

Nel campo dell’elaborazione del linguaggio naturale, la possibilità di mettere a punto modelli linguistici pre-addestrati ha rivoluzionato il modo di affrontare specifici compiti. TinyBERT, una versione compatta ed efficiente del modello GPT-2, offre un eccellente equilibrio tra prestazioni ed efficienza computazionale.
Questo articolo vi guiderà attraverso il processo di messa a punto di TinyBERT utilizzando Python sulla piattaforma Databricks, sfruttando la potenza del calcolo distribuito e MLflow per il tracciamento degli esperimenti.
Comprendere TinyBERT
TinyBERT fa parte della famiglia di modelli BERT compressi, progettati per essere più leggeri e veloci, pur mantenendo gran parte delle prestazioni del modello BERT originale. Ecco alcune delle caratteristiche principali di TinyBERT:
- Dimensioni e velocità: TinyBERT è significativamente più piccolo del modello BERT originale. Ad esempio, TinyBERT6 (con 6 strati) ha circa 66 milioni di parametri, rispetto ai 110 milioni di BERT-base. Questa riduzione delle dimensioni si traduce in tempi di inferenza più rapidi e in minori requisiti computazionali.
- Efficienza: nonostante le dimensioni ridotte, TinyBERT mantiene un’alta percentuale delle prestazioni di BERT per molti compiti di comprensione del linguaggio naturale.
- Architettura: TinyBERT utilizza un’architettura simile a quella dI BERT, ma con un numero inferiore di livelli. In genere ha 4 o 6 strati rispetto ai 12 strati del BERT-base.
- Processo di addestramento: TinyBERT viene addestrato utilizzando una struttura di apprendimento a due fasi che comprende una distillazione generale e una distillazione specifica per il compito. Utilizza tecniche di aumento dei dati e di distillazione della conoscenza.
- Casi d’uso: è particolarmente utile per le attività che richiedono un’inferenza rapida o l’impiego su dispositivi con risorse di calcolo limitate, come i dispositivi mobili o gli scenari di edge computing.
- Versatilità: TinyBERT può essere applicato a diversi compiti di comprensione del linguaggio naturale, tra cui la classificazione di testi, il riconoscimento di entità nominali e la risposta a domande.
- Personalizzazione: l’approccio TinyBERT consente di creare modelli di dimensioni diverse per soddisfare esigenze specifiche, bilanciando tra dimensioni del modello, velocità e precisione.
Prerequisiti
Prima di iniziare la messa a punto di TinyBERT, assicurarsi di avere:
- Un account Databricks con accesso ai cluster abilitati alle GPU;
- Familiarità con Python e con i concetti di base dell’apprendimento automatico;
- Le seguenti librerie installate: transformers, datasets, torch, mlflow.
Configurazione dell’ambiente Databricks
- Creare un nuovo cluster con supporto GPU (ad esempio, utilizzando le istanze g4dn.xlarge).
- Installare le librerie necessarie tramite l’interfaccia di gestione delle librerie del cluster.
Preparazione del Dataset
Per questa esercitazione, utilizzeremo il dataset WikiText-103. Ecco come prepararlo:
- Caricare il dataset utilizzando la libreria Hugging Face Dataset
- Eseguire la tokenizzazione dei dati di testo utilizzando il tokenizzatore TinyBERT
- Raggruppare i dati tokenizzati in parti adatte alla modellazione linguistica
Caricamento e preparazione di TinyBERT
Utilizzeremo la libreria Hugging Face Transformers per caricare il modello TinyBERT pre-addestrato e il tokenizer:

È importante notare che TinyBERT utilizza lo stesso tokenizer di BERT, permettendo un’integrazione perfetta e un confronto tra i due modelli.
Processo di Fine-Tuning
Il processo di messa a punto comprende:
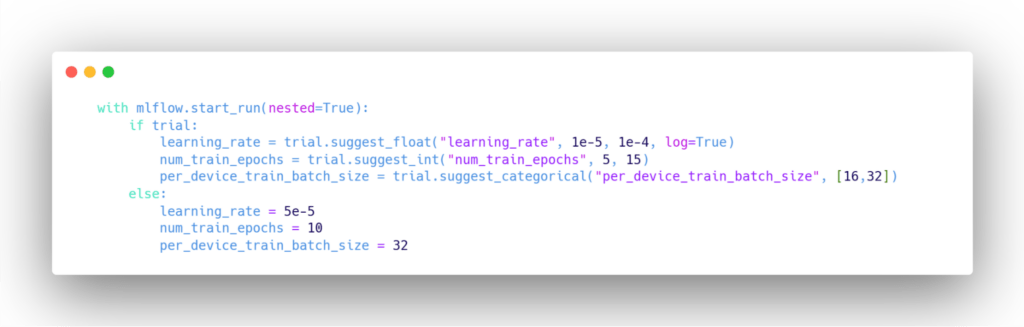
- Impostazione degli argomenti di addestramento (tasso di apprendimento, dimensione del batch, numero di epoche, ecc.).
- Creazione di un ciclo di addestramento utilizzando la classe Hugging Face Trainer
- Implementazione degli arresti anticipati e checkpoint per salvare il modello migliore.
Quando si mette a punto TinyBERT, è importante tenere conto delle sue dimensioni ridotte. Ciò significa che potrebbe essere necessario regolare gli iperparametri in modo diverso rispetto ai modelli più grandi. Ad esempio:
- È possibile utilizzare batch di dimensioni maggiori grazie al minore ingombro di memoria del modello.
- Per ottenere prestazioni ottimali, potrebbe essere necessario regolare attentamente i tassi di apprendimento
- Potrebbe essere necessario applicare la struttura di apprendimento a due fasi descritta nel documento TinyBERT
Registrazione delle metriche in Databricks MLflow
Dopo aver messo a punto TinyBERT, è fondamentale registrare le metriche delle prestazioni del modello per poterle tracciare e confrontare. Databricks MLflow è una piattaforma eccellente per questo scopo. Ecco come registrare le metriche durante il processo di addestramento:
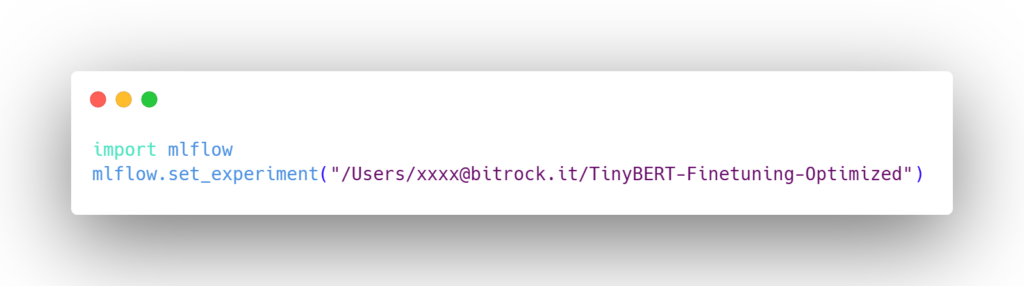
- Impostare il tracciamento di MLflow: per prima cosa, dobbiamo impostare il tracciamento di MLflow nel nostro notebook Databricks:
- Registrare le metriche durante l’addestramento: possiamo modificare il nostro ciclo di addestramento per registrare le metriche dopo ogni epoca o a intervalli regolari.

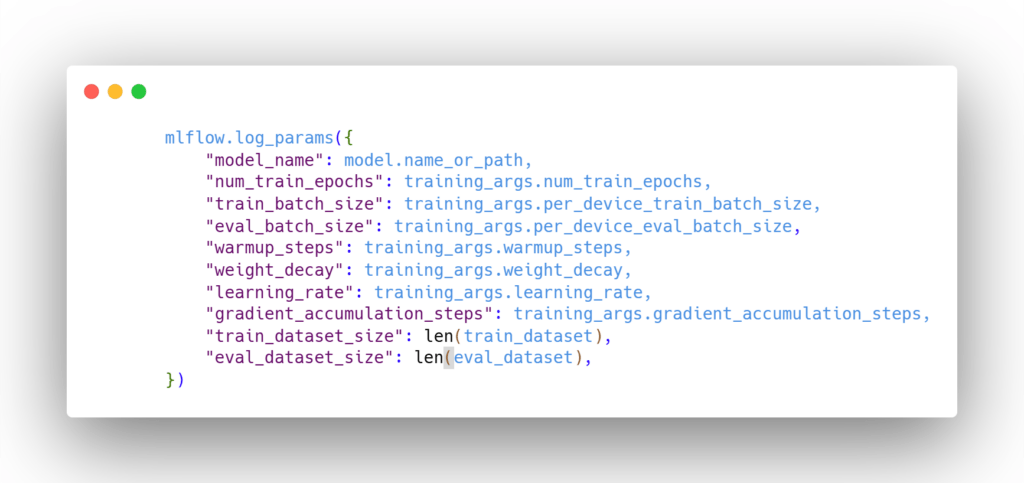
- Registrare i parametri del modello: sarebbe opportuno registrare anche gli iperparametri del modello come riferimento
- Registrare il modello: dopo l’addestramento, è possibile registrare l’intero modello in MLflow:
- Visualizzazione delle metriche in Databricks: Una volta registrate, è possibile visualizzare facilmente le metriche nell’interfaccia Databricks MLflow. Ciò consente di:
– Confrontare diverse esecuzioni con vari iperparametri;
– Tracciare le prestazioni del modello nel tempo;
– Identificare le configurazioni del modello più performanti;
- Recuperare i modelli registrati: è possibile recuperare in seguito il modello registrato per fare inferenze o ulteriori analisi:
Registrando costantemente metriche, parametri e modelli in MLflow, è possibile creare un registro completo degli esperimenti di messa a punto di TinyBERT. Questa pratica migliora la riproducibilità, facilita la collaborazione e semplifica la selezione del modello migliore per l’implementazione.
Quando si confrontano le metriche delle prestazioni di TinyBERT, è importante effettuare un benchmark sia con il modello TinyBERT di base che con le varianti BERT più grandi. Questo approccio consente di comprendere chiaramente i compromessi tra dimensioni del modello e prestazioni per le attività specifiche.
Migliori pratiche e suggerimenti per TinyBERT
- Iniziare con un piccolo sottoinsieme di dati per assicurarsi che la pipeline funzioni correttamente prima di passare a un dataset più grande.
- Utilizzare l’accumulo del gradiente e l’addestramento a precisione mista per gestire i vincoli di memoria.
- Durante l’addestramento, valutare regolarmente il modello per individuare tempestivamente l’overfitting.
- Considerare il compromesso tra dimensione del modello e prestazioni. TinyBERT non può sempre eguagliare le prestazioni dei modelli più grandi, ma la sua efficienza può essere un vantaggio significativo in molte applicazioni reali.
- Sperimentare con diversi tassi di apprendimento e dimensioni dei batch, poiché gli iperparametri ottimali di TinyBERT potrebbero differire da quelli dei modelli più grandi.
- Applicare la distillazione specifica per il compito, come descritto nel documento di TinyBERT, per migliorare le prestazioni.
Conclusioni
La messa a punto di TinyBERT su Databricks offre un modo potente per creare modelli linguistici efficienti e personalizzati, adatti alle vostre esigenze specifiche.
Sfruttando le capacità di calcolo distribuito di Databricks e il tracciamento degli esperimenti di MLflow, è possibile gestire in modo efficiente il processo di messa a punto e ottenere modelli di alta qualità.
Le dimensioni ridotte di TinyBERT e i tempi di inferenza più rapidi lo rendono una scelta eccellente per le applicazioni in cui l’efficienza è fondamentale, pur mantenendo prestazioni competitive in molte attività di comprensione del linguaggio naturale.
Autore: Aditya Mohanty, Data Scientist @ Bitrock