

AI and Machine Learning Engineering are becoming increasingly popular topics, and staying up to date on trends is critical to avoid falling behind. We at Bitrock are always on the cutting edge through constant updating and training: to help everyone navigate the AI world, we have created a sort of compass with a description and explanation of the most common terms you will encounter when hearing about Artificial Intelligence, Machine Learning, and Data Engineering.
AI Engineering
AI Engineering relies on the implementation of AI models so as to incorporate them into the software development lifecycle and make them more resilient and reliable. This technique seeks to make Machine Learning-powered software reproducible, testable, and evolvable, guaranteeing that models are deployed and updated in a controlled and efficient manner. MLOps is essential because they can increase the speed and reliability of ML model deployment, while also lowering the chance of errors and enhancing overall model performance.
Binary Classification
Binary classification is a supervised Machine Learning task where the goal is to classify the elements of a data set into one of two possible categories or groups, each called a class, so it is a special case of classification where there are exactly two classes. For example, it is used to solve problems such as fraud detection (fraudulent or legitimate). The output of the model is a binary decision, often represented as 0 or 1, true or false, indicating the predicted class for each input instance. Evaluation metrics such as accuracy, precision, recall, and F1 score are commonly used to assess the performance of binary classification models.
Concept Drift
Concept Drift occurs in dynamic and non-stationary environments where data distributions may change over time. Concept Drift refers to changes in the conditional distributions of what is typically defined as the target variable, given a set of input values whose distributions remain unchanged. For example, in a classification task, concept drift can be formally described as the difference in the joint distributions of the target (y) and the features (X) measured between time t0 and time t1, where the prior probabilities of the classes or the conditional probabilities of the classes between X and y may change.
Data Lake & Data Lakehouse
A Data Lake is a centralized repository that can store and manage all of your structured and unstructured data at any size. They are traditionally focused on advanced data processing of operational data and machine learning/artificial intelligence.
The Data Lakehouse concept combines a durable storage layer with a processing engine (e.g. Spark, Presto) to boost data-warehousing capabilities, making it suited for analytical workloads as well. This architecture is gaining popularity and is supported by a number of providers, including Databricks AWS, Google Cloud, Starburst, and Dremio, as well as data warehousing vendors such as Snowflake.
Data Drift
Data Drift occurs in dynamic and non-stationary contexts where Data Distributions change over time. Data Drift is the variation in statistical features of data that causes the distributions of two different time points to diverge. Virtual Drift occurs when the distribution of features in a machine learning model changes without influencing the goal distribution. A common example of data drift occurs when a news reader cancels an online newspaper subscription due to the service’s rising price. In this context, price is an important factor, and changes in it may have an impact on the number of customers. If readers continue to subscribe despite the rising price, with no change in the number of subscribers, this indicates a Virtual Drift.
Data Democratization
Data becomes (very) valuable when used to generate information, hints, and actions. To make the magic happen, data must be accessible and available to everyone in the organization. In other words, organizations should invest in a company-wide data-driven culture and strive for true data democratization.
Data should be viewed as a strategic asset that is appreciated and utilized throughout the organization. Managers, beginning at the C-level, should remove barriers and create conditions for those in need of data to access it by eliminating hurdles, bottlenecks, and streamlining processes. Creating a data culture and democratizing data enables organizations to effectively exploit their data assets and improve the usage of data-driven insights.
Explainability
Explainability refers to how to take a Machine Learning model and describe what happens inside it from input to output. For example, using model agnostic methods such as SHAP or LIME, one can discover meaning between input data attributions and model outputs: this is typically accomplished by perturbing a single prediction input value and understanding how perturbations in a model’s inputs affect the model’s end-prediction.
Feature
A Feature is a collection of independent variables used as input by a machine learning algorithm. The two most typically used types of characteristics are numerical and categorical. The former are composed of numerical values that may be measured (compared, and ordered) on a scale, such as price. The latter are discrete non-numerical items, such as strings, that can be organized into categories such as gender, color, and nationality.
Hallucination
In the context of generative AI, Hallucination refers to the phenomenon where the model produces inaccurate or completely false information with high confidence. This occurs when a generative model, such as a speech model, is asked to generate content for which it has little or no training data. Hallucinations can be mitigated by fine-tuning or techniques such as RAG.
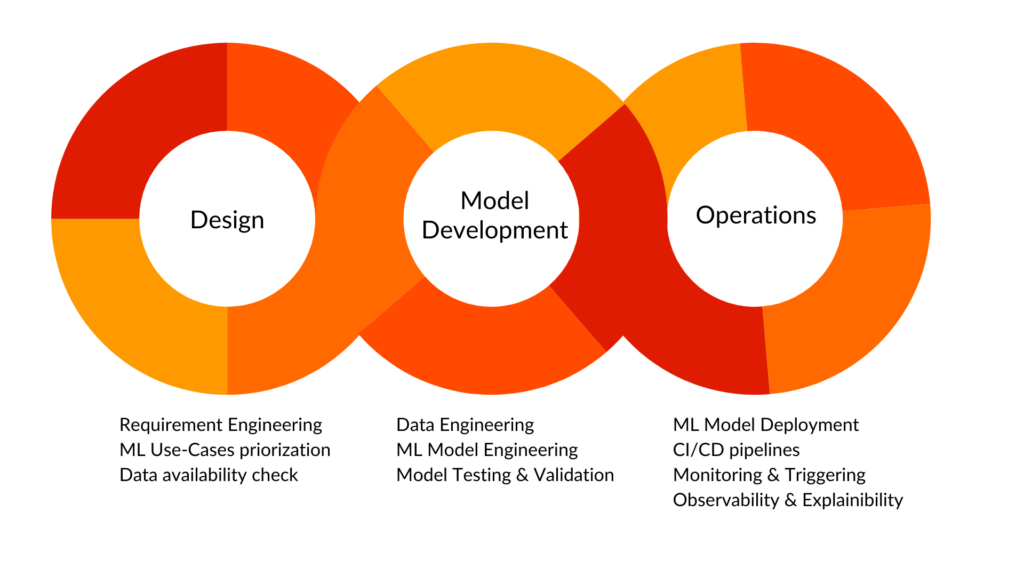
Machine Learning Operations
MLOps is a collection of techniques designed to expedite and unify the entire machine learning lifecycle, from development to deployment and monitoring, by combining DevOps and Data Engineering principles. It includes workflow automation, model and data version management, continuous integration and deployment (CI/CD), and model performance monitoring. MLOps assists organizations in deploying and managing Machine Learning models at scale, ensuring reproducibility, scalability, and dependability across the whole machine learning pipeline.
In this context, how not to mention our sister company’s solution, Radicalbit, a ready-to-use MLOps platform for computer vision, LLMs, and Machine Learning? If you want to find out more, please visit the dedicated website.
Multimodal AI
Multimodal AI are a type of deep learning model that can process different types of input (such as text, images, audio, and so on), and generate different types of output, whereas unimodal models can handle only one type of input, such as only text or only images, and generate output of the same type as the source, such as only text output or only image output.
Observability
AI Observability refers to the ability to have an overall view of an AI solution. In general, it provides tools to measure the performance of a model, identify data integrity issues in input or output, track logs and set alerts to be aware of specific anomalies. Observability is a crucial aspect as it provides everything necessary to ensure transparency and reliability in AI solutions, as well as offering decision support regarding any corrective interventions. The Observability and monitoring capabilities of the above-mentioned Radicalbit platform enable the proactive identification and resolution of problems, optimisation of model performance and reliability of artificial intelligence-based decisions in various fields.
Real Time Machine Learning
Also known as Online Machine Learning, it is the process of training a Machine Learning model by running live data through it to continuously improve the model. This is in contrast to «traditional» Machine Learning, where one builds the model with a batch of historical data in an offline mode.
Retrieval Augmented Generation (RAG)
It’s the process of optimizing the output of a LLM, in such a way that it references an authoritative knowledge base outside of its training data sources before generating a response. Hence RAG extends the capabilities of LLMs to specific domains using an internal knowledge base without the need to retrain the model.
We’ve arrived at the end of our brief tour of some of the most commonly used and well-known terminology in Artificial Intelligence and Machine Learning. Clearly, this brief article cannot be considered exhaustive.
If you have any questions, want to learn more, or would like to submit your own project, please cour Data, AI, and ML Engineering team → https://bitrock.it/contacts