

Introduzione al progetto
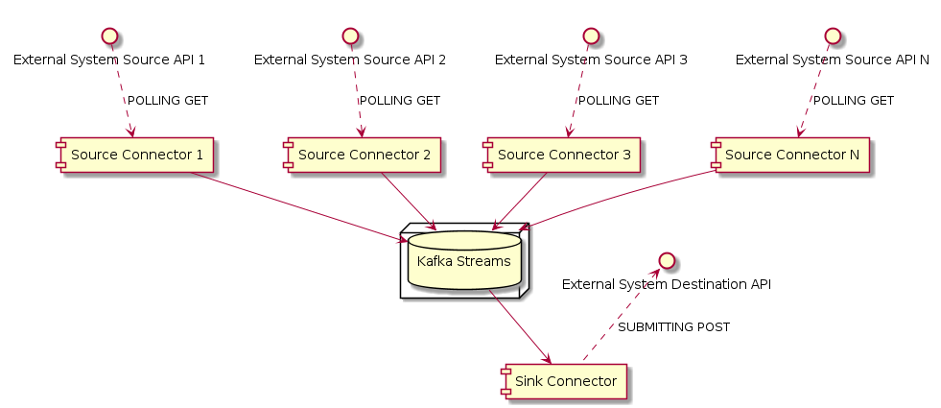
Durante uno dei nostri progetti, abbiamo lavorato su un’applicazione di streaming di dati in tempo reale utilizzando Kafka.
Dopo aver ricevuto i dati da alcuni servizi esterni tramite API REST, li abbiamo manipolati utilizzando le pipeline dei flussi Kafka; quindi, abbiamo chiamato un servizio API REST esterno per rendere i dati disponibili al sistema di destinazione.
Per sviluppare i componenti di ingresso e di uscita del flusso ETL, abbiamo scritto alcuni connettori di origine e un connettore di scarico personalizzati per il modulo Kafka Connect.
Il problema
Probabilmente, la maggior parte di voi ha già capito il problema: per ognuno dei nostri connettori, dovevamo costruire il “fat Jar” e spostarlo nella cartella Kafka Connect che, per non complicare le cose, era in esecuzione in Kubernetes.
Purtroppo per noi, i connettori non si potevano contare sulle dita di una mano: di conseguenza, la procedura manuale era lunga, ripetitiva e richiedeva molto tempo.
Un altro problema che abbiamo riscontrato è che la creazione/cancellazione dei nostri connettori era “fatta a mano”, il che rendeva impossibile determinare quali configurazioni fossero in fase di provisioning guardando il repository Git.
La soluzione
Nel nostro progetto, ogni connettore veniva modificato utilizzando un repository Git separato. Abbiamo deciso di puntare su CI (Continuous Integration) e CD (Continuous Delivery), con distribuzioni continue nell’ambiente di sviluppo.
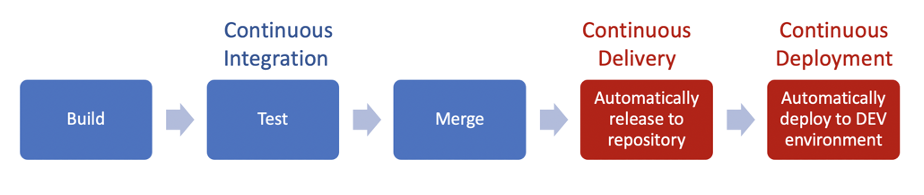
Nel nostro scenario, abbiamo deciso di utilizzare Jenkins come demone CI/CD e Terraform per gestire tutte le infrastrutture e le configurazioni dei connettori, con l’obiettivo di ottenere un’esperienza GitOps completa.
Nel nostro lavoro quotidiano, ogni volta che uniamo una richiesta di pull, questo evento innesca una pipeline Jenkins che costruisce l’artefatto e lo pubblica in un repository Artifactory privato.
Se questa fase ha successo, il passo successivo è quello di attivare il lavoro di distribuzione.

Dato che la distribuzione è completamente automatizzata nell’ambiente di sviluppo, le ultime versioni dei nostri connettori sono sempre in esecuzione in pochi minuti dopo aver unito le modifiche al codice. Per gli altri ambienti, il lavoro di Jenkins richiede un’approvazione manuale, per evitare che modifiche indesiderate vengano promosse oltre l’ambiente di sviluppo.
La distribuzione stessa dei Jar dei connettori viene eseguita utilizzando una tabella Helm personalizzata che recupera gli artefatti dei connettori desiderati prima di avviare il contenitore Kafka Connect.
Come visto in precedenza, nel nostro progetto stavamo usando Terraform per gestire l’infrastruttura e la configurazione dei connettori. Abbiamo deciso di utilizzare un unico repository per tutta la base di codice di Terraform, usando diversi stati di Terraform per gestire ambienti diversi.
Per ogni connettore, abbiamo creato un modulo Terraform contenente la definizione delle risorse del connettore…
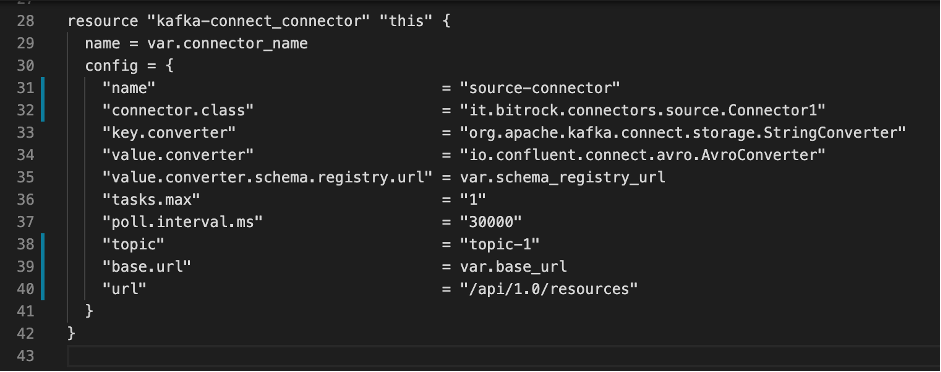
… e le variabili di configurazione previste:
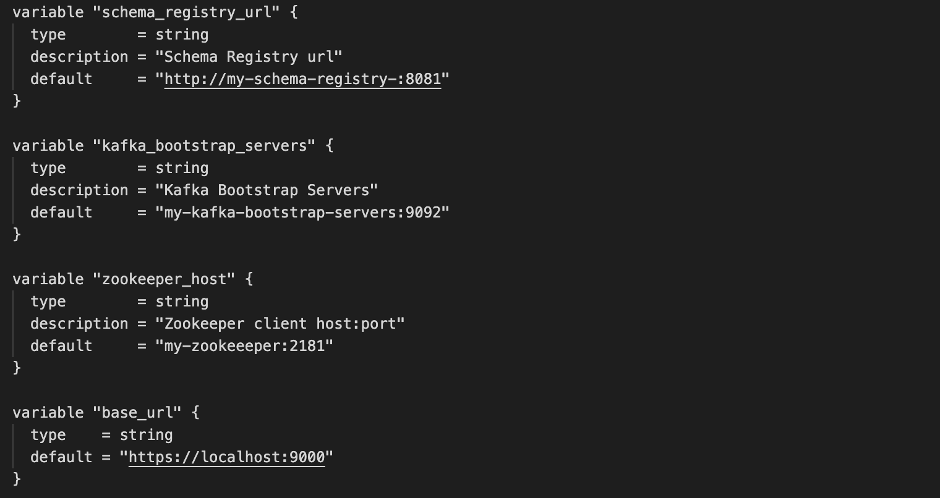
In ogni configurazione di ambiente, abbiamo dichiarato quali connettori configurare, istanziando i moduli Terraform appropriati che sono stati precedentemente creati. Anche i moduli Terraform erano versionati: ciò significa che, in ambienti diversi, potevamo eseguire configurazioni diverse dello stesso artefatto connettore. In questo modo, siamo stati in grado di distribuire il jar senza doverlo fare manualmente.

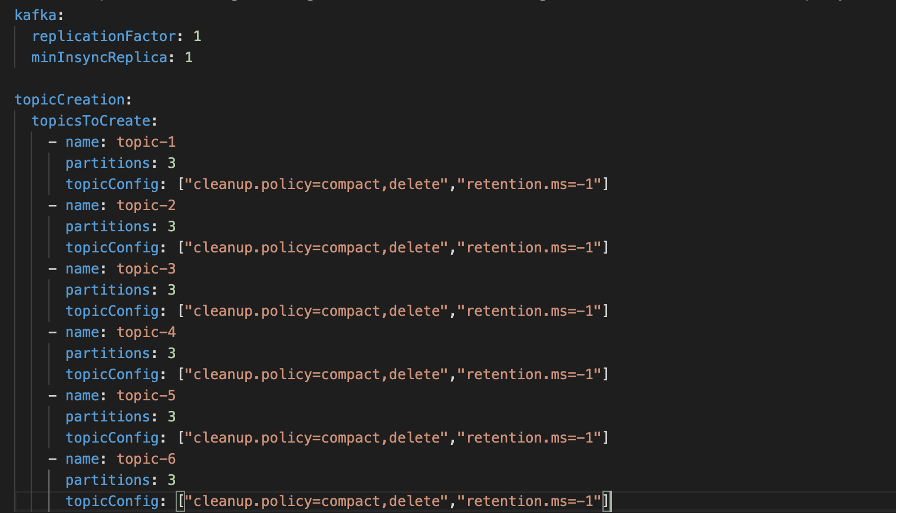
L’ultimo pezzo mancante era la creazione di tutti gli argomenti necessari per la nostra applicazione. Abbiamo deciso di definirli in un semplice file yaml e, con l’aiuto di un semplice script bash, sono stati creati all’esecuzione del lavoro Jenkins.
Conclusioni
In questo articolo abbiamo esplorato come migliorare e progettare la distribuzione dei connettori Kafka in vari ambienti senza la necessità di interventi manuali.
Gli sviluppatori possono concentrarsi sul miglioramento del loro codice e quasi ignorare la parte di distribuzione, dato che ora sono in grado di eseguire distribuzioni con un solo clic.
L’abilitazione dei connettori o la modifica delle configurazioni sono ora solo poche righe modificate nel repo di Terraform, senza la necessità di eseguire a mano le richieste API di Kafka Connect.
Dal nostro punto di vista, ha senso per molte aziende investire tempo, denaro e risorse per automatizzare la distribuzione dei connettori.
Autori: Alberto Adami, Software Engineer @Bitrock – Daniele Marenco, Software Engineer @Bitrock