

Apache Flink is an open-source framework for processing data streams, designed to handle large volumes of information in a scalable, fault-tolerant and high-performance way, offering flexible APIs for developing advanced analysis, monitoring and data transformation applications.
One of its outstanding features is the availability of different levels of abstraction for working with data, thus adapting to the different needs and skills of developers. This approach allows Flink to be used by both SQL experts and developers who need fine control over processing pipelines.
Each level of abstraction offers unique advantages: from the simplicity of declarative APIs (Table/SQL API), which allow focusing on data logic without worrying too much about implementation, to the flexibility of procedural APIs (DataStream API) and the detailed control of ProcessFunction APIs. Moreover, the possibility of combining these layers within the DataStream API makes Flink an extraordinarily flexible framework, able to handle both analytical applications and complex processing scenarios.
Flink also excels in its native support for a wide range of built-in connectors, which extend its integration capabilities with other systems. Some of the most widely used connectors include Kafka for message flows, JDBC for relational databases, Amazon S3 for cloud storage, Elasticsearch for data analysis and HDFS for distributed storage. In addition, Flink allows interfacing with multiple sources and destinations simultaneously, combining data from different systems within a single pipeline.
In the following examples, we will explore the levels of abstraction available in Flink through a practical use case: generating simple objects with ‘name’ and ‘points’ fields via Flink’s Datagen connector, counting total points by name, and writing to a Kafka topic. Datagen is an integrated source in Flink that enables the generation of configurable dummy data streams to simulate realistic loads.
1. SQL API
Apache Flink’s SQL API enables accessibility and fast development thanks to its standard SQL syntax, ideal for users without specific knowledge of the framework. In addition, it offers native integration with several source and sink connectors such as Kafka, relational databases and distributed storage.
Code Example

Code Description
- Creation of the source table: By utilizing the DataGen connector, a table named GeneratedData is established that creates imaginary data in real time. It is configured to generate one row per second, with names of 5 characters and point values between 0 and 1000.
- Creation of the Kafka sink: A Kafka table named KafkaSink is established to transmit aggregated outcomes to a Kafka topic. The formats for both keys and values are also defined.
- Query execution: The last INSERT query aggregates the points by name and sends the results to the Kafka topic ‘output-topic’.
Advantages
- Accessibility: possibility to execute standard SQL queries.
- Speed of development: rapid construction of analytical pipelines without the need to write complex code.
- Native integration with tabular sources and sinks: support for various connectors such as databases, Kafka and files with minimal configuration.
2. Table API
The Table API is a declarative API offering a similar approach to SQL, but which can be used through a programming language. It is particularly useful for analytical operations and complex data transformations, while maintaining high readability and simplicity. The Table API enables concise and readable data operations without sacrificing efficiency.
Code Example
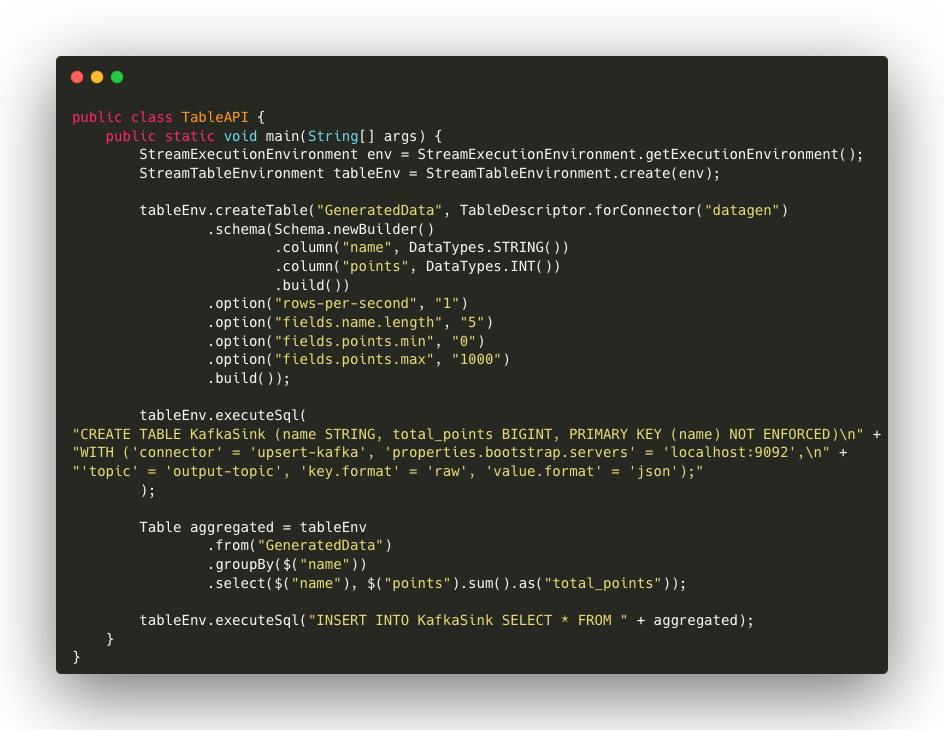
Code Description
- Environment generation: The required environments are created, both for the execution flow (StreamExecutionEnvironment) and for table management (StreamTableEnvironment).
- DataGen source: tableDescriptor defines the GeneratedData source, and thanks to the datagen connector generates real-time data with the same configurations as the SQL part (1 row per second, with names of 5 characters and point values between 0 and 100).
- SinkKafka:a Kafka sink sends aggregated results to a Kafka topic. The configuration includes the connection to Kafka, the topic definition and the choice of serialisation formats. The use of SQL in this example demonstrates how the Flink API can be combined to exploit the simplicity of SQL with the flexibility of the Table API. This synergy allows developers to define hybrid pipelines, exploiting the best of both APIs.
- Aggregation and writing to Kafka: aggregation is performed via the Table API, using the groupBy method to sum the points for each name. The results are then input into the Kafka sink via tableEnv.executeSql.
Advantages
- Simplicity: allows data operations to be written in a readable and compact way.
- Automatic optimisations: leverages Flink’s optimisation engine to generate efficient executions.
- Integration with DataStream: supports interoperability between tables and data streams, allowing developers to easily switch from a declarative to an imperative approach when needed.
3. DataStream API
The DataStream API is Flink’s imperative interface for processing real-time data streams. It offers broad flexibility, supporting a variety of customised transformations. With the DataStream API, developers can manage data streams and apply complex processing logic in a highly configurable manner.
Code Example

Code Description
- DataGen Source: A DataGeneratorSource creates instances of the Item class asynchronously, with a limit of 1 item per second. The generated objects contain a name and a random score.
- Transformation with keyBy and reduce: Data is grouped by name using keyBy and then combined together using reduce, which sums the points for each name.
- Kafka Sink: A Kafka sink is configured to send the aggregated data. Serialisation takes place in JSON format, with the name as the key and the total points as the value.
Advantages
- Flexibility: supports a multitude of customised transformations and advanced processing logics.
- Broad support: can be integrated with other declarative and low-level APIs, giving developers a wide scope for manoeuvre.
- State management: suitable for stateful scenarios, allowing state to be maintained between flow events.
4. Stateful Stream Processing (ProcessFunction) API
Flink’s ProcessFunction API offers maximum control over data processing, allowing developers to manage state precisely. This type of API is ideal for complex scenarios requiring advanced and customised logic, such as stateful stream processing or event time management. The flexibility offered by ProcessFunction allows sophisticated functionality to be implemented, such as the calculation of stateful aggregations, the use of time windows, the handling of out-of-order events and more.
As an example, we can consider the code for the DataStream API by replacing the aggregation part.
Code Example

Code Description
- DataStream and Keyed Process Function: The keyBy method allows grouping of elements by object name, thus creating a partitioned data stream. Each group of data will be handled separately during processing.
- State management: within the KeyedProcessFunction, a ValueStateDescriptor is defined to maintain the state of the processing, in this case the total points accumulated for each name. The open method is used to initialise this state, ensuring that each partition has its own separate state.
- Data processing: In the processElement method, the current value of the state is updated by adding the received element points to the previously stored points. If the state does not yet exist, it is initialised to zero.
- Output of results: Once the state has been updated, the item object with the name and total aggregated points is used as the result.
Advantages
- Maximum control: provides detailed event and state management, making it ideal for advanced processing logic.
- Advanced state management: maintains and updates state for each data stream, supporting stateful transformations and time-sensitive logic.
- Customisation and flexibility: designed for complex scenarios requiring customised solutions, such as advanced timer management to execute scheduled actions at specific intervals or times, such as deadlines or customised time windows.
Conclusions
These examples demonstrate how each level of abstraction in Flink can be used to address the same problem, each with a different level of control, simplicity or optimisation.
Apache Flink offers flexible abstraction layers that can be combined to meet different needs. Thanks to the DataStream API, it is possible to integrate SQL logic, custom transformations and advanced state management into a unified pipeline, exploiting the full potential of each layer. This modular approach makes Flink a versatile framework, capable of adapting to both analytical needs and complex processing scenarios.If you would like to delve deeper into the world of Apache Flink and discover how this framework is in fact redefining the standards of real-time data processing, download our free whitepaper.
Main Author: Anton Cucu, Software Engineer @ Bitrock