

In questo articolo andremo a presentare la seconda parte del nostro approfondimento sulle operazioni con DataStream in Apache Flink. Dopo aver introdotto le basi della gestione dei flussi nella prima parte, in questa ci concentreremo su come combinare, unire e aggregare i dati provenienti da flussi distinti, operazioni cruciali quando si lavora con sorgenti multiple o con dati strutturati in modo diverso.
Apache Flink offre una varietà di operatori per la gestione di più flussi di dati, consentendo di unirli o elaborarli in parallelo e flessibilmente. Inizialmente vedremo come utilizzare gli operatori Union e Connect per combinare flussi di dati e, in seguito, approfondiremole operazioni di Join e CoGroup, che permettono di unire i dati basandosi su chiavi comuni, offrendo soluzioni potenti per l’integrazione e l’aggregazione di flussi eterogenei. Attraverso esempi pratici, illustreremo come questi strumenti possano semplificare e potenziare l’elaborazione dei dati near-realtime
Integrazione di Stream: Union e Connect
Flink offre due operatori principali per integrare i flussi: Union e Connect. Questi operatori sono fondamentali per la gestione di dati provenienti da sorgenti diverse o con strutture diverse.
Union
L’operatore Union consente di unire due o più flussi dello stesso tipo in un unico flusso. Questo strumento è utile quando si hanno più sorgenti di dati con la stessa struttura e si desidera combinarle. I dati provenienti dai vari flussi verranno trattati come se provenissero da una singola sorgente.Facciamo un esempio: immaginiamo di avere due flussi di dati che rappresentano gli acquisti effetuati in due regioni diverse: America ed Europa. Entrambi i flussi generano dati in formato stringa con separatore ”-” (ad esempio customerName-itemId-itemPrice).

Di seguito, i dettagli del codice:
- americaSource e europeSource sono flussi che leggono dati dalle rispettive regioni.
- union(europeSource) combina i due flussi in uno.
- map(…) trasforma ogni stringa in un oggetto Purchase, dividendo la stringa in base al carattere “-” per ottenere i campi (cliente, ID prodotto, prezzo).
- print() stampa il flusso unificato.
In questo modo, i dati provenienti da America ed Europa vengono trattati insieme, come se provenissero da una singola sorgente.In this way, data from America and Europe are processed together, as if from a single source.
Connect
L’ operatore Connect consente di combinare due flussi con tipi di dati differenti. A differenza di Union, che richiede flussi dello stesso tipo, Connect consente di mantenere i flussi separati fino al momento della trasformazione, permettendo di applicare operazioni distinte.
Per esempio, immaginiamo che i flussi di acquisti abbiano formati di stringa differenti: uno utilizza il separatore “-”, mentre l’altro utilizza “:”.

Di seguito, i dettagli del codice:
- connect(europeSource) collega i due flussi, consentendo di mantenerli separati fino alla trasformazione.
- La classe CoMapFunction definisce due metodi:
- map1(): trasforma i dati di americaSource, dividendo la stringa con il separatore “
-”. - map2(): trasforma i dati di europeSource, utilizzando “
:” come separatore.
- map1(): trasforma i dati di americaSource, dividendo la stringa con il separatore “
- Il risultato è un unico flusso contenente tutti gli acquisti, indipendentemente dal formato iniziale.
Combinazione e Aggregazione di Stream: Join e CoGroup
Per combinare dati da flussi distinti basandosi su una chiave comune (ad esempio, l’ID di un prodotto), Flink offre due operatori: Join e CoGroup. Questi operatori consentono di incrociare i dati, ma con modalità di elaborazione diverse.
Join
L’operatore Join unisce i dati di due flussi che condividono una chiave comune. Questo strumento è utile quando si desidera arricchire i dati di un flusso con quelli provenienti da un altro.
Immaginiamo di avere due flussi di dati, il primo riceve informazioni sugli acquisti effettuati, mentre il secondo riceve informazioni legate al loro ID.
DataStream<Purchase> purchaseDataStream = ...
DataStream<Item> itemDataStream = ...
Le classi potrebbero essere definite come:
class Purchase (String customerName, String itemId, int itemPrice)..
class Item (String id, String itemName)..
Avendo questi due flussi, potremmo combinarli per ottenere un arricchimento del dato.
Di seguito, i dettagli del codice:
- join(itemsDataStream) esegue un join tra il flusso degli acquisti e quello degli articoli.
- where(Purchase::getItemId).equalTo(Item::getId) indica che l’unione avverrà sulla base della corrispondenza degli ID dei prodotti.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))) applica una finestra temporale di 20 secondi.
- apply(new JoinFunction<…>) definisce la logica del join, restituendo una stringa che indica il nome del cliente e l’articolo acquistato.
CoGroup
L ‘operatore CoGroup offre maggiore flessibilità rispetto a Join, permettendo di trattare i dati di entrambi i flussi come insiemi separati e applicare logiche di elaborazione più complesse.

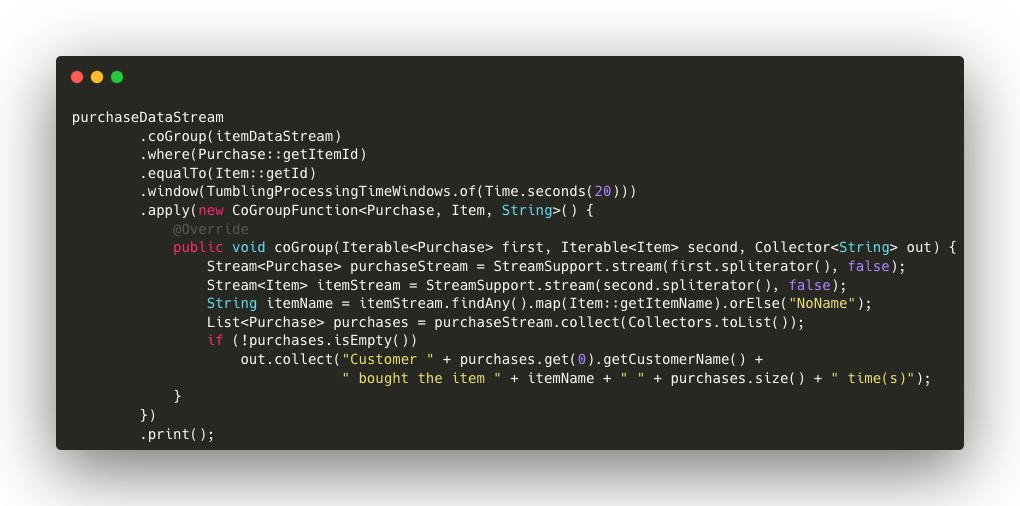
BDi seguito, i dettagli del codice:
- print(): Il risultato viene stampato sulla console. In questo esempio, la funzione stampa un messaggio che riporta quante volte un cliente ha acquistato un determinato articolo nel periodo considerato. ssage stating how many times a customer has purchased a certain article in the period under consideration.
- coGroup(itemsDataStream): combina i due flussi di dati (purchaseDataStream e itemsDataStream) in base a una chiave comune. In questo caso, la chiave è l’ID dell’articolo, rappresentato da getItemId per gli acquisti e getId per gli articoli.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))): definisce una finestra temporale di 20 secondi. Ciò significa che l’operazione di CoGroup viene applicata agli elementi di entrambi i flussi che rientrano entro la finestra di tempo specificata.
- apply(new CoGroupFunction<Purchase, Item, String>() {…}): all’interno di questa funzione, viene definita la logica di combinazione dei dati tra i due flussi:
- coGroup(Iterable<Purchase> purchases, Iterable<Item> items, Collector<String> out): la funzione riceve due collezioni come input: un insieme di acquisti (purchases) e un insieme di articoli (items).
- StreamSupport.stream(items.spliterator(), false): converte l’insieme di articoli in uno stream per cercare l’articolo corrispondente. Se un articolo è presente, viene estratto il suo nome, altrimenti, viene assegnato un valore predefinito (“
NoName“). - StreamSupport.stream(purchases.spliterator(), false): converte l’insieme degli acquisti in una lista per poterli iterare in base a un determinato articolo.
- purchaseList.size(): conta quanti acquisti sono stati effettuati per quell’articolo.
- out.collect(…): se ci sono acquisti, genera un messaggio che indica il nome del cliente, l’articolo acquistato e il numero di volte in cui è stato acquistato.
Conclusioni
In conclusione, Apache Flink offre una vasta gamma di operatori per combinare e gestire flussi di dati, ciascuno con funzionalità specifiche e adatte a diverse esigenze.
L’operatore Union è utile per combinare flussi dello stesso tipo, mantenendo intatta la loro struttura e l’ordine. Connect, invece, permette di integrare flussi di tipi diversi, mantenendo separate le loro logiche di elaborazione.
Quando si tratta di unire flussi basati su chiavi comuni, l’operatore Join è indicato per arricchire i dati di un flusso con informazioni di un altro flusso. CoGroup, invece, offre maggiore flessibilità, consentendo operazioni più complesse su flussi distinti.
Scegliere l’operatore giusto è fondamentale per creare pipeline di dati robuste ed efficienti, in grado di adattarsi a diverse esigenze applicative e garantire una gestione scalabile dei flussi di dati.
Autore: Anton Cucu, Software Engineer @ Bitrock