

Apache Flink is an advanced real-time event processing framework designed to handle data streams with minimal latency and maximum efficiency. Flink allows the execution of parallel processes on large volumes of data, enabling distributed and scalable processing. The basic processing unit in Flink is the job, which executes a processing pipeline by reading from one or more sources, applying a series of transformations and writing the results to one or more sinks. Sources and sinks can be different technologies such as Apache Kafka, MongoDB, Cassandra, and many others.
In this article, which is divided into two parts, we will explore the main transformations available in Flink, using simplified examples to illustrate how to work with the DataStream API, a Java library that allows jobs to be written for Flink.
Basic Operations and KeyBy
In order to understand how some of the basic operations in Apache Flink work, let us take a look at a simple use case.
Let’s imagine that we receive lines of text representing purchases, formatted as customerName-itemId-itemPrice, with the fields separated by a hyphen (‘-’). Some lines may contain several purchases separated by spaces. Here are some examples of input:
George-001-13
Harry-010-20 Oliver-033-30
George-089-40 Harry-021-300
Now let’s try to write a simple job to transform these lines into Java objects, filter them, aggregate them and finally print the information to the console. We will use the flink-clients library version 1.20.0 for this purpose.

The Purchase object is defined as follows using annotations from the Lombok library:

Code details:
- StreamExecutionEnvironment.getExecutionEnvironment(): creates and starts a Flink execution environment, which will handle the entire stream processing job.
- environment.socketTextStream(): opens a socket connection on port 9999 of localhost to receive a real-time textual data stream. This simulates a continuous data source such as a message queue.
- flatMap(): divide each row into individual elements. Rows containing multiple purchases (separated by spaces) are separated and each purchase is treated as a single element of the stream.
- filter(): retains only strings containing a hyphen (‘-’), ensuring that only data in the correct format is processed further.
- map(): each valid string is transformed into an object of type Purchase, extracting the customer name, item ID and price from the input.
- keyBy(): regroups purchases according to the customer name (customerName). This logically partitions the flow so that all purchases of a specific customer are processed together. In Flink, the keyBy operator is essential for partitioning a data stream according to a specific key, ensuring that all operations on a specific group are executed in the same task or thread. This facilitates shared state management and ensures consistency and integrity during processing.
- sum(): for each group, we sum the prices of the items purchased (itemPrice), obtaining the total expense for each customer.
- map(): we use map to create a formatted message showing how much each customer spent in total.
- print(): print the formatted messages to display the results of the processing. This is useful when debugging or testing to check that the data processing has been done correctly.
- environment.execute(): the job execution is started, processing the data stream according to the defined transformations.
Running the code with the example data above will produce output similar to the following:
7> Customer Harry spent 20 dollars
3> Customer George spent 40 dollars
5> Customer Oliver spent 30 dollars
7> Customer Harry spent 320 dollars
3> Customer George spent 53 dollars
Each output line represents the aggregation of the total expense for a specific customer. The number before the > symbol indicates the thread that performed the output operation. In this case, the messages were processed by different threads depending on the partitioning key. This highlights the parallel nature of processing in Flink, where operations are distributed among several threads to optimize performance.
Time Window Management
Apache Flink supports processing based on time windows and offers different types of windows.
Time windows such as Tumbling Windows divide the data into fixed, non-overlapping time intervals, while Sliding Windows overlap and update continuously according to a defined sliding interval. Session windows close after a period of inactivity, opening new windows if subsequent events arrive.
Time windows can be defined in relation to the Event Time (EventTime), which is based on the time when the data was originally created, and the Ingestion Time (ProcessingTime), which refers to the system time when events are processed. Event Time is useful for handling events that arrive late or out of order, while Ingestion Time is simpler and suitable for scenarios where time accuracy is not critical.
In the following example, we use the window operator to define a processing time window on a 20-second basis with respect to the ingestion time and the aggregate operator to sum up the prices of the items purchased by each customer, also counting the number of items.
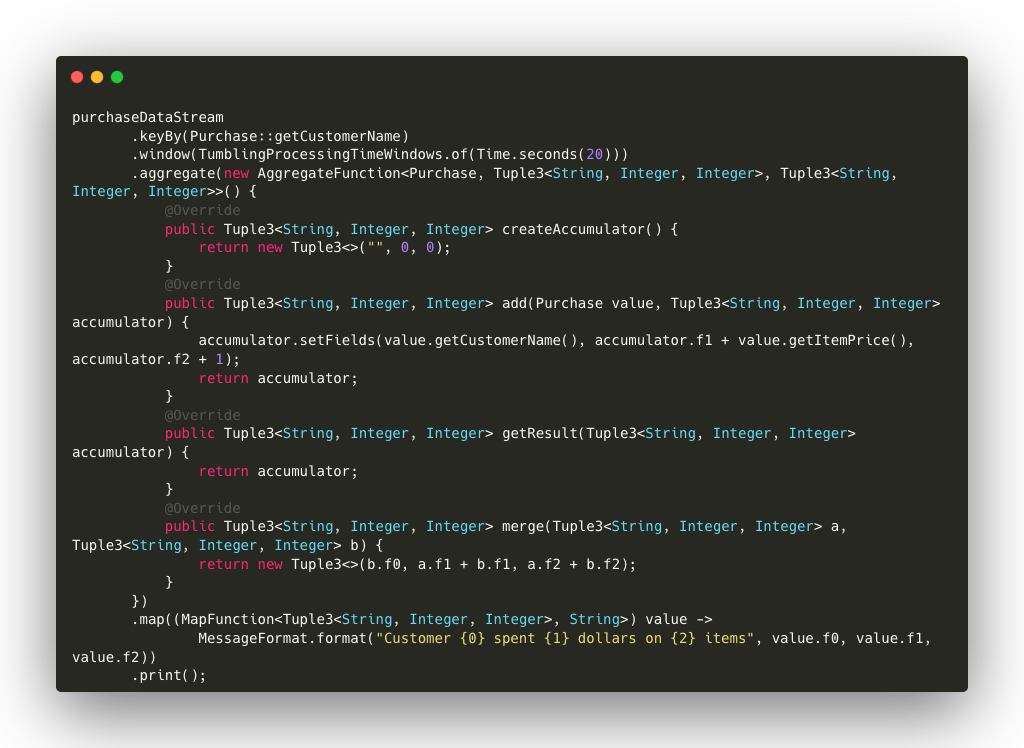
Code details:
- keyBy(): we group purchases by customer so that each customer is treated as a group.
- window(TumblingProcessingTimeWindows.of(Time.seconds(20))): we define a time window that repeats every 20 seconds. Each window collects the purchases made during this time interval and sends them to the aggregation.
- aggregate(): we use a custom aggregation function to sum up the total price of purchases and count how many items have been purchased:
- createAccumulator(): we initialize the accumulator as a tuple containing the name of the customer, the total spent and the number of items.
- add(): for each purchase, we add the item price and increment the item count.
- getResult(): at the end of the time window, we return the accumulator.
- merge(): in case it is necessary to merge two accumulators (e.g. during cluster resizing), we sum the accumulated values.
- map(): after aggregation, we format the result into a readable string for printing.
- print(): we print the result of the window processing.
The input can remain the same as in the previous example, but in this case the output will only show the total spent for all items within the specified time window, based on the arrival time of the events. Within this time window, the total number of items purchased will also be shown.
Conclusions
We have only explored a few of the many functions available in Apache Flink, but even these offer ample possibilities for advanced and customized implementations.
Flink offers a wide range of functionality for processing data streams, making it a powerful and flexible tool for managing real-time applications. Thanks to the DataStream API, complex operations can be performed intuitively, taking full advantage of Flink’s scalability and distributed processing capabilities.
In the second part of this article, we will continue our exploration of applicable operations on data streams, focusing in particular on how to merge and aggregate information from two or more different streams.
Main Author: Anton Cucu, Software Engineer @ Bitrock