

The recent hype surrounding Apache Flink especially after the Kafka Summit 2023 in London sparked our curiosity and prompted us to better understand the reasons for such enthusiasm. Specifically, we wanted to know how much Flink differs from Kafka Streams, the learning curve, and the use cases where these technologies can be applied. Both solutions offer powerful tools for processing data in real-time, but they have significant differences in terms of purpose and features.
Processing Data: Apache Flink vs Kafka Streams
Apache Flink is an open-source, unified stream and batch data processing framework. It is a distributed computing system that can process large amounts of data in real-time with fault tolerance and scalability.
On the other hand, Kafka Streams is a specific library built into Apache Kafka that provides a framework for building different applications and microservices that process data in real-time.
Kafka Streams provides a programming model that allows developers to define transformation operations over data streams using DSL-like functional APIs. This model is based on two types of APIs: the DSL API and the Processor API. The DSL API is built on top of the Processor API and is recommended especially for beginners. The Processor API is meant for advanced applications development and involves the employment of low-level Kafka capabilities.
Kafka Streams was created to provide a native option for processing streaming data without the need for external frameworks or libraries. A Kafka Streams job is essentially a standalone application that can be orchestrated at the user’s discretion.
Main Differences
As previously mentioned, Flink is a running engine on which processing jobs run, while Kafka Streams is a Java library that enables client applications to run streaming jobs without the need for extra distributed systems besides a running Kafka cluster. This implies that if users want to leverage Flink for stream processing, they will need to work with two systems.
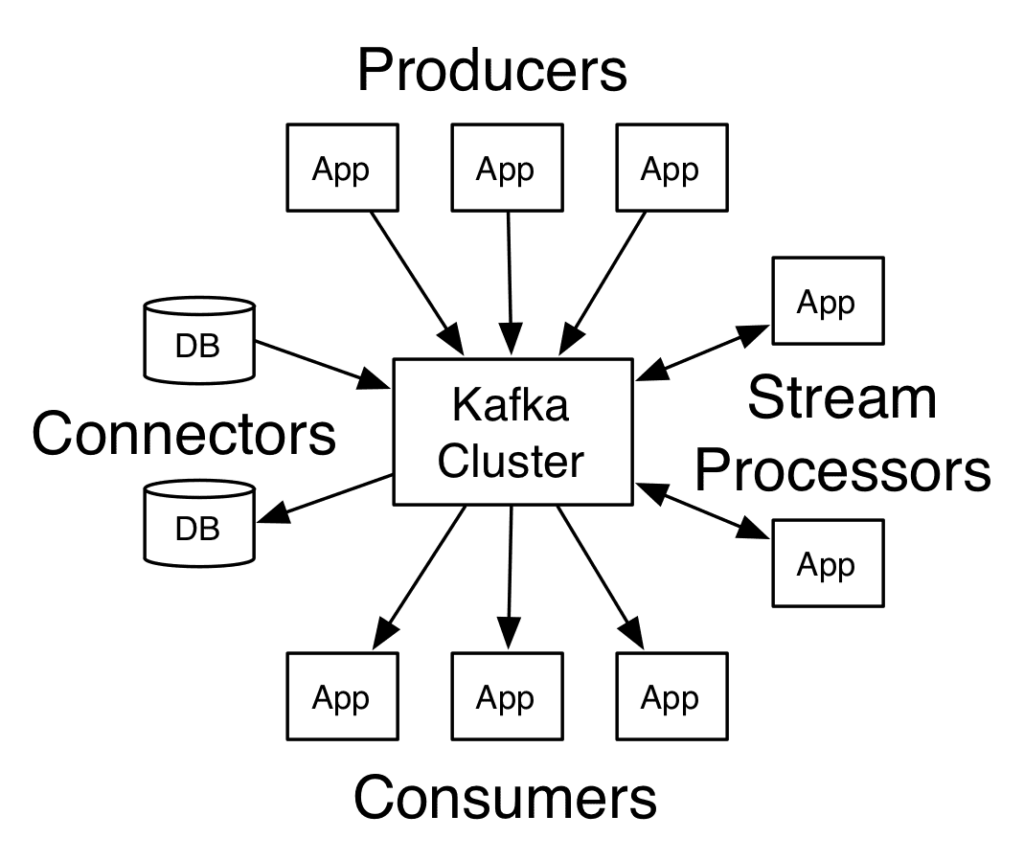
In addition, both Apache Flink and Kafka Streams offer high-level APIs (Flink DataStream APIs, Kafka Streams DSL) as well as advanced APIs for more complex implementations, such as the Kafka Streams Processor APIs.
Now, let’s take a closer look at the main differences between Apache Kafka and Flink.
- Integrations
How do these systems establish connections with the external world? Apache Flink offers native integration with a wide range of technologies, including Hadoop, RDBMS, Elasticsearch, Hive, and more. This integration is made possible through the utilization of the Flink Connectors suite, where these connectors function as sources within Flink pipelines.
Kafka Streams is tightly integrated with Kafka for processing streaming data. The Kafka ecosystem provides Kafka Connect, which allows for the integration of external data sources as events are journaled into topics. For example, using the Kafka Connect Debezium connector, users can stream Change Data Capture stream events into a Kafka topic. A Kafka Stream topology can then consume this topic and apply processing logic to meet specific business requirements.
- Scalability
Apache Flink is an engine designed to scale out across a cluster of machines, and its scalability is only bound by the cluster definition. On the other hand, while it is possible to scale Kafka Streams applications out horizontally, the potential scalability is limited to the maximum number of partitions owned by the source topics.
- Fault tolerance and reliability
Both Kafka Streams and Apache Flink ensure high availability and fault tolerance, but they employ different approaches. Kafka Stream delegates to the capabilities of Kafka brokers. Apache Flink depends on external systems for persistent state management by using tiered storage and it relies on systems like Zookeeper or Kubernetes for achieving high availability.
- Operation
Kafka Stream as a library, requires users to write their applications and operate them as they would normally. For example, a Kubernetes deployment can be used for this purpose and by adding Horizontal Pod Autoscaling (HPA) , it can enable horizontal scale-out.
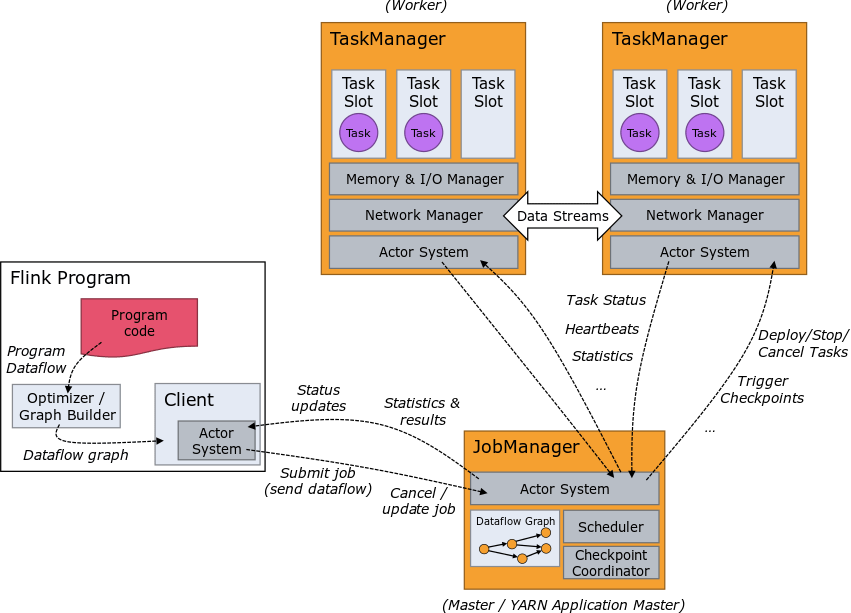
Apache Flink is an engine that needs to be orchestrated in order to enable Flink workloads. Currently, Flink users can leverage a Kubernetes Flink operator developed by the community to integrate Flink executions natively over Kubernetes clusters.
- Windowing
Both Kafka Stream and Flink support windowing (tumbling, sliding, session) with some differences:
- Kafka Stream manages windowing based on event time and processing time.
- Apache Flink manages flexible windowing based on event time, processing time, and ingestion time.
Use Cases
While both frameworks offer unique features and benefits, they have different strengths when it comes to specific use cases.
Apache Flink is the go-to choice for:
- Real-Time Data Processing: real-time event analysis, performance monitoring, anomaly detection, and IoT sensor data processing.
- Complex Event Processing: pattern recognition, aggregation, and related event processing, such as detecting sequences of events or managing time windows.
- Batch Data Processing: report generation and archives data processing.
- Machine Learning on Streaming Data: train and apply machine learning models on streaming data, enabling real-time processing of machine learning outcomes and predictions.
Kafka Stream is the go-to choice for:
- Microservices Architectures: particularly leveraged for the implementations of event-driven patterns like event sourcing or CQRS.
- Kafka Input and Output Data Processing: transform, filter, aggregate or enrich input data and produce output data in real-time.
- Log Data Processing: analyze website access logs, monitor service performance, or detect significant events from system logs.
- Real-time Analytics: data aggregation, real-time reporting, and triggering event-based actions
- Machine Learning: train and apply machine learning models on streaming data for real-time scoring.
Learning curve and resources
The learning curve of a technology is not always an objective fact and can vary depending on various factors. However, we have attempted to provide a general overview based on factors like resources availability and examples.
The basic concepts of Kafka Streams, such as KStreams (data streams) and KTables (data tables), can be easily grasped. While the mastery of advanced functions such as the aggregation of time windows or the processing of correlated events, may require further exploration. The official Kafka Streams documentation, available on Kafka’s website at https://kafka.apache.org/documentation/streams/ serves as a valuable reference for learning, exploring and leveraging all its capabilities.
To get started with Apache Flink, it is recommended to learn the basic programming model, including working with data streams and data sets. Once again, mastering advanced concepts such as state management, time windows, or grouping, may require additional study and practice time. The official Flink documentation available on Confluent’s website at https://nightlies.apache.org/flink/flink-docs-stable/ serves as a comprehensive resource for learning and exploring as well.
Conclusions
To cut a long story short, Apache Flink and Kafka Streams are two open-source frameworks with their strengths and weaknesses for stream processing that can process large amounts of data in real-time.
Apache Flink is a fully-stateful framework that can store the state of the data during processing, making it ideal for applications that require complex calculations or data consistency. Kafka Streams is a partially-stateful framework and it is ideal for applications that require low latency or to process large amounts of data. Apache Flink is a more generalized framework that can be used for various applications, including log processing, real-time data processing, and data analytics. Kafka Streams is more specific to stream processing.
We can conclude affirming that the best framework for a specific application will depend on the specific needs of the application.
Author: Luigi Cerrato, Software Engineer @ Bitrock
Thanks to the technical team of our sister company Radicalbit for their valuable contributions to this article.