

In this article, we will present the second part of our in-depth look at DataStream operations in Apache Flink. After introducing the basics of stream management in the first part, in this one we will focus on how to combine, merge and aggregate data from separate streams, operations that are crucial when working with multiple sources or differently structured data.
Apache Flink offers a variety of operators for handling multiple data streams, allowing them to be joined or processed in parallel and flexibly. Initially, we will see how to use the Union and Connect operators to combine data streams and, later on, we will delve into Join and CoGroup operations, which allow data to be joined based on common keys, offering powerful solutions for the integration and aggregation of heterogeneous streams. Through practical examples, we will illustrate how these tools can simplify and enhance the processing of near-real time data.
Stream Integration: Union and Connect
Flink offers two main operators to integrate streams: Union and Connect. These operators are essential for handling data from different sources or with different structures.
Union
The Union operator allows two or more streams of the same type to be combined into a single stream. This is useful when you have several data sources with the same structure and wish to combine them. The data from the various streams will be treated as if they came from a single source.Let’s take an example: let’s imagine we have two data streams representing purchases made in two different regions: America and Europe. Both streams generate data in string format with a ‘-’ separator (e.g. customerName-itemId-itemPrice).

Below are the details of the code:
- americaSource e europeSource are streams that read data from their respective regions.
- union(europeSource) combines the two streams into one.
- map(…) transforms each string into a Purchase object, dividing the string by the “
-” character to obtain the fields (customer, product ID, price). - print() prints the unified stream.
In this way, data from America and Europe are processed together, as if from a single source.
Connect
The Connect operator allows two streams with different data types to be combined. In contrast to Union, which requires streams of the same type, Connect allows streams to be kept separate until transformation, allowing separate operations to be applied.
For example, let us imagine that the streams have different string formats: one uses the ‘-’ separator, while the other uses ‘:’.

Below are the details of the code:
- connect(europeSource) connects the two streams, allowing them to be kept separate until transformation.
- The CoMapFunction defines two methods:
- map1(): transforms the data of americaSource, dividing the string with the separator “
-”. - map2(): transforms the data of europeSource, using “
:” as the separator.
- map1(): transforms the data of americaSource, dividing the string with the separator “
- The result is a single stream containing all purchases, regardless of the initial format.
Stream Combination and Aggregation: Join and CoGroup
In order to combine data from separate streams based on a common key (e.g. a product ID), Flink offers two operators: Join and CoGroup. These operators allow data to be cross-referenced, but with different processing methods
Join
The Join operator joins data from two streams that share a common key. This tool is useful when you want to enrich the data of one stream with data from another.
Let’s imagine that we have two data streams, the first receives information on purchases made, while the second receives information related to their ID.
DataStream<Purchase> purchaseDataStream = ...
DataStream<Item> itemDataStream = ...
The classes could be defined as:
class Purchase (String customerName, String itemId, int itemPrice)..
class Item (String id, String itemName)..
By having these two streams, we could combine them to obtain an enrichment of data.
Below are the details of the code:
- join(itemsDataStream) performs a join between the purchase and item streams.
- where(Purchase::getItemId).equalTo(Item::getId) indicates that the join will be performed on the basis of matching item IDs.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))) applies a time window of 20 seconds.
- apply(new JoinFunction<…>) defines the logic of the join, returning a string indicating the name of the customer and the purchased item.
CoGroup
The CoGroup operator offers more flexibility than Join, allowing data from both streams to be treated as separate sets and more complex processing logic to be applied.

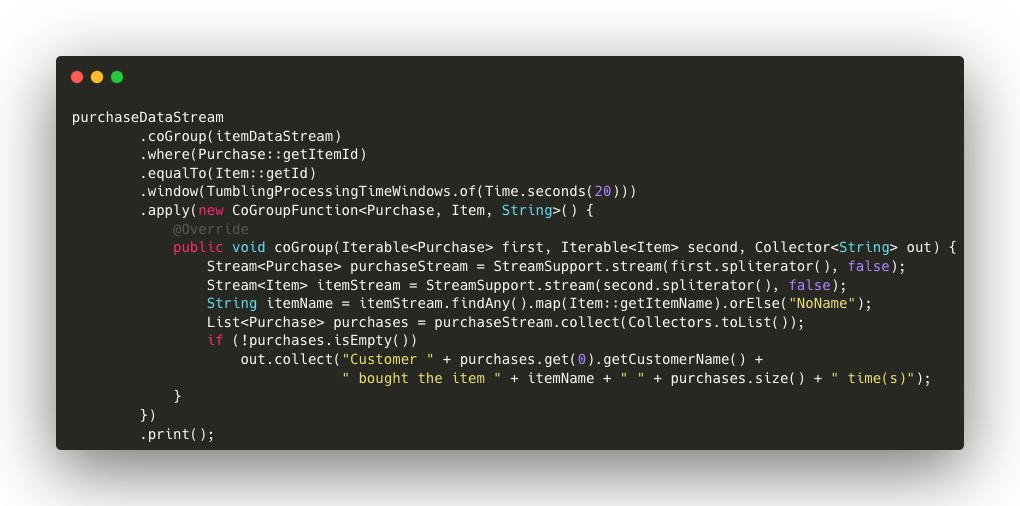
Below are the details of the code:
- coGroup(itemsDataStream): combines the two data streams (purchaseDataStream and itemsDataStream) based on a common key. In this case, the key is the item ID, represented by getItemId for purchases and getId for items.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))): defines a time window of 20 seconds. This means that the CoGroup operation is applied to the elements of both streams that fall within the specified time window.
- apply(new CoGroupFunction<Purchase, Item, String>() {…}): within this function, the logic of combining data between the two streams is defined:
- coGroup(Iterable<Purchase> purchases, Iterable<Item> items, Collector<String> out): the function receives two collections as input: a set of purchases (purchases) and a set of items (items).
- StreamSupport.stream(items.spliterator(), false): converts the set of items into a stream to search for the corresponding article. If an article is present, its name is extracted, otherwise, a default value (“
NoName“) is assigned. - StreamSupport.stream(purchases.spliterator(), false): converts the set of purchases into a list in order to iterate over them according to a given article.
- purchaseList.size(): counts how many purchases have been made for that item.
- out.collect(…): if there are purchases, generates a message indicating the name of the customer, the item purchased and the number of times it was purchased.
print(): The result is printed on the console. In this example, the function prints a message stating how many times a customer has purchased a certain article in the period under consideration.
Conclusion
In conclusion, Apache Flink offers a wide range of operators to combine and manage data streams, each with specific functionality to suit different needs.
The Union operator is useful for combining streams of the same type, keeping their structure and order intact. Connect, on the other hand, allows streams of different types to be integrated, while keeping their processing logic separate.
When it comes to joining streams based on common keys, the Join operator is suitable for enriching the data of one stream with information from another stream. CoGroup, on the other hand, offers more flexibility, allowing more complex operations on separate streams.
Choosing the right operator is crucial for creating robust and efficient data pipelines that can adapt to different application needs and ensure scalable data flow management.
Main Author: Anton Cucu, Software Engineer @ Bitrock