

L’AI e il Machine Learning Engineering stanno diventando argomenti sempre più popolari, e rimanere aggiornati sulle tendenze è fondamentale per non rimanere indietro. Noi di Bitrock siamo sempre all’avanguardia grazie a un aggiornamento e a una formazione continui: per aiutare tutti a orientarsi nel mondo dell’IA, abbiamo creato una sorta di guida con la descrizione e la spiegazione dei termini più comuni che si incontrano quando si parla di Intelligenza Artificiale, Machine Learning e Data Engineering.
AI Engineering
L’ AI Engineering si basa sull’implementazione di modelli di AI in modo da incorporarli nel ciclo di vita dello sviluppo del software e renderli più resistenti e affidabili. Questa tecnica cerca di rendere riproducibile, testabile ed evolvibile il software alimentato dal Machine Learning, garantendo che i modelli siano distribuiti e aggiornati in modo controllato ed efficiente. Gli MLOps sono essenziali perché possono aumentare la velocità e l’affidabilità dell’implementazione dei modelli di ML, riducendo al contempo la possibilità di errori e migliorando le prestazioni complessive dei modelli.
Classificazione binaria
La classificazione binaria è un’attività controllata di Machine Learning in cui l’obiettivo è classificare gli elementi di un insieme di dati in una delle due possibili categorie o gruppi, ciascuno chiamato classe, quindi è un caso speciale di classificazione in cui ci sono esattamente due classi. Ad esempio, viene utilizzata per risolvere problemi come il rilevamento delle frodi (fraudolente o legittime). L’output del modello è una decisione binaria, spesso rappresentata come 0 o 1, vero o falso, che indica la classe prevista per ogni istanza in ingresso. Per valutare le prestazioni dei modelli di classificazione binaria vengono comunemente utilizzate metriche di valutazione quali accuratezza, precisione, richiamo e punteggio F1.
Concept Drift
Il Concept Drift si verifica in ambienti dinamici e non stazionari, dove la data distribution può cambiare nel tempo. Il Concept Drift i si riferisce ai cambiamenti nelle distribuzioni condizionali di quella che viene tipicamente definita come variabile target, dato un insieme di valori di input le cui distribuzioni rimangono invariate. Ad esempio, in un compito di classificazione, il Concept Drift può essere descritto formalmente come la differenza nelle distribuzioni congiunte del target (y) e delle caratteristiche (X) misurate tra il tempo t0 e il tempo t1, dove le probabilità a priori delle classi o le probabilità condizionali delle classi tra X e y possono cambiare.
Data Lake & Data Lakehouse
Un Data Lake è un repository centralizzato in grado di memorizzare e gestire tutti i dati strutturati e non strutturati di qualsiasi dimensione. Sono tradizionalmente incentrati sull’elaborazione avanzata dei dati operativi e sul machine learning/intelligenza artificiale.
Il concetto di data lakehouse combina un livello di archiviazione durevole con un motore di elaborazione (ad esempio Spark, Presto) per potenziare le capacità di data-warehousing, rendendolo adatto anche ai carichi di lavoro analitici. Questa architettura sta guadagnando popolarità ed è supportata da diversi fornitori, tra cui Databricks AWS, Google Cloud, Starburst e Dremio, oltre a fornitori di data warehousing come Snowflake.
Data Drift
Il Data Drift si verifica in contesti dinamici e non stazionari in cui le distribuzioni dei dati cambiano nel tempo. Il Data Drift è la variazione delle caratteristiche statistiche dei dati che fa divergere le distribuzioni di due diversi punti temporali. Il Virtual Drift si verifica quando la distribuzione delle caratteristiche in un modello di Machine Learning cambia senza influenzare la distribuzione dell’obiettivo. Un esempio comune di Data Drift si verifica quando un lettore cancella l’abbonamento a un giornale online a causa dell’aumento del prezzo del servizio. In questo contesto, il prezzo è un fattore importante e le sue variazioni possono avere un impatto sul numero di clienti. Se i lettori continuano ad abbonarsi nonostante l’aumento del prezzo, senza variazioni nel numero di abbonati, ciò indica un Virtual Drift.
Democratizzazione dei dati
I dati diventano (molto) preziosi quando vengono utilizzati per generare informazioni, suggerimenti e azioni. Per far sì che la magia avvenga, i dati devono essere accessibili e disponibili a tutti nell’organizzazione. In altre parole, le organizzazioni dovrebbero investire in una cultura data-driven a livello aziendale e puntare a una vera democratizzazione dei dati.
I dati devono essere visti come una risorsa strategica che viene apprezzata e utilizzata in tutta l’organizzazione. I manager, a partire dal livello C, devono rimuovere le barriere e creare le condizioni per l’accesso ai dati da parte di chi ne ha bisogno, eliminando gli ostacoli e i colli di bottiglia e snellendo i processi. La creazione di una cultura dei dati e la loro democratizzazione consente alle organizzazioni di sfruttare efficacemente il proprio patrimonio di dati e di migliorare l’utilizzo degli insight basati su di essi.
Explainability
L’Explainability si riferisce a come prendere un modello di Machine Learning e descrivere ciò che accade al suo interno dall’input all’output. Ad esempio, utilizzando metodi agnostici rispetto ai modelli, come SHAP o LIME, si può scoprire il significato tra le attribuzioni dei dati di input e gli output del modello: questo si ottiene tipicamente perturbando un singolo valore di input di previsione e comprendendo come le perturbazioni negli input di un modello influenzino la previsione finale del modello.
Feature
Una feature è un insieme di variabili indipendenti utilizzate come input da un algoritmo di Machine Learning. I due tipi di caratteristiche più tipicamente utilizzati sono quelli numerici e categorici. Le prime sono composte da valori numerici che possono essere misurati (confrontati e ordinati) su una scala, come il prezzo. Le seconde sono elementi discreti non numerici, come le stringhe, che possono essere organizzati in categorie come il sesso, il colore e la nazionalità.
Hallucination
Nel contesto dell’IA generativa, l’Hallucination si riferisce al fenomeno per cui il modello produce informazioni imprecise o completamente false con un’elevata sicurezza. Ciò si verifica quando a un modello generativo, ad esempio un modello vocale, viene chiesto di generare contenuti per i quali ha pochi o nessun dato di addestramento. Le Hallucination possono essere attenuate con una messa a punto fine o con tecniche come la RAG.
Machine Learning Operations
MLOps è un insieme di tecniche progettate per accelerare e unificare l’intero ciclo di vita del Machine Learning, dallo sviluppo alla distribuzione e al monitoraggio, combinando i principi di DevOps e Data Engineering. Include l’automazione del flusso di lavoro, la gestione delle versioni dei modelli e dei dati, l’integrazione e la distribuzione continue (CI/CD) e il monitoraggio delle prestazioni dei modelli. MLOps aiuta le organizzazioni a distribuire e gestire i modelli di Machine Learning su scala, garantendo riproducibilità, scalabilità e affidabilità nell’intera pipeline di apprendimento automatico.
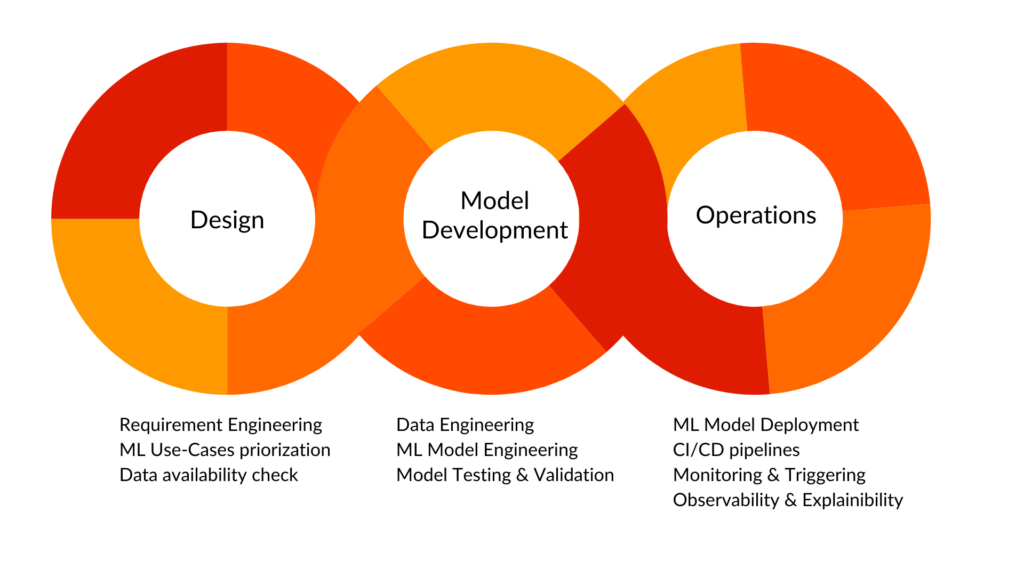
In questo contesto, come non citare la soluzione della nostra consociata, Radicalbit, una piattaforma MLOps pronta all’uso per computer vision, LLM e Machine Learning? Se volete saperne di più, visitate il sito web dedicato.
AI Multimodali
Le AI multimodali sono un tipo di modello di deep learning in grado di elaborare diversi tipi di input (come testo, immagini, audio e così via) e di generare diversi tipi di output, mentre i modelli unimodali possono gestire solo un tipo di input, come solo testo o solo immagini, e generare output dello stesso tipo della sorgente, come solo testo o solo immagini.
Observability
L’ AI Observability si riferisce alla capacità di avere una visione d’insieme di una soluzione di AI. In generale, fornisce strumenti per misurare le prestazioni di un modello, identificare problemi di integrità dei dati in ingresso o in uscita, tenere traccia dei log e impostare avvisi per essere a conoscenza di anomalie specifiche. L’ Observability è un aspetto cruciale in quanto fornisce tutto ciò che è necessario per garantire la trasparenza e l’affidabilità delle soluzioni di IA, oltre a offrire un supporto decisionale per eventuali interventi correttivi.L’Observability e le capacità di monitoraggio della suddetta piattaforma di Radicalbit consentono di identificare e risolvere proattivamente i problemi, di ottimizzare le prestazioni dei modelli e di garantire l’affidabilità delle decisioni basate sull’intelligenza artificiale in vari settori.
Real Time Machine Learning
Noto anche come Online Machine Learning, è il processo di addestramento di un modello di Machine Learning attraverso l’analisi di dati in real time per migliorare continuamente il modello. Ciò è in contrasto con il Machine Learning “tradizionale”, in cui si costruisce il modello con una serie di dati storici in modalità offline.
Retrieval Augmented Generation (RAG)
È il processo di ottimizzazione dell’output di un LLM, in modo che faccia riferimento a una base di conoscenza autorevole al di fuori delle sue fonti di dati di addestramento prima di generare una risposta. Quindi il RAG estende le capacità dei LLM a domini specifici, utilizzando una base di conoscenza interna senza la necessità di riqualificare il modello.
Siamo giunti alla fine del nostro breve tour di alcuni dei termini più comunemente usati e conosciuti nell’ambito dell’Intelligenza Artificiale e del Machine Learning. Chiaramente, questo breve articolo non può essere considerato esaustivo.
Se avete domande, volete saperne di più o volete sottoporci un vostro progetto, contattate il nostro team di Data, AI e ML Engineering → https://bitrock.it/contacts