

Con il crescente impatto ambientale dei modelli di embedding su larga scala, c’è un’urgente necessità di approcci più sostenibili all’apprendimento dellE sentence representation. Questo articolo esamina il panorama delle tecniche di intelligenza artificiale verde per creare sentence transformers efficienti ed ecologici.
Passiamo in rassegna metodi come la quantizzazione, il pruning, la distillazione della conoscenza e le architetture efficienti progettate specificamente per sentence transformers, e discutiamo gli strumenti per misurare e ridurre l’impronta di carbonio di questi modelli.
L’obiettivo è quello di evidenziare il potenziale dell’IA sostenibile per la costruzione di sentence transformers ad alte prestazioni, riducendo al minimo l’uso delle risorse e le emissioni. Concludiamo con una discussione sulle sfide principali e sulle direzioni future dell’apprendimento ecologico della rappresentazione delle frasi.
Green AI per Sentence Transformers Sostenibili
I Sentence transformers hanno rivoluzionato il campo dell’elaborazione del linguaggio naturale (NLP), consentendo un apprendimento potente ed efficiente della sentence representation. Questi modelli, come BERT, RoBERTa, and DistilBERT, sono diventati la spina dorsale di diverse attività a valle, tra cui la classificazione dei testi, la similarità semantica e l’analisi del sentiment. Codificando le frasi in rappresentazioni vettoriali dense, i sentence transformers catturano ricche informazioni semantiche e consentono un confronto e una manipolazione efficaci dei dati testuali.
Tuttavia, il successo dei sentence transformers ha un costo ambientale significativo. L’addestramento e l’implementazione di questi modelli richiedono notevoli risorse computazionali e consumi energetici, contribuendo alle emissioni di carbonio e sollevando problemi di sostenibilità. Con la crescita della domanda di modelli di sentence embedding in tutti i settori e le applicazioni, diventa fondamentale sviluppare approcci più efficienti ed ecologici all’apprendimento della rappresentazione delle frasi.
In risposta a questa sfida, il campo emergente della Green AI mira a creare sentence transformers sostenibili che mantengano prestazioni elevate riducendo al minimo l’impatto ambientale. Le tecniche di Green AI, come la quantizzazione, il pruning, la distillazione della conoscenza e le architetture efficienti, hanno mostrato risultati promettenti nel ridurre l’uso delle risorse e l’impronta di carbonio dei trasformatori di frasi senza compromettere l’efficacia.
Questo articolo fornisce una panoramica completa dell’attuale panorama degli approcci di Green AI specificamente adattati ai sentence transformers. Si approfondiscono le tecniche e gli strumenti più promettenti, discutendone i punti di forza, le limitazioni e il potenziale per la costruzione di modelli di sentence embedding sostenibili. L’obiettivo è quello di fornire ai ricercatori e agli operatori di NLP una solida comprensione dello stato dell’arte di questa importante area emergente e di evidenziare le sfide principali e le direzioni future per l’apprendimento della rappresentazione di green sentence. L’ecocompatibilità di questi modelli più piccoli è più che altro un effetto collaterale benefico della ricerca di modelli più veloci e facili da implementare. Tuttavia, abbiamo affrontato la questione dal punto di vista della riduzione delle emissioni.
Adottando pratiche e tecniche sostenibili, possiamo sviluppare sentence transformers che non solo offrono prestazioni eccezionali, ma sono anche in linea con i principi della responsabilità ambientale. Questo articolo serve come base per esplorare l’intersezione tra l’apprendimento della rappresentazione delle sentence e la sostenibilità, promuovendo lo sviluppo di modelli efficienti ed ecocompatibili che possono avere un impatto positivo in varie applicazioni NLP.
Tecniche di Natural Language Processing (NLP)
La Green AI per NLP è cresciuta rapidamente negli ultimi anni, con un’ampia gamma di tecniche proposte per migliorare l’efficienza e la sostenibilità.
Un approccio chiave è la quantizzazione, che riduce la precisione dei pesi e delle attivazioni del modello per risparmiare memoria e calcolo. Quantizzazione post-training (Zafrir et al., 2019) e formazione consapevole della quantizzazione (Jacob et al., 2018) hanno dimostrato di poter comprimere significativamente i modelli di tipo BERT con una perdita minima di accuratezza. Framework come la libreria bitsandbytes di Hugging Face consentono di applicare facilmente la quantizzazione a vari modelli linguistici.
Un’altra importante direzione di ricerca è la distillazione della conoscenza (Hinton et al., 2015), che addestra modelli compatti di studenti a emulare i risultati di modelli più grandi di insegnanti. DistilBERT (Sanh et al., 2019) ha aperto la strada all’uso della distillazione per i trasformatori di frase, ottenendo prestazioni di livello BERT con il 40% di parametri in meno. I lavori più recenti hanno esplorato tecniche di distillazione avanzate, come la sostituzione progressiva dei moduli (Xu et al., 2020) e auto distillazione (Zhang et al., 2021) per migliorare ulteriormente l’efficienza dei modelli distillati.
Il model pruning identifica e rimuove i pesi ridondanti o non importanti da un modello di grandi dimensioni. Michel et al. (2019) ha introdotto un metodo di potatura che azzera le teste di attenzione non significative per ridurre i costi di inferenza del BERT. Il framework Prune Once For All (Zafrir et all, 2021) adatta il pruning a diversi vincoli di latenza. Altri lavori hanno esplorato la ricerca di architetture neurali per trovare automaticamente modelli efficienti dal punto di vista hardware (Wan et al., 2020).
Architetture di trasformatori efficienti come Mobile-BERT (Sun et al., 2020) incorporano idee di computer vision per aumentare la velocità e ridurre i parametri. Il Linformer (Wang et al., 2020) e Big Bird (Zaheer et al., 2020) modificare il meccanismo di attenzione per consentire la modellazione di sequenze in tempo lineare. I ricercatori hanno anche sviluppato kernel di attenzione partizionati e sparsi per accelerare l’inferenza dei trasformatori (Kitaev et al., 2020; Beltagy et al., 2020, Liu et al., 2022).
Sono nati anche strumenti per misurare e visualizzare le emissioni di carbonio dei flussi di lavoro dell’IA. Il CodeCarbon library (Courty et al., 2024) può facilmente integrarsi con gli script ML per tracciare e segnalare le emissioni. Gli strumenti di Green Algorithms (Inouye et al., 2020) estende questa idea a dichiarazioni d’impatto sul carbonio complete e algoritmiche. Questi strumenti possono contribuire a sensibilizzare l’opinione pubblica e a promuovere pratiche di formazione e impiego più ecologiche.
Bilanciare efficienza e potenza in NLP
Questo articolo esplora l’applicazione di tecniche di Green AI per la costruzione di trasformatori di frasi efficienti e sostenibili. Mettendo a punto i modelli pre-addestrati e introducendo un modello BERT per il confronto, lo studio dimostra l’impatto dell’architettura del modello sul consumo energetico e sulle emissioni di carbonio.
Lo studio utilizza modelli preaddestrati popolari come “distilbert-base-uncased”, “distilbert-base-cased” e “distilbert-base-multilingue-cased” come modelli di base per la messa a punto. I modelli di DistilBERT sono stati pre-addestrati su grandi corpora e hanno dimostrato ottime prestazioni in vari compiti di incorporazione di frasi. Sfruttando questi modelli pre-addestrati, lo studio mira a ottenere risultati competitivi riducendo al minimo l’impatto ambientale.
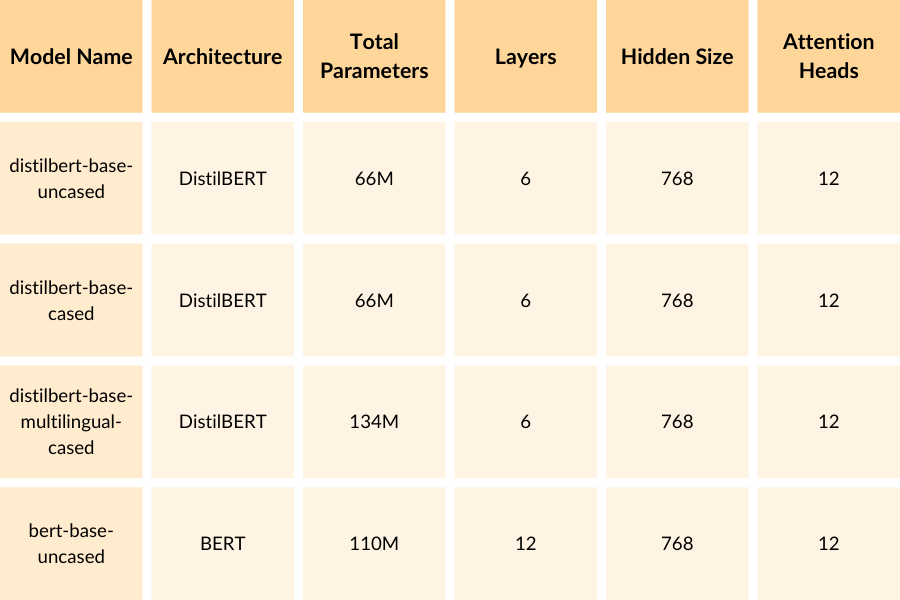
Una breve spiegazione di ogni colonna:
- Model Name: Il nome del modello BERT pre-addestrato utilizzato nel codice.
- Architecture: L’architettura di base del modello. DistilBERT è una versione distillata di BERT, che ha dimensioni più ridotte ma mantiene una parte significativa delle prestazioni di BERT.
- Total Parameters: Il numero totale di parametri addestrabili nel modello. Questo dà un’indicazione della dimensione e della complessità del modello.
- Layers: I livelli sono diversi stadi o fasi del processo di comprensione della frase. Ogni livello si concentra su un aspetto specifico della frase e si basa sulle informazioni del livello precedente. Per esempio, il primo livello potrebbe esaminare le singole parole, il secondo potrebbe considerare la relazione tra le parole e così via. Più strati ci sono, più complessa e dettagliata può essere la comprensione della frase. DistilBERT ha 6 livelli, mentre BERT-base ha 12 livelli.
- Hidden Size: La dimensione nascosta è il numero di caratteristiche o attributi che il modello utilizza per rappresentare i dati di input (in questo caso, le frasi). Ogni caratteristica è un valore numerico che cattura un aspetto o una caratteristica specifica dell’input. Si riferisce alla quantità di informazioni che ogni livello può contenere ed elaborare. Una dimensione nascosta più grande significa che ogni strato può catturare e memorizzare più informazioni sulla frase, consentendo una comprensione più ricca. Tutti i modelli della tabella hanno una dimensione nascosta di 768.
- Attention Heads: Le teste di attenzione sono come punti di attenzione o prospettive diverse all’interno di ogni livello. Per esempio, una testa di attenzione potrebbe concentrarsi sul significato complessivo della frase, mentre un’altra testa di attenzione potrebbe concentrarsi sui dettagli specifici o sul contesto. Avendo più teste di attenzione, il modello può considerare diversi aspetti della frase in parallelo, consentendo una comprensione più completa. Tutti i modelli della tabella hanno 12 teste di attenzione per livello.
Come si può notare, i modelli DistilBERT (distilbert-base-uncased, distilbert-base-cased, distilbert-base-multilingue-cased) hanno circa la metà del numero di parametri rispetto al modello BERT-base (bert-base-uncased). Questo perché DistilBERT è una versione distillata di BERT, che mira a ridurre le dimensioni del modello mantenendo la maggior parte delle sue prestazioni.
Il modello distilbert-base-multilingue-casuale ha un numero maggiore di parametri rispetto agli altri modelli DistilBERT perché è addestrato su più lingue e richiede parametri aggiuntivi per gestire l’aspetto multilingue.
Questi modelli offrono un compromesso tra dimensioni e prestazioni. I modelli DistilBERT sono più leggeri ed efficienti, il che li rende adatti a scenari con risorse computazionali limitate o quando è richiesta un’inferenza più rapida. D’altra parte, il modello BERT-base ha una capacità maggiore e può ottenere prestazioni leggermente migliori su alcuni compiti, ma al costo di maggiori requisiti computazionali.
Oltre ai modelli DistilBERT, lo studio include un modello BERT basato sull’architettura “bert-base-uncased”. Il modello BERT serve come punto di confronto per evidenziare le differenze di consumo energetico tra l’architettura DistilBERT, più compatta, e quella BERT, più grande.
Per quantificare l’impatto ambientale dei modelli, lo studio utilizza la libreria CodeCarbon per tracciare e misurare le emissioni di carbonio durante la fase di inferenza. Ciò evidenzia l’importanza di considerare l’impronta di carbonio non solo durante l’addestramento, ma anche durante la distribuzione e l’utilizzo dei trasformatori di frasi.
Codecarbon è una libreria Python che aiuta gli sviluppatori a monitorare e ridurre le emissioni di anidride carbonica generate dai loro modelli e algoritmi di apprendimento automatico. Stima la quantità di emissioni di CO2 prodotte dalle risorse di calcolo utilizzate durante l’esecuzione del codice Python, tenendo conto di fattori quali il tipo di CPU o GPU, il consumo energetico e la durata dell’esecuzione del codice. Codecarbon si integra con i framework di deep learning più diffusi, come TensorFlow, PyTorch e Keras, oltre che con il codice Python in generale, per tracciare automaticamente il consumo energetico.
Dopo l’esecuzione del codice, Codecarbon genera un report che fornisce informazioni sulle emissioni di anidride carbonica generate, comprese le emissioni totali di CO2, la suddivisione per componente hardware e la localizzazione geografica delle emissioni in base al mix energetico della regione. Queste informazioni consentono agli sviluppatori di prendere decisioni informate per ridurre l’impronta di carbonio ottimizzando il codice, scegliendo algoritmi efficienti o selezionando fornitori di cloud con fonti energetiche più pulite. Codecarbon promuove pratiche di sviluppo dell’intelligenza artificiale sostenibili e aiuta le organizzazioni ad allineare le loro iniziative di apprendimento automatico con gli obiettivi di sostenibilità.
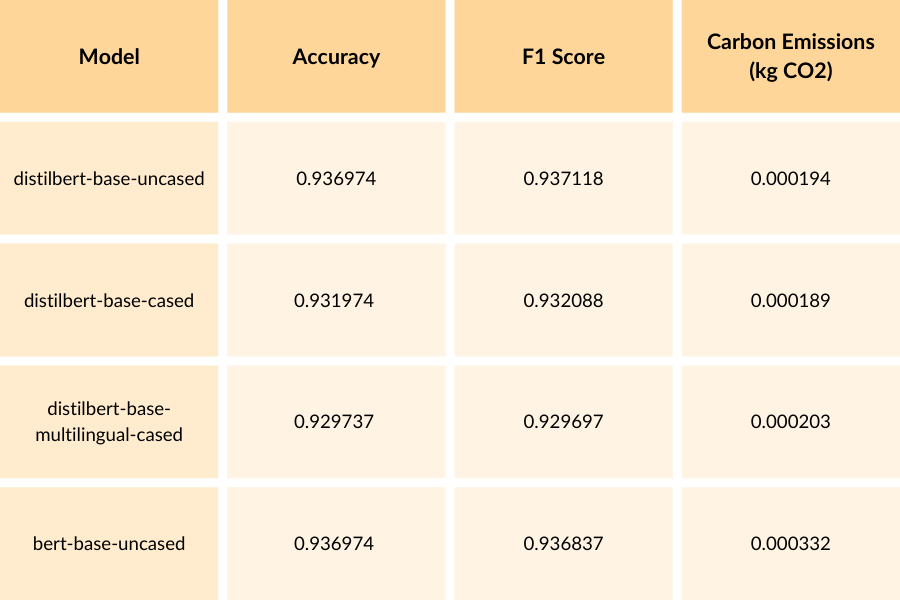
I risultati forniti illustrano le prestazioni e l’utilizzo di energia dei modelli DistilBERT e BERT, ottimizzati, sul dataset AG News. Il dataset AG News è un benchmark ampiamente utilizzato per la classificazione dei testi, contenente articoli di notizie di varie categorie. Valutando i modelli su questo dataset, possiamo valutarne l’efficacia e l’impatto ambientale in un contesto pratico. I modelli DistilBERT ottengono accuratezze comprese tra 0,929737 e 0,936974 e punteggi F1 compresi tra 0,929697 e 0,937118. D’altra parte, il modello BERT raggiunge un’accuratezza di 0,936974 e un punteggio F1 di 0,936837, dimostrando prestazioni comparabili a quelle dei modelli DistilBERT.
Tuttavia, se si considerano le emissioni di carbonio, il modello BERT ha il consumo energetico più elevato, pari a 0,000332 kg CO2e, mentre i modelli DistilBERT hanno un consumo energetico inferiore, compreso tra 0,000189 e 0,000203 kg CO2e. Ciò suggerisce che, sebbene il modello BERT raggiunga prestazioni competitive, ciò avviene al costo di un consumo energetico più elevato rispetto ai modelli DistilBERT.
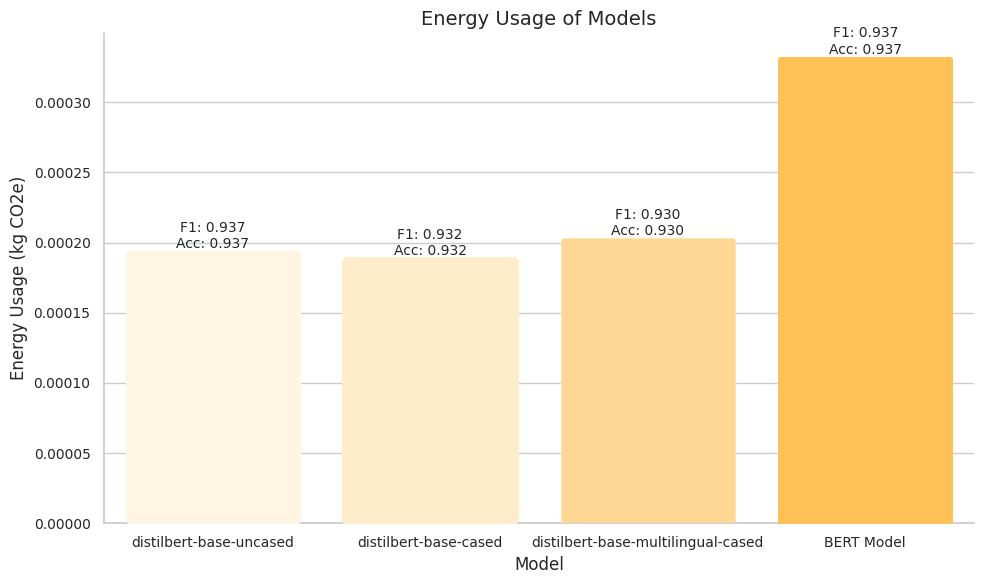
I risultati evidenziano il compromesso tra prestazioni del modello e consumo energetico. Sebbene il modello BERT dimostri risultati competitivi, ha anche un’impronta di carbonio più elevata rispetto ai modelli DistilBERT. Ciò sottolinea l’importanza di considerare l’impatto ambientale nella scelta e nell’impiego dei trasformatori di frase, soprattutto in scenari in cui l’efficienza energetica è una priorità.
È importante notare che le misurazioni del consumo energetico possono variare a seconda dell’hardware specifico e dell’ambiente utilizzato per la formazione e la valutazione. Pertanto, si consiglia di eseguire più esperimenti e di considerare il consumo medio di energia per un confronto più affidabile.
In conclusione, i modelli DistilBERT messi a punto dimostrano prestazioni competitive e un consumo energetico inferiore rispetto al modello BERT. Ciò evidenzia il potenziale dell’uso di architetture più compatte come DistilBERT per raggiungere un equilibrio tra prestazioni e impatto ambientale. Con la continua evoluzione del campo dell’apprendimento della rappresentazione delle frasi, è fondamentale dare priorità alla sostenibilità ed esplorare tecniche che riducano al minimo l’impronta di carbonio mantenendo l’efficacia dei trasformatori di frasi.
Il codice utilizzato in questo studio, sebbene non sia fornito nell’articolo, svolge un ruolo fondamentale nell’implementazione del processo di messa a punto, nella misurazione delle emissioni di carbonio e nella valutazione delle prestazioni dei modelli. Il codice serve come base per riprodurre gli esperimenti, esplorare approcci alternativi e far progredire la ricerca sui trasformatori di frasi sostenibili.
IA responsabile: costruire sistemi NLP sostenibili
Questo articolo ha esplorato il panorama delle tecniche di Green AI per la costruzione di trasformatori di frase efficienti e sostenibili, concentrandosi sul confronto tra i modelli DistilBERT e BERT. Lo studio ha dimostrato che i modelli DistilBERT sono in grado di raggiungere prestazioni competitive, con un consumo energetico inferiore rispetto al modello BERT.
Gli esperimenti e i risultati presentati in questo articolo forniscono indicazioni sull’impatto ambientale di diverse architetture di trasformatori di frasi. Confrontando le emissioni di carbonio dei modelli DistilBERT e BERT, lo studio evidenzia il potenziale dell’uso di architetture più compatte per ridurre l’impronta di carbonio dell’apprendimento della rappresentazione delle frasi.
I risultati di questo articolo sottolineano l’importanza di considerare la sostenibilità insieme alle prestazioni nello sviluppo e nell’impiego dei trasformatori di frasi. Con il continuo progresso dell’elaborazione del linguaggio naturale, è fondamentale dare priorità all’efficienza energetica ed esplorare tecniche che riducano al minimo l’impatto ambientale di questi modelli.
Tuttavia, è importante riconoscere che i risultati presentati in questo studio sono specifici dei modelli e dei set di dati utilizzati. Sono necessarie ulteriori ricerche per analizzare la generalizzabilità di questi risultati su architetture, compiti e domini diversi. Inoltre, lo sviluppo di benchmark e protocolli di valutazione standardizzati per misurare l’impatto ambientale dei trasformatori di frasi sarebbe di grande utilità per la comunità di ricerca.
In conclusione, questo articolo contribuisce al crescente numero di ricerche sull’IA sostenibile e mette in evidenza il potenziale delle tecniche di IA verde per la costruzione di trasformatori di frase efficienti e rispettosi dell’ambiente. Mostrando i compromessi tra prestazioni e consumo energetico, lo studio incoraggia ricercatori e professionisti a considerare l’impatto ambientale dei loro modelli e a esplorare approcci innovativi per ridurre le emissioni di carbonio.
Mentre la comunità NLP continua a spingere i confini dell’apprendimento della rappresentazione delle frasi, è essenziale adottare la sostenibilità come considerazione chiave. Dando priorità all’efficienza energetica ed esplorando tecniche che bilanciano le prestazioni con la responsabilità ambientale, possiamo lavorare per un futuro in cui i trasformatori di frasi non solo eccellono nel loro compito, ma abbiano anche un’impronta di carbonio minima.
Autore: Aditya Mohanty, Data Scientist @ Bitrock