa applicazione deve essere distribuita negli stessi pod del connettore. Questo può essere fatto aggiungendo al nostro file deployment.yaml il contenitore che contiene la nostra applicazione Python:
Conclusioni
Il risultato logico?
Entrambi i container espongono il controllo dello stato di salute del sidecar, poiché Kubernetes non riavvia l’intero pod se un container è attivo; esponendo la stessa API, il destino di entrambi i container sarebbe lo stesso.
Una volta che il connettore è in stato FAILED, Kubernetes riavvia il pod.
Alcuni cloud provider potrebbero fornire una soluzione integrata per problemi come questo; ma se non è possibile utilizzarla, per qualsiasi motivo, questa può essere una possibile soluzione.
Autore: Marco Tosini, Principal Engineer @Bitrock