

In the field of natural language processing, the ability to fine-tune pre-trained language models has revolutionized the way we approach specific tasks. TinyBERT, a compact and efficient version of the GPT-2 model, provides an excellent balance between performance and computational efficiency.
This article will guide you through the process of fine-tuning TinyBERT using Python on the Databricks platform, harnessing the power of distributed computing and MLflow for experiment tracking.
Understanding TinyBERT
TinyBERT is part of the family of compressed BERT models, designed to be lighter and faster while retaining much of the performance of the original BERT model. Here are some of the key features of TinyBERT:
- Size and Speed: TinyBERT is significantly smaller than the original BERT model. For example, TinyBERT6 (with 6 layers) has approximately 66 million parameters, compared to BERT-base’s 110 million. This reduction in size translates into faster inference times and lower computational requirements.
- Efficiency: Despite its smaller size, TinyBERT retains a high percentage of BERT’s performance for many natural language understanding tasks.
- Architecture: TinyBERT uses a similar architecture to BERT but with fewer layers. It typically has 4 or 6 layers compared to BERT-base’s 12 layers.
- Training Process: TinyBERT is trained using a two-stage learning framework that includes general distillation and task-specific distillation. It employs both data augmentation and knowledge distillation techniques.
- Use Cases: It’s particularly useful for tasks that require fast inference or deployment on devices with limited computing resources, such as mobile devices or edge computing scenarios.
- Versatility: TinyBERT can be applied to various natural language understanding tasks, including text classification, named entity recognition, and question answering.
- Customization: The TinyBERT approach allows for creating models of different sizes to fit specific requirements, balancing between model size, speed, and accuracy.
Prerequisites
Before you start fine-tuning TinyBERT, make sure you have:
- A Databricks account with access to GPU-enabled clusters
- Familiarity with Python and basic machine learning concepts
- The following libraries installed: transformers, datasets, torch, mlflow
Setting Up the Databricks Environment
- Create a new cluster with GPU support (e.g., using g4dn.xlarge instances)
- Install the required libraries using the cluster’s library management interface
Preparing the Dataset
For this tutorial, we’ll use the WikiText-103 dataset. Here’s how we’ll prepare it:
- Load the dataset using the Hugging Face dataset library
- Tokenize the text data using the TinyBERT tokenizer
- Group the tokenized data into chunks suitable for language modelling
Loading and Preprocessing TinyBERT
We’ll use the Hugging Face Transformers library to load the pre-trained TinyBERT model and tokenizer:

It’s worth noting that TinyBERT uses the same tokenizer as BERT, allowing for seamless integration and comparison between the two models.
Fine-Tuning Process
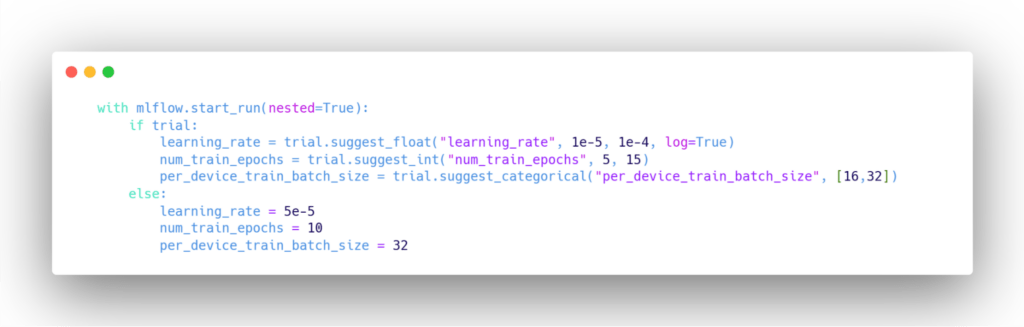
- Setting up the training arguments (learning rate, batch size, number of epochs, etc.)
- Creating a training loop using the Hugging Face Trainer class
- Implementing early stops and checkpoints to save the best model
When fine-tuning TinyBERT, it’s important to take into account the smaller size of the model. This means that you may need to adjust hyperparameters differently than you would for larger models. For example:
- You may be able to use larger batch sizes due to the smaller memory footprint of the model.
- Learning rates may need to be carefully tuned to achieve optimal performance
- You may need to apply the two-stage learning framework as described in the TinyBERT paper
Logging Metrics to Databricks MLflow
After fine-tuning TinyBERT, it’s crucial to log the model’s performance metrics for tracking and comparison. Databricks MLflow provides an excellent platform for this purpose. Here’s how we can log metrics during the training process:
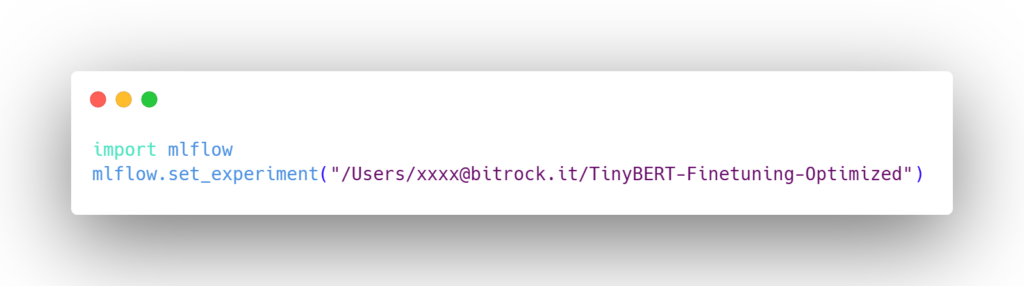
- Set up MLflow tracking: First, we need to set up MLflow tracking in our Databricks notebook:
- Log metrics during training: We can modify our training loop to log metrics after each epoch or at regular intervals:

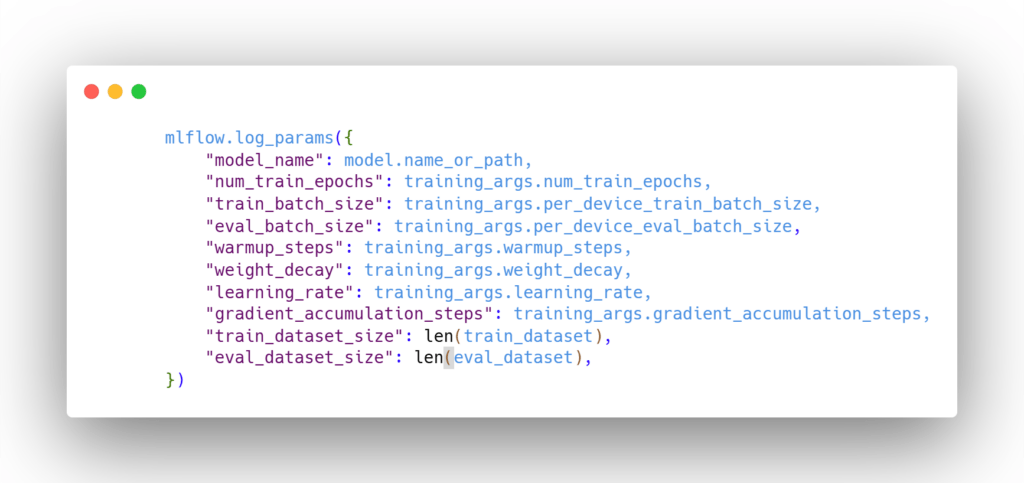
- Log model parameters: We should also log the model’s hyperparameters for reference:
- Log the model itself: After training, we can log the entire model to MLflow:
- Visualise metrics in Databricks: Once logged, you can easily visualise these metrics in the Databricks MLflow UI. This allows you to:
- Compare different runs with various hyperparameters
- Track the model’s performance over time
- Identify the best performing model configurations
- Retrieve logged models: You can later retrieve the logged model for inference or further analysis:
By consistently logging metrics, parameters, and models to MLflow, you create a comprehensive record of your TinyBERT fine-tuning experiments. This practice enhances reproducibility, facilitates collaboration, and streamlines the process of selecting the best model for deployment.
Remember, when comparing TinyBERT’s performance metrics, it’s valuable to benchmark against both the base TinyBERT model and larger BERT variants. This will give you a clear picture of the trade-offs between model size and performance for your specific task.
Best Practices and Tips for TinyBERT
- Start with a small subset of your data to ensure your pipeline works correctly before scaling up
- Use gradient accumulation and mixed-precision training to manage memory constraints
- Evaluate your model regularly during training to catch overfitting early
- Consider the trade-off between model size and performance. TinyBERT may not always match the performance of larger models, but its efficiency can be a significant advantage in many real-world applications
- Experiment with different learning rates and batch sizes, as TinyBERT’s optimal hyperparameters might differ from those of larger models
- Apply task-specific distillation as described in the TinyBERT paper to potentially improve performance
Conclusions
Fine-tuning TinyBERT on Databricks provides a powerful way to create efficient, custom language models tailored to your specific needs. By leveraging the distributed computing capabilities of Databricks and the experiment tracking of MLflow, you can efficiently manage the fine-tuning process and produce high-quality models.
TinyBERT’s smaller size and faster inference times make it an excellent choice for applications where efficiency is critical, while still maintaining competitive performance on many natural language understanding tasks.
Main Author: Aditya Mohanty, Data Scientist @ Bitrock