

Introduction to the Project
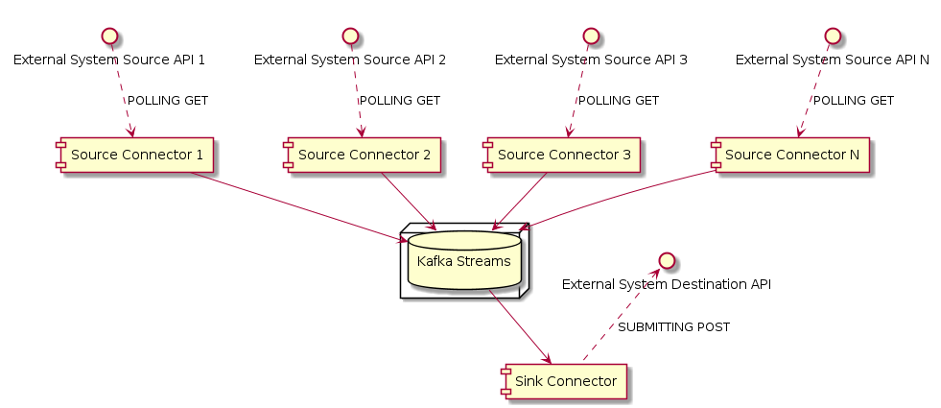
During one of our projects, we worked on a real-time data streaming application using Kafka.
After receiving the data from some external services using REST API, we manipulated it using Kafka streams pipelines; then, we called an external REST API service to make the data available to the destination system.
In order to develop the input and output components of the ETL flow, we wrote some custom Source Connectors and a Sink Connector for the Kafka Connect module.
The Problem
Probably, most of you have already figured out the problem: for each of our connectors, we needed to build the “fat Jar” and move it to the Kafka Connect folder, which, for the sake of making things more complicated, was running in Kubernetes.
Unfortunately for us, the connectors couldn’t be counted on the fingers of one hand: consequently, the manual procedure was long, repetitive, and very time-consuming.
Another issue we encountered was that the creation/deletion of our connectors was “made by hand”, which made it impossible to determine which configurations were being provisioned by looking at the Git repository.
The Solution
In our project, each connector was versioned using a separate git repository. We decided to aim at CI (Continuous Integration) and CD (Continuous Delivery), with Continuous Deployments in the development environment.
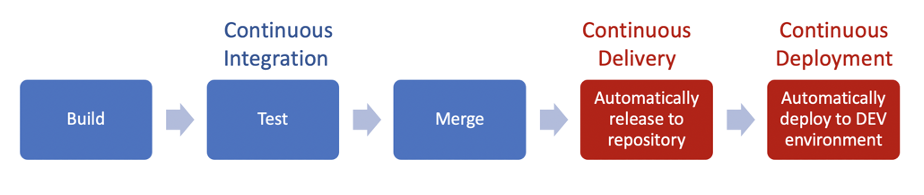
In our scenario, we decided to use Jenkins as a CI/CD daemon and Terraform to manage all the infrastructure and configurations for the connectors, aiming at achieving a full GitOps experience.
In our daily work, whenever we merge a pull request, this event triggers a Jenkins pipeline that builds the artifact and publishes it into a private Artifactory repository.
If this phase succeeds, then the next step is to trigger the deployment job.

Given that the deployment is fully automated in the development environment, the latest versions of our connectors are always running in a matter of minutes after having merged code changes. For the other environments, Jenkins’s job requires manual approval, in order to avoid having unwanted changes promoted past the development environment.
The deployment of connector Jars itself is performed by using a custom Helm chart that fetches the desired connectors artifacts before starting Kafka Connect container.
As seen before, in our project we were using Terraform for managing infrastructure and connectors configuration. We decided to use a single repository for all the Terraform codebase, using different Terraform states to manage different environments.
For each connector, we created a Terraform module containing the connector resource definition…
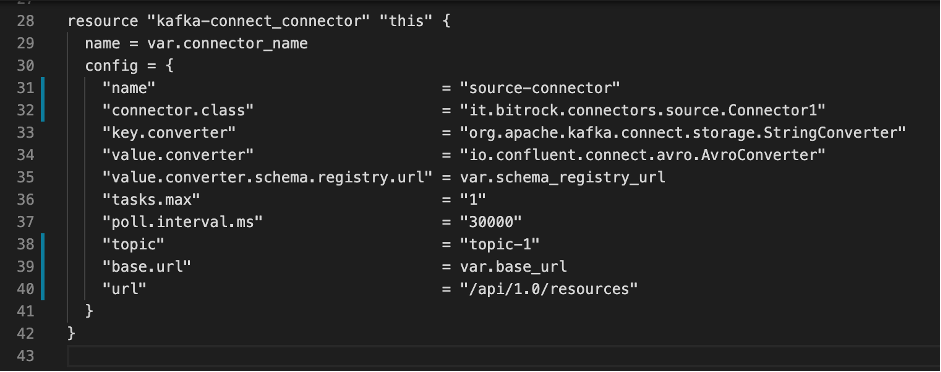
…and the expected configuration variables:
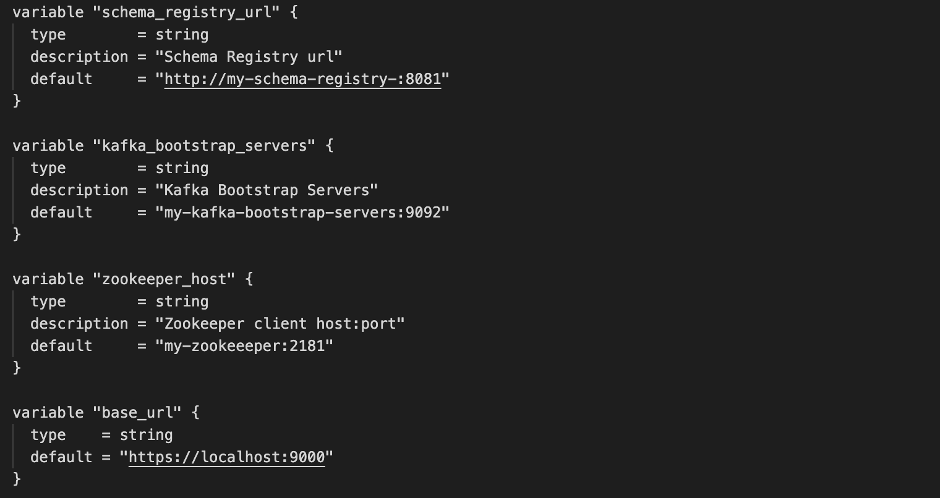
In each environment configuration, we declared which connectors to configure, by instantiating the proper Terraform modules that were previously created. Terraform modules were versioned as well: this means that, in different environments, we could run different configurations of the same connector artifact. In this way, we were able to deploy the jar without doing it manually.

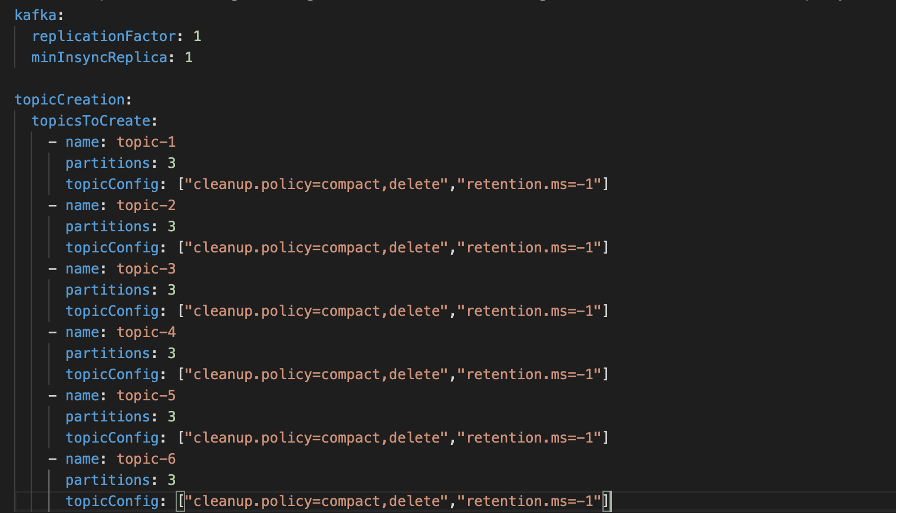
The last missing piece was the creation of all the required topics for our application. We decided to define them into a simple yaml file and, with the help of a simple bash script, they got created when the Jenkins job ran.
Conclusions
In this article we have explored how to improve and engineer the deployment of Kafka connectors in various environments without the need for manual intervention.
Developers can focus on enhancing their code and almost ignore the deployment part, giving that they are now able to perform one-click deployments.
Enabling connectors or changing configurations are now just a few lines changed in the Terraform repo, without the need of executing Kafka Connect API requests by hand.
From our perspective, it makes sense for a lot of companies to invest time, money and resources to automate the deployment of the connectors.
Authors: Alberto Adami, Software Engineer @Bitrock – Daniele Marenco, Software Engineer @Bitrock