

With the growing environmental impact of large-scale sentence embedding models, there is an urgent need for more sustainable approaches to sentence representation learning. This article surveys the landscape of green AI techniques for creating efficient and eco-friendly sentence transformers.
We review methods such as quantization, pruning, knowledge distillation, and efficient architectures specifically designed for sentence transformers, and discuss tools for measuring and mitigating the carbon footprint of these models.
The goal is to highlight the potential of sustainable AI for building high-performing sentence transformers while minimizing resource usage and emissions. We conclude with a discussion of key challenges and future directions for green sentence representation learning.
Green AI for Sustainable Sentence Transformers
Sentence transformers have revolutionized the field of natural language processing (NLP), enabling powerful and efficient sentence representation learning. These models, such as BERT, RoBERTa, and DistilBERT, have become the backbone of various downstream tasks, including text classification, semantic similarity, and sentiment analysis. By encoding sentences into dense vector representations, sentence transformers capture rich semantic information and enable effective comparison and manipulation of textual data.
However, the success of sentence transformers comes with a significant environmental cost. Training and deploying these models require substantial computational resources and energy consumption, contributing to carbon emissions and raising sustainability concerns. As the demand for sentence embedding models grows across industries and applications, it becomes crucial to develop more efficient and eco-friendly approaches to sentence representation learning.
In response to this challenge, the emerging field of Green AI aims to create sustainable sentence transformers that maintain high performance while minimizing their environmental impact. Green AI techniques, such as quantization, pruning, knowledge distillation, and efficient architectures, have shown promising results in reducing the resource usage and carbon footprint of sentence transformers without compromising their effectiveness.
This article provides a comprehensive survey of the current landscape of Green AI approaches specifically tailored for sentence transformers. We delve into the most promising techniques and tools, discussing their strengths, limitations, and potential for building sustainable sentence embedding models. The goal is to equip NLP researchers and practitioners with a solid understanding of the state-of-the-art in this important emerging area and to highlight key challenges and future directions for green sentence representation learning. The eco-friendliness of these smaller models is more of a beneficial side effect of finding models that are faster and easier to deploy. However we have approached it from the point of view of lower emissions.
By adopting sustainable practices and techniques, we can develop sentence transformers that not only deliver exceptional performance but also align with the principles of environmental responsibility. This article serves as a foundation for exploring the intersection of sentence representation learning and sustainability, promoting the development of efficient and eco-friendly models that can drive positive impact across various NLP applications.
Natural Language Processing (NLP) Techniques
Green AI for NLP has grown rapidly in recent years, with a wide range of techniques proposed for improving efficiency and sustainability.
One key approach is quantization, which reduces the precision of model weights and activations to save memory and computation. Post-training quantization (Zafrir et al., 2019) and quantization-aware training (Jacob et al., 2018) have been shown to significantly compress BERT-style models with minimal accuracy loss. Frameworks like Hugging Face’s bitsandbytes library make it easy to apply quantization to various language models.
Another major research direction is knowledge distillation (Hinton et al., 2015), which trains compact student models to emulate the outputs of larger teacher models. DistilBERT (Sanh et al., 2019) pioneered the use of distillation for sentence transformers, achieving BERT-level performance with 40% fewer parameters. Recent work has explored advanced distillation techniques like progressive module replacement (Xu et al., 2020) and self-distillation (Zhang et al., 2021) to further improve the efficiency of distilled models.
Model pruning identifies and removes redundant or unimportant weights from a large model. Michel et al. (2019) introduced a pruning method that zeroes out insignificant attention heads to reduce BERT’s inference costs. The Prune Once For All framework (Zafrir et all, 2021) adapts pruning to different latency constraints. Other work has explored neural architecture search to automatically find hardware-efficient model designs (Wan et al., 2020).
Efficient transformer architectures like Mobile-BERT (Sun et al., 2020) incorporate ideas from computer vision to boost speed and reduce parameters. The Linformer (Wang et al., 2020) and Big Bird (Zaheer et al., 2020) modify the attention mechanism to enable linear-time sequence modelling. Researchers have also developed partitioned and sparse attention kernels to accelerate transformer inference (Kitaev et al., 2020; Beltagy et al., 2020, Liu et al., 2022).
Tools for measuring and visualizing the carbon emissions of AI workflows have also emerged. The CodeCarbon library (Courty et al., 2024) can easily integrate with ML scripts to track and report emissions. The Green Algorithms tool (Inouye et al., 2020) extends this idea to full algorithmic carbon impact statements. Such tools can help raise awareness and promote greener training and deployment practices.
Balancing Efficiency and Power in NLP
This article explores the application of Green AI techniques for building efficient and sustainable sentence transformers. By fine-tuning pre-trained models and introducing a BERT model for comparison, the study demonstrates the impact of model architecture on energy consumption and carbon emissions.
The study utilizes popular pre-trained models such as ‘distilbert-base-uncased’, ‘distilbert-base-cased’, and ‘distilbert-base-multilingual-cased’ as the base models for fine-tuning. These DistilBERT models have been pre-trained on large corpora and have shown strong performance on various sentence embedding tasks. By leveraging these pre-trained models, the study aims to achieve competitive results while minimizing the environmental impact.
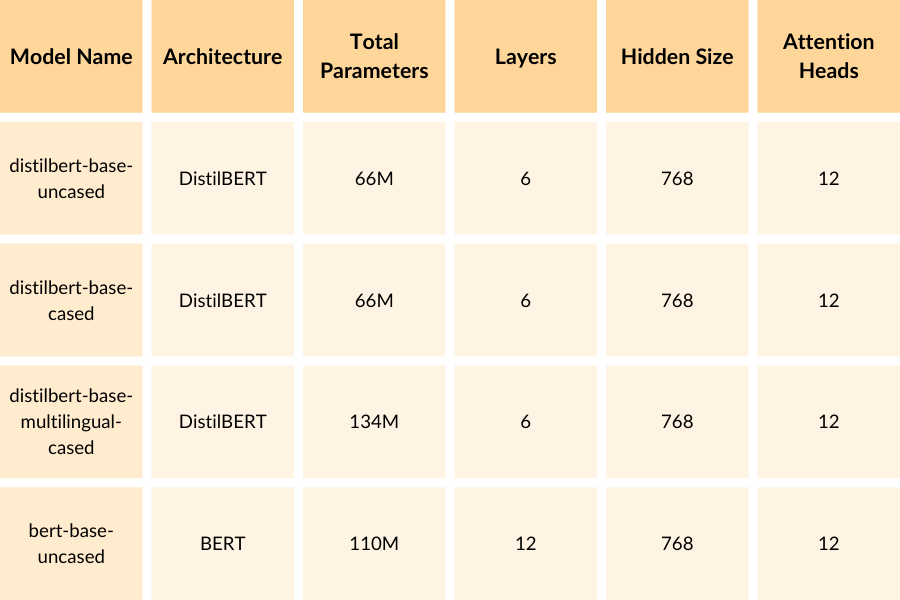
A brief explanation of each column:
- Model Name: The name of the pre-trained BERT model used in the code.
- Architecture: The underlying architecture of the model. DistilBERT is a distilled version of BERT, which has a smaller size but maintains a significant portion of BERT’s performance.
- Total Parameters: The total number of trainable parameters in the model. This gives an indication of the model’s size and complexity.
- Layers: Layers are different stages or steps in the process of understanding the sentence. Each layer focuses on a specific aspect of the sentence and builds upon the information from the previous layer. For example, the first layer might look at individual words, the second layer might consider the relationship between words, and so on. The more layers you have, the more complex and detailed the understanding of the sentence can be. DistilBERT has 6 layers, while BERT-base has 12 layers.
- Hidden Size: Hidden Size is the number of features or attributes the model uses to represent the input data (in this case, sentences). Each feature is a numerical value that captures a specific aspect or characteristic of the input. It refers to the amount of information that each layer can hold and process. A larger hidden size means each layer can capture and store more information about the sentence, allowing for a richer understanding. All the models in the table have a hidden size of 768.
- Attention Heads: Attention heads are like different focus points or perspectives within each layer. For example, one attention head might focus on the overall meaning of the sentence, while another attention head might focus on the specific details or context. By having multiple attention heads, the model can consider different aspects of the sentence in parallel, enabling a more comprehensive understanding. All the models in the table have 12 attention heads per layer.
As you can see, the DistilBERT models (distilbert-base-uncased, distilbert-base-cased, distilbert-base-multilingual-cased) have approximately half the number of parameters compared to the BERT-base model (bert-base-uncased). This is because DistilBERT is a distilled version of BERT, which aims to reduce the model size while retaining most of its performance.
The distilbert-base-multilingual-cased model has a higher number of parameters compared to the other DistilBERT models because it is trained on multiple languages and requires additional parameters to handle the multilingual aspect.
These models offer a trade-off between model size and performance. The DistilBERT models are more lightweight and efficient, making them suitable for scenarios with limited computational resources or when faster inference is required. On the other hand, the BERT-base model has a larger capacity and may achieve slightly better performance on certain tasks, but at the cost of increased computational requirements.
In addition to the DistilBERT models, the study includes a BERT model based on the ‘bert-base-uncased’ architecture. The BERT model serves as a comparison point to highlight the differences in energy consumption between the more compact DistilBERT architecture and the larger BERT architecture.
To quantify the environmental impact of the models, the study employs the CodeCarbon library to track and measure the carbon emissions during the inference phase. This highlights the importance of considering the carbon footprint not only during training but also during the deployment and usage of sentence transformers.
Codecarbon is a Python library that helps developers track and reduce the carbon emissions generated by their machine learning models and algorithms. It estimates the amount of CO2 emissions produced by the computing resources used during the execution of Python code, taking into account factors such as the type of CPU or GPU, power consumption, and duration of code execution. Codecarbon integrates with popular deep learning frameworks like TensorFlow, PyTorch, and Keras, as well as general Python code, to automatically track energy consumption.
After code execution, Codecarbon generates a report that provides insights into the carbon emissions generated, including the total CO2 emissions, breakdown by hardware component, and geographical location of the emissions based on the region’s energy mix. This information empowers developers to make informed decisions to reduce their carbon footprint by optimizing code, choosing efficient algorithms, or selecting cloud providers with cleaner energy sources. Codecarbon promotes sustainable AI development practices and helps organizations align their machine learning initiatives with sustainability goals.
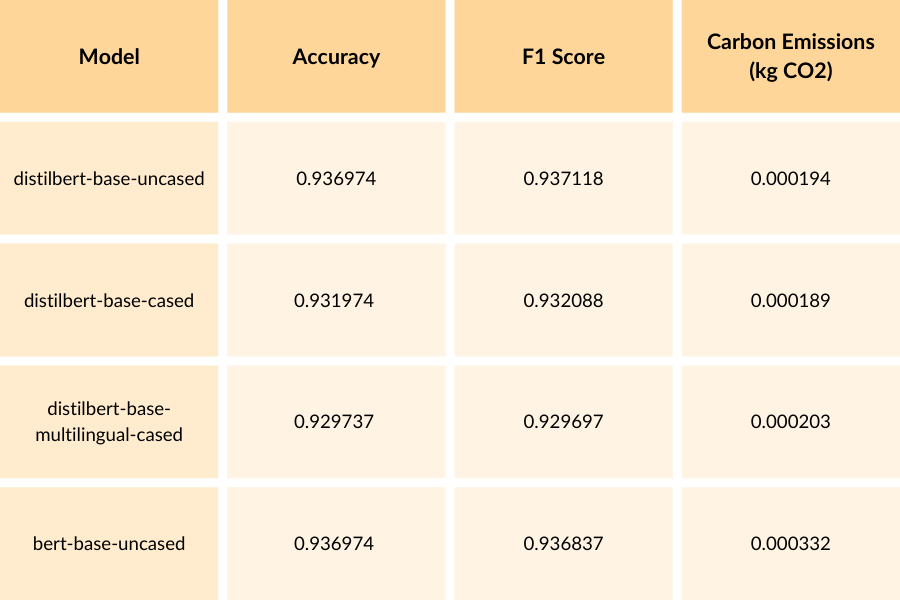
The results provided showcase the performance and energy usage of the fine-tuned DistilBERT models and the BERT model on the AG News dataset. The AG News dataset is a widely used benchmark for text classification, containing news articles from various categories. By evaluating the models on this dataset, we can assess their effectiveness and environmental impact in a practical setting. The DistilBERT models achieve accuracies ranging from 0.929737 to 0.936974 and F1 scores ranging from 0.929697 to 0.937118. On the other hand, the BERT model achieves an accuracy of 0.936974 and an F1 score of 0.936837, demonstrating comparable performance to the DistilBERT models.
However, when considering the carbon emissions, the BERT model has the highest energy usage at 0.000332 kg CO2e, while the DistilBERT models have lower energy consumption, ranging from 0.000189 to 0.000203 kg CO2e. This suggests that although the BERT model achieves competitive performance, it comes at the cost of higher energy consumption compared to the DistilBERT models.
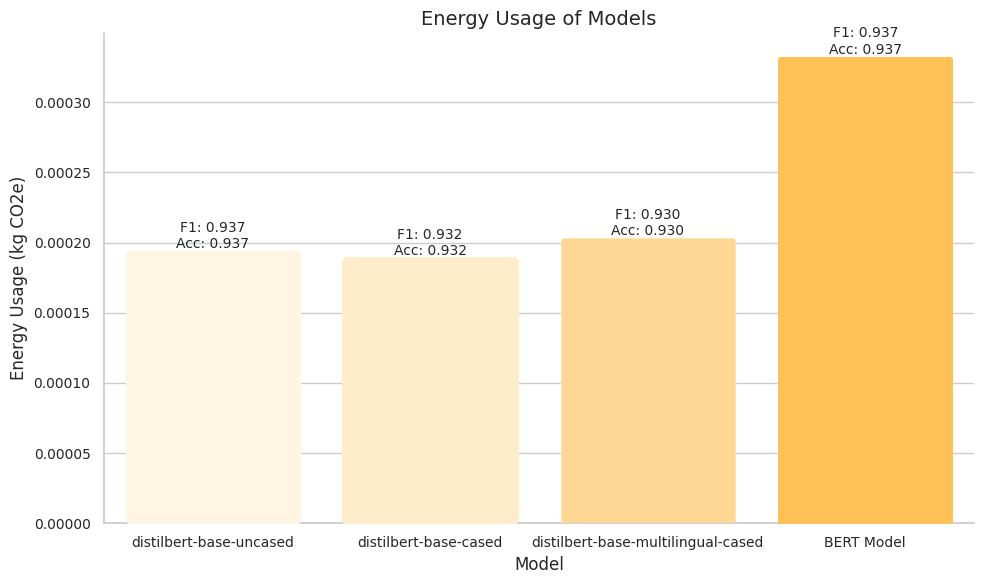
The results highlight the trade-off between model performance and energy usage. While the BERT model demonstrates competitive results, it also has a higher carbon footprint compared to the DistilBERT models. This emphasizes the importance of considering the environmental impact when selecting and deploying sentence transformers, especially in scenarios where energy efficiency is a priority.
It’s important to note that the energy usage measurements may vary depending on the specific hardware and environment used for training and evaluation. Therefore, it’s recommended to run multiple experiments and consider the average energy usage for a more reliable comparison.
In conclusion, the fine-tuned DistilBERT models demonstrate competitive performance while having lower energy consumption compared to the BERT model. This highlights the potential of using more compact architectures like DistilBERT to achieve a balance between performance and environmental impact. As the field of sentence representation learning continues to evolve, it is crucial to prioritize sustainability and explore techniques that minimize the carbon footprint while maintaining the effectiveness of sentence transformers.
The code used in this study, although not provided in the article, plays a crucial role in implementing the fine-tuning process, measuring the carbon emissions, and evaluating the performance of the models. The code serves as a foundation for reproducing the experiments, exploring alternative approaches, and advancing the research in sustainable sentence transformers.
Responsible AI: Building Sustainable NLP Systems
This article explored the landscape of Green AI techniques for building efficient and sustainable sentence transformers, focusing on the comparison between DistilBERT and BERT models. The study demonstrated that DistilBERT models can achieve competitive performance while having lower energy consumption compared to the BERT model.
The experiments and results presented in this article provide insights into the environmental impact of different sentence transformer architectures. By comparing the carbon emissions of DistilBERT and BERT models, the study highlights the potential of using more compact architectures to reduce the carbon footprint of sentence representation learning.
The findings of this article emphasize the importance of considering sustainability alongside performance when developing and deploying sentence transformers. As the field of natural language processing continues to advance, it is crucial to prioritize energy efficiency and explore techniques that minimize the environmental impact of these models.
However, it is important to acknowledge that the results presented in this study are specific to the models and datasets used. Further research is needed to investigate the generalizability of these findings across different architectures, tasks, and domains. Additionally, the development of standardized benchmarks and evaluation protocols for measuring the environmental impact of sentence transformers would greatly benefit the research community.
In conclusion, this article contributes to the growing body of research on sustainable AI and highlights the potential of Green AI techniques for building efficient and environmentally friendly sentence transformers. By showcasing the trade-offs between performance and energy consumption, the study encourages researchers and practitioners to consider the environmental impact of their models and explore innovative approaches to reduce carbon emissions.
As the NLP community continues to push the boundaries of sentence representation learning, it is essential to embrace sustainability as a key consideration. By prioritizing energy efficiency and exploring techniques that balance performance with environmental responsibility, we can work towards a future where sentence transformers not only excel in their task but also have a minimal carbon footprint.
Main Author: Aditya Mohanty, Data Scientist @ Bitrock