

Apache Flink è un framework avanzato per l’elaborazione di eventi in tempo reale, progettato per gestire flussi di dati con latenza minima e massima efficienza. Flink consente l’esecuzione di processi paralleli su grandi volumi di dati, permettendo un’elaborazione distribuita e scalabile. L’unità base di elaborazione in Flink è il job, che esegue una pipeline di elaborazione leggendo da uno o più source, applicando una serie di trasformazioni e scrivendo i risultati su uno o più sink. I source e i sink possono essere tecnologie diverse come Apache Kafka, MongoDB, Cassandra, e molte altre.
In questo articolo, diviso in due parti, esploreremo le principali trasformazioni disponibili in Flink, utilizzando esempi semplificati per illustrare come operare con la DataStream API, una libreria Java che consente di scrivere job per Flink.
Operazioni base e keyBy
Per comprendere come funzionano alcune delle operazioni di base in Apache Flink, consideriamo un caso d’uso semplice.
Immaginiamo di ricevere righe di testo che rappresentano degli acquisti, formattati come customerName-itemId-itemPrice, con i campi separati da un trattino (“-“). Alcune righe possono contenere più acquisti separati da spazi. Ecco alcuni esempi di input:
George-001-13
Harry-010-20 Oliver-033-30
George-089-40 Harry-021-300
Ora proviamo a scrivere un job semplice per trasformare queste righe in oggetti Java, filtrarle, aggregarle ed infine stampare l’informazione sulla console. A tale scopo useremo la libreria Flink Clients versione 1.20.0.

L’oggetto Purchase è definito come segue utilizzando le annotazioni della libreria Lombok:

Dettagli del codice:
- StreamExecutionEnvironment.getExecutionEnvironment(): crea e avvia un ambiente di esecuzione Flink, che gestirà l’intero job di elaborazione del flusso.
- environment.socketTextStream(): apre una connessione socket sulla porta 9999 di localhost per ricevere un flusso di dati testuali in tempo reale. Questo simula una sorgente di dati continua come potrebbe essere una coda di messaggi.
- flatMap(): divide ogni riga in singoli elementi. Le righe che contengono più acquisti (separati da spazi) vengono separate e ogni acquisto viene trattato come un singolo elemento del flusso.
- filter(): mantiene solo le stringhe che contengono un trattino (“-“), garantendo che solo i dati nel formato corretto vengano processati ulteriormente.
- map(): ogni stringa valida viene trasformata in un oggetto di tipo Purchase, estraendo il nome del cliente, l’ID dell’articolo e il prezzo dall’input.
- keyBy(): raggruppa gli acquisti in base al nome del cliente (customerName). Questo partiziona logicamente il flusso in modo che tutti gli acquisti di uno specifico cliente vengano trattati insieme. In Flink, l’operatore keyBy è essenziale per suddividere un flusso di dati in base a una chiave specifica, garantendo che tutte le operazioni su un determinato gruppo vengano eseguite nello stesso task o thread. Ciò facilita la gestione dello stato condiviso e assicura coerenza e integrità durante l’elaborazione.
- sum(): per ogni gruppo, sommiamo i prezzi degli articoli acquistati (itemPrice), ottenendo il totale della spesa per ciascun cliente.
- map(): utilizziamo map per creare un messaggio formattato che mostra quanto ogni cliente ha speso in totale.
- print(): stampa i messaggi formattati per visualizzare i risultati dell’elaborazione. Questo è utile in fase di debug o test per verificare che la trasformazione dei dati sia avvenuta correttamente.
- environment.execute(): l ‘esecuzione del job viene avviata, processando il flusso di dati secondo le trasformazioni definite.
Eseguendo il codice con i dati di esempio sopra, otterremo un output simile al seguente:
7> Customer Harry spent 20 dollars
3> Customer George spent 40 dollars
5> Customer Oliver spent 30 dollars
7> Customer Harry spent 320 dollars
3> Customer George spent 53 dollars
Ogni riga di output rappresenta l’aggregazione della spesa totale per un cliente specifico. Il numero prima del simbolo > indica il thread che ha eseguito l’operazione di stampa. In questo caso, i messaggi sono stati elaborati da thread diversi a seconda della chiave di partizionamento. Questo evidenzia la natura parallela dell’elaborazione in Flink, dove le operazioni sono distribuite tra più thread per ottimizzare le performance.
Gestione delle finestre temporali
Apache Flink supporta l’elaborazione basata su finestre temporali e offre diversi tipi di finestre.
Le finestre temporali come le Tumbling Window dividono i dati in intervalli di tempo fissi e non sovrapposti, mentre le Sliding Window si sovrappongono e si aggiornano continuamente in base a un intervallo di scivolamento definito. Le Session Window si chiudono dopo un periodo di inattività, aprendo nuove finestre se arrivano eventi successivi.
Le finestre temporali possono essere definite in relazione al Tempo di Evento (EventTime), che si basa sul momento in cui i dati sono stati originariamente creati, e il Tempo di Ingestione (ProcessingTime), che si riferisce al tempo del sistema quando gli eventi vengono elaborati. Il Tempo di Evento è utile per gestire eventi che arrivano in ritardo o fuori ordine, mentre il Tempo di Ingestione è più semplice e adatto a scenari in cui la precisione temporale non è critica.
Nell’esempio seguente, utilizziamo l’operatore window per definire una finestra di elaborazione temporale su base di 20 secondi rispetto al tempo di ingestione e l’operatore aggregate per sommare i prezzi degli articoli acquistati da ciascun cliente, conteggiando anche il numero di articoli.
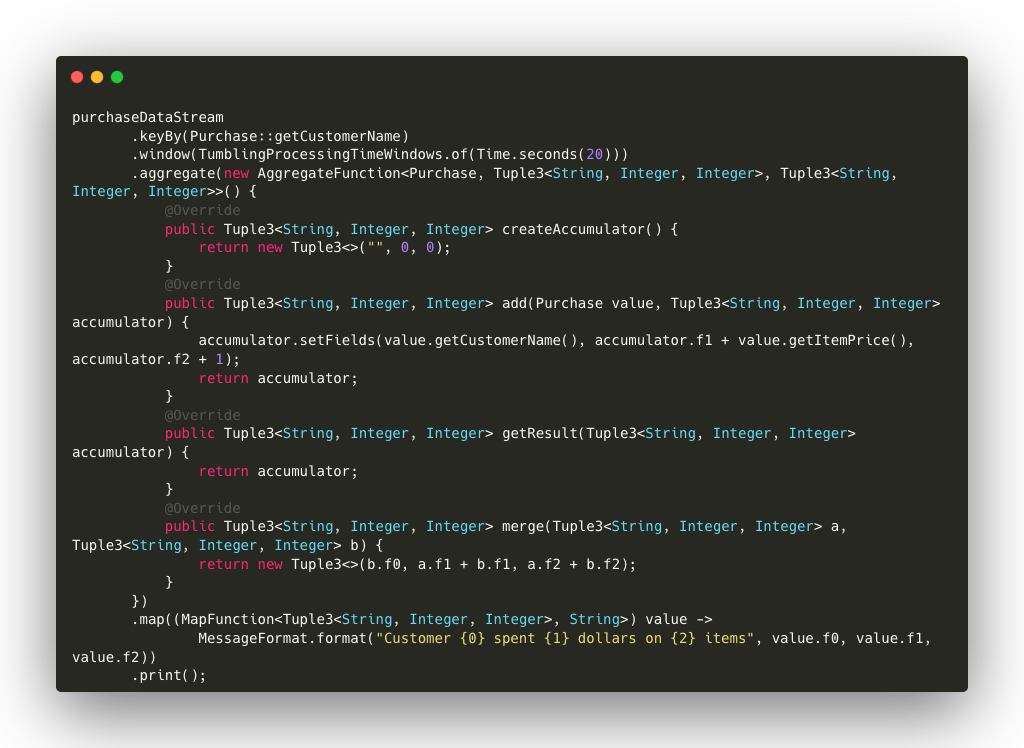
Dettagli del codice:
- keyBy(): raggruppiamo gli acquisti per cliente in modo che ciascun cliente venga trattato come un gruppo.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))): definiamo una finestra temporale che si ripete ogni 20 secondi. Ogni finestra raccoglie gli acquisti effettuati in questo intervallo di tempo e li invia all’aggregazione.
- aggregate(): usiamo una funzione di aggregazione personalizzata per sommare il prezzo totale degli acquisti e contare quanti articoli sono stati acquistati:
- createAccumulator(): inizializziamo l’accumulatore come una tupla che contiene il nome del cliente, il totale speso e il numero di articoli.
- add(): ad ogni acquisto, sommiamo il prezzo dell’articolo e incrementiamo il conteggio degli articoli.
- getResult(): al termine della finestra temporale, restituiamo l’accumulatore.
- merge(): nel caso in cui sia necessario unire due accumulatori (ad esempio, durante il ridimensionamento del cluster), sommiamo i valori accumulati.
- map(): dopo l’aggregazione, formattiamo il risultato in una stringa leggibile per la stampa.
- print(): stampiamo il risultato dell’elaborazione della finestra.
L’input può rimanere lo stesso dell’esempio precedente, ma in questo caso l’output mostrerà il totale speso per tutti gli articoli solo all’interno della finestra temporale specificata, basata sul tempo di arrivo degli eventi. All’interno di questa finestra temporale, sarà inoltre indicato il numero totale di articoli acquistati.
Conclusioni
Abbiamo esplorato solo alcune delle molte funzioni disponibili in Apache Flink, ma anche queste offrono ampie possibilità per implementazioni avanzate e personalizzate.
Flink offre un’ampia gamma di funzionalità per l’elaborazione di flussi di dati, rendendolo uno strumento potente e flessibile per la gestione di applicazioni in tempo reale. Grazie alla DataStream API, è possibile eseguire operazioni complesse in modo intuitivo, sfruttando appieno la scalabilità e le capacità di elaborazione distribuita di Flink.
Nella seconda parte di questo articolo, proseguiremo l’esplorazione delle operazioni applicabili sui flussi di dati, concentrandoci in particolare su come unire e aggregare informazioni provenienti da due o più flussi distinti.
Autore: Anton Cucu, Software Engineer @ Bitrock