

Apache Flink è un framework open-source per l’elaborazione di flussi di dati, progettato per gestire grandi volumi di informazioni in modo scalabile, fault-tolerant e ad alte prestazioni, offrendo API flessibili per sviluppare applicazioni di analisi avanzata, monitoraggio e trasformazione dei dati.
Una delle sue caratteristiche distintive è la disponibilità di diversi livelli di astrazione per lavorare con i dati, adattandosi così alle diverse esigenze e competenze degli sviluppatori. Questo approccio consente a Flink di essere utilizzato sia da esperti di SQL che da sviluppatori che necessitano di controllo fine sulle pipeline di elaborazione.
Ogni livello di astrazione offre vantaggi unici: dalla semplicità delle API dichiarative (Table/SQL API), che permettono di concentrarsi sulla logica dei dati senza preoccuparsi troppo dell’implementazione, alla flessibilità delle API procedurali (DataStream API) e al controllo dettagliato delle ProcessFunction API. Inoltre, la possibilità di combinare questi livelli all’interno della DataStream API rende Flink un framework straordinariamente flessibile, capace di gestire sia applicazioni analitiche che scenari complessi di elaborazione.
Flink eccelle anche per il supporto nativo a una vasta gamma di connettori integrati, che ampliano le sue capacità di integrazione con altri sistemi. Tra i connettori più utilizzati si annoverano Kafka per flussi di messaggi, JDBC per database relazionali, Amazon S3 per l’archiviazione su cloud, Elasticsearch per l’analisi dei dati e HDFS per lo storage distribuito. Inoltre, Flink permette di interfacciarsi contemporaneamente con più sorgenti e destinazioni, combinando dati provenienti da sistemi diversi all’interno di una singola pipeline.
Nei prossimi esempi, esploreremo i livelli di astrazione disponibili in Flink tramite un caso d’uso pratico: generazione di oggetti semplici con campi “nome” e “punti” tramite connettore Datagen di Flink, conteggio dei punti complessivi per nome, scrittura su un topic Kafka. Datagen è una sorgente integrata in Flink che consente di generare flussi di dati fittizi configurabili per simulare carichi realistici.
1. SQL API
La SQL API di Apache Flink offre accessibilità e rapidità di sviluppo grazie alla sintassi SQL standard, ideale per utenti senza conoscenze specifiche del framework. Inoltre, offre un’integrazione nativa con numerosi connettori source e sink come Kafka, database relazionali e storage distribuiti.
Esempio di codice

Descrizione del codice
- Creazione della tabella sorgente: utilizzando il connettore DataGen, viene definita una tabella chiamata GeneratedData che genera dati fittizi in tempo reale. Viene configurata per generare una riga al secondo, con nomi di 5 caratteri e valori di punti compresi tra 0 e 1000.
- Creazione del sink Kafka: Viene creata una tabella Kafka, chiamata KafkaSink, per inviare i risultati aggregati in un topic Kafka. Vengono anche specificati i formati per i valori e per le chiavi.
- Esecuzione della query: L’ultima query di INSERT aggrega i punti per nome e invia i risultati al topic Kafka “output-topic”.
Vantaggi
- Accessibilità: consente di eseguire query SQL standard.
- Velocità di sviluppo: ideale per costruire rapidamente pipeline analitiche senza la necessità di scrivere codice complesso.
- Integrazione nativa con source e sink tabulari: supporta diversi connettori, come database, Kafka e file con una configurazione minima.
2. Table API
La Table API è un’API dichiarativa che offre un approccio simile a SQL, ma utilizzabile attraverso un linguaggio di programmazione. È particolarmente utile per operazioni analitiche e trasformazioni di dati complessi, pur mantenendo un’alta leggibilità e semplicità. La Table API permette di esprimere in modo conciso e leggibile operazioni sui dati senza rinunciare all’efficienza.
Esempio di Codice
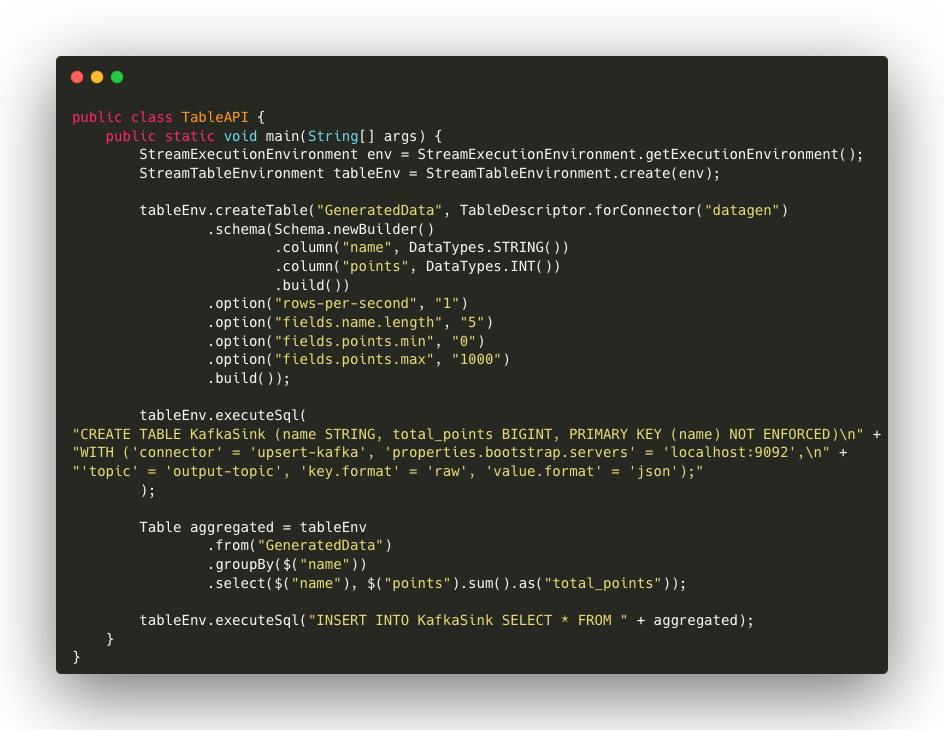
Descrizione del codice
- Creazione degli ambienti: vengono creati gli ambienti necessari, sia per il flusso di esecuzione (StreamExecutionEnvironment) che per la gestione delle tabelle (StreamTableEnvironment).
- Sorgente DataGen: la sorgente GeneratedData viene definita tramite TableDescriptor, utilizzando il connettore datagen per generare dati in tempo reale con le stesse configurazioni della parte SQL (1 riga al secondo, con nomi di 5 caratteri e valori di punti tra 0 e 100).
- Sink Kafka: come nel caso della SQL API, viene creato un sink Kafka per inviare i risultati aggregati a un topic Kafka. La configurazione include la connessione a Kafka, la definizione del topic e la scelta dei formati di serializzazione. L’utilizzo di SQL in questo esempio dimostra come le API di Flink possano essere combinate per sfruttare la semplicità del linguaggio SQL con la flessibilità della Table API. Questa sinergia consente agli sviluppatori di definire pipeline ibride, sfruttando il meglio di entrambe le API.
- Aggregazione e scrittura su Kafka: l’aggregazione viene eseguita tramite la Table API, utilizzando il metodo groupBy per sommare i punti per ogni nome. I risultati vengono quindi inseriti nel sink Kafka tramite tableEnv.executeSql.
Vantaggi
- Semplicità: permette di scrivere operazioni sui dati in modo leggibile e compatto.
- Ottimizzazioni automatiche: sfrutta il motore ottimizzatore di Flink per generare esecuzioni efficienti.
Integrazione con DataStream: supporta l’interoperabilità tra tabelle e flussi di dati, permettendo agli sviluppatori di passare facilmente da un approccio dichiarativo a uno imperativo quando necessario.
3. DataStream API
La DataStream API è l’interfaccia imperativa di Flink per l’elaborazione di flussi di dati in tempo reale. È progettata per offrire un’ampia flessibilità, supportando una varietà di trasformazioni personalizzate. Con DataStream API, gli sviluppatori possono gestire flussi di dati e applicare logiche di elaborazione complesse in modo altamente configurabile.
Esempio di codice

- Sorgente DataGen: viene creata una sorgente DataGeneratorSource che genera istanze della classe Item in modo asincrono, con un limite di 1 elemento per secondo. Gli oggetti generati contengono un nome e un punteggio casuale.
- Trasformazione con keyBy e reduce: i dati vengono raggruppati per il nome tramite keyBy e poi combinati insieme utilizzando reduce, che somma i punti per ogni nome.
- Sink Kafka: viene configurato un sink Kafka per inviare i dati aggregati. La serializzazione avviene in formato JSON, con il nome come chiave e i punti totali come valore.
Vantaggi
- Flessibilità: supporta una varietà di trasformazioni personalizzate e logiche di elaborazione avanzate.
- Ampio supporto: può essere integrata con altre API dichiarative e di basso livello, offrendo agli sviluppatori un ampio margine di manovra.
- Gestione dello stato: adatta a scenari stateful, permettendo di mantenere lo stato tra i vari eventi del flusso.
4. Stateful Stream Processing (ProcessFunction) API
La ProcessFunction API di Flink offre il massimo controllo sull’elaborazione dei dati, consentendo agli sviluppatori di gestire lo stato in modo preciso. Questo tipo di API è ideale per scenari complessi che richiedono logiche avanzate e personalizzate, come l’elaborazione di flussi di dati con stato o la gestione di eventi temporali. La flessibilità offerta dalla ProcessFunction permette di implementare funzionalità sofisticate, come il calcolo di aggregazioni stateful, l’uso di finestre temporali, la gestione di eventi fuori ordine e altro ancora.
Come esempio possiamo considerare il codice per DataStream API sostituendo la parte di aggregazione.
Esempio di codice

Descrizione del Codice
- DataStream e Keyed Process Function: il metodo keyBy permette di raggruppare gli elementi in base al nome dell’oggetto, creando così un flusso di dati partizionato. Ogni gruppo di dati sarà gestito separatamente durante l’elaborazione.
- Gestione dello stato: all’interno della KeyedProcessFunction, si definisce un ValueStateDescriptor per mantenere lo stato dell’elaborazione, nel nostro caso il totale dei punti accumulati per ciascun nome. Il metodo open viene utilizzato per inizializzare questo stato, garantendo che ogni partizione possieda un proprio stato separato.
- Elaborazione dei dati: nel metodo processElement, il valore corrente dello stato viene aggiornato sommando i punti dell’elemento ricevuto ai punti precedentemente memorizzati. Se lo stato non esiste ancora, viene inizializzato a zero.
- Emissione dei risultati: una volta aggiornato lo stato, l’oggetto Item con il nome e il totale dei punti aggregati viene emesso come risultato.
Vantaggi
- Massimo controllo: fornisce una gestione dettagliata degli eventi e dello stato, rendendola ideale per logiche di elaborazione avanzate.
- Gestione avanzata dello stato: consente di mantenere e aggiornare lo stato per ogni flusso di dati, supportando trasformazioni stateful e logiche sensibili al tempo.
- Personalizzazione e flessibilità: progettata per scenari complessi che richiedono soluzioni su misura, come la gestione avanzata dei timer per eseguire azioni programmate a intervalli o momenti specifici, come scadenze o finestre temporali personalizzate.
Conclusioni
Questi esempi dimostrano come ogni livello di astrazione in Flink possa essere utilizzato per affrontare lo stesso problema, ciascuno con un diverso livello di controllo, semplicità o ottimizzazione.
Apache Flink offre livelli di astrazione flessibili che possono essere combinati per soddisfare le esigenze più diverse. Grazie alla DataStream API, è possibile integrare logiche SQL, trasformazioni personalizzate e gestione avanzata dello stato in una pipeline unificata, sfruttando al massimo le potenzialità di ogni livello. Questo approccio modulare rende Flink un framework versatile, capace di adattarsi sia a esigenze analitiche che a scenari di elaborazione complessi.
Se vuoi approfondire il mondo di Apache Flink e scoprire come questo framework stia ridefinendo gli standard di elaborazione dei dati in tempo reale, scaricate il nostro whitepaper gratuito.
Autore: Anton Cucu, Software Engineer @ Bitrock