

Prometheus è un toolkit open-source per il monitoraggio e l’alerting dei sistemi scritto in Go. Rilasciato da SoundCloud nel 2012, si è unito alla Cloud Native Computing Foundation nel 2016 e nel 2018 è diventato il secondo progetto laureato insieme a Kubernetes.
Basato sulle metriche e non sui log, Prometheus utilizza un proprio database di serie temporaliTSDB e un proprio linguaggio di interrogazione (PromQL).
La comunità CNCF adora Prometheus perché:
- è facile da configurare, distribuire e mantenere
- è progettato in più servizi modulari
- è pronto per i container, basta “docker run” per avviarlo
- è pronto per l’orchestrazione, supportando configurazioni dinamiche
- è un ecosistema: ci sono molte librerie client ed exporter mantenuti sia dal team di Prometheus sia dalla comunità
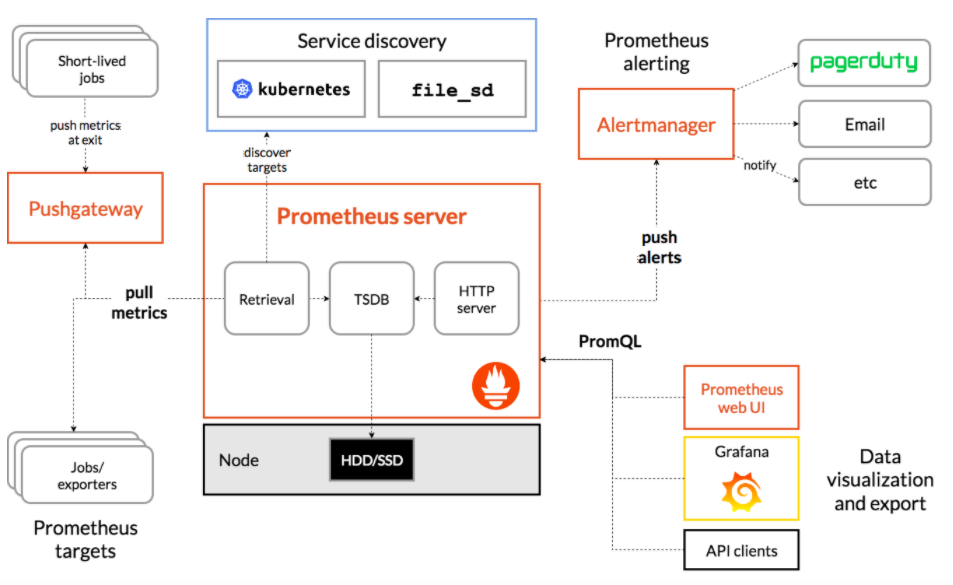
- Prometheus raccoglie i dati
- Gli exporter espongono i dati
- Le applicazioni espongono i dati
- Grafana visualizza i dati
- Alertmanager invia avvisi
Prometheus è un sistema di monitoraggio basato sul metodo pull che esegue lo scrapping delle metriche dagli endpoint configurati, le archivia in modo efficiente e supporta un potente linguaggio di query per comporre informazioni dinamiche da una varietà di punti di dati altrimenti non correlati.
Per monitorare i servizi utilizzando Prometheus, i servizi devono esporre un endpoint di metriche in formato Prometheus. Questo endpoint è un’interfaccia HTTP che espone un elenco di metriche e i rispettivi valori correnti. Prometheus dispone di un’ampia gamma di opzioni di individuazione dei servizi per iniziare a raccogliere i dati delle metriche. Il server Prometheus esegue continuamente il polling dell’endpoint delle metriche sui vostri servizi e memorizza i dati. Questo fornisce un metodo standardizzato per la raccolta delle metriche.
Prometheus è progettato per recuperare i dati a intervalli misurati in secondi. Sebbene Prometheus 2.x sia in grado di gestire una decina di milioni di serie in una finestra temporale, il che è piuttosto generoso, alcune scelte di label poco oculate possono consumare questa cifra in modo sorprendentemente rapido.
Ogni 2 ore Prometheus compatta i dati che sono stati immagazzinati in memoria in blocchi su disco.
Per ridurre l’ingombro su disco, TSDB può avere un periodo di conservazione delle metriche più breve o può essere configurato per avere un limite di spazio su disco. I dati possono essere compattati e anche il WAL può essere compresso.
La struttura dei dati è autosufficiente e può essere spostata da un’istanza all’altra in modo indipendente, dato che ogni serie temporale è atomica e identificata in modo univoco dal nome della metrica (1). Nelle ultime versioni di Prometheus è stato introdotto il supporto per l’archiviazione remota, al fine di fornire un’archiviazione a lungo termine.
Il server centrale di Prometheus è un singolo binario e ogni server Prometheus è un processo indipendente con il proprio storage. Uno degli aspetti negativi di questa implementazione principale è la mancanza di clustering o di backfilling dei dati “mancanti” quando uno scrape fallisce.2

Prometheus non si limita all’uso degli exporter standard (2), ma consente anche di strumentare il proprio codice per raccogliere le metriche rilevanti, inclusi i KPI aziendali. Con il supporto per una vasta gamma di linguaggi (Go, Java o Scala, Python, Ruby, ecc.), è possibile integrare facilmente Prometheus nel proprio stack tecnologico. Inoltre, molte librerie upstream sono già predisposte per l’uso con Prometheus, offrendo una vasta gamma di metriche senza costi aggiuntivi!
Cos’è una metrica?
Una metrica è un valore numerico che indica qualcosa sul funzionamento del sistema. Ad esempio:
- Quanta memoria sta utilizzando?
- Quanto tempo ha richiesto l’ultima operazione?
- Quante richieste sono state servite oggi?
In Prometheus esistono 4 tipi di metriche: counter, gauge, istogramma e summary.
Un counter è una metrica cumulativa che rappresenta un singolo contatore monotonicamente crescente il cui valore può solo aumentare o essere azzerato al riavvio. Ad esempio, si può usare un contatore per rappresentare il numero di richieste servite, di attività completate o di errori.
Un gauge è una metrica che rappresenta un singolo valore numerico che può salire e scendere arbitrariamente. I gaugesono tipicamente utilizzati per i valori misurati, come le temperature o l’utilizzo della memoria corrente, ma anche per i “conteggi” che possono salire e scendere, come il numero di richieste contemporanee.
Un istogramma campiona le osservazioni, ad esempio la durata delle richieste o le dimensioni delle risposte, e le conta in bucket configurabili. Fornisce anche una somma di tutti i valori osservati. Un istogramma con un nome di metrica base di espone più serie temporali durante uno scrape:
- contatori cumulativi per i bucket di osservazione, esposti come _bucket{le=””}
- la somma totale di tutti i valori osservati, esposta come _sum
- il conteggio degli eventi osservati, esposto come _count (identico a _bucket{le=”+Inf”} di cui sopra).
Simile a un istogramma, un summary campiona le osservazioni, ad esempio la durata delle richieste e le dimensioni delle risposte. Sebbene fornisca anche un conteggio totale delle osservazioni e una somma di tutti i valori osservati, calcola quantili su una finestra temporale in movimento.
Un summary espone più serie temporali durante uno scrape:
- la serie temporale dei φ-quantili (0 ≤ φ ≤ 1) degli eventi osservati, esposti come {quantile=”<φ>”}
- la somma totale di tutti i valori osservati, esposta come _sum
- il conteggio degli eventi osservati, esposto come _count
La differenza essenziale tra summary e istogrammi è che le sommatorie calcolano i φ-quantili on the flylato client e li espongono direttamente, mentre gli istogrammi espongono i conteggi delle osservazioni in bucket e il calcolo dei quantili dai bucket di un istogramma avviene sul lato server utilizzando la funzione histogram_quantile().
https://prometheus.io/docs/concepts/metric_types/
https://prometheus.io/docs/practices/histograms/
Comprendere le metriche
Le metriche di Prometheus hanno un nome e possono avere un numero arbitrario di etichette:
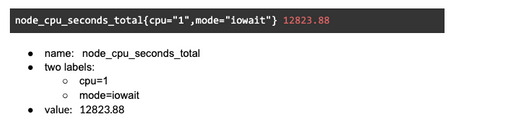
Una metrica ha dei metadati (etichette) e molte funzioni per filtrarli, modificarli, rimuoverli mentre li recupera dai target. Il nome “node_cpu_seconds_total” consiste in un prefisso per lo spazio dei nomi (metriche del nodo) e un suffisso per l’unità del valore (secondi di tempo di CPU in totale).
https://prometheus.io/docs/practices/naming/
promtool permette di effettuare del linting per verificarne la coerenza e la correttezza.
Esempi:

PromQL
Prometheus Query Language (PromQL) supporta un’ampia gamma di funzioni per interagire con le metriche di scraping. Alcuni esempi:
- Filtraggio per etichetta: _http_requeststotal{status=~“5..”}
- Calcolo dei rate: _rate(http_requeststotal[5m])
- Operazioni aritmetiche ( +, *, /, -, %, ^) e di confronto ( >, <, >=, <=, ==, != )
- Aggregazione e raggruppamento: _sum(rate(node_network_receive_bytestotal[5m])) per (istanza)
- Quantile: _histogram_quantile(0,95, sum(rate(http_request_duration_secondsbucket[5m])) per (le))
- Recording Rules: precompilare le espressioni più frequenti o più costose dal punto di vista computazionale, per rendere più veloce l’elaborazione delle query ricorrenti.
Allarme
Il nostro motto è: se si può disegnare, si può allertare! È davvero facile impostare gli avvisi in Prometheus, basta definire la query da valutare e l’intervallo di valori:

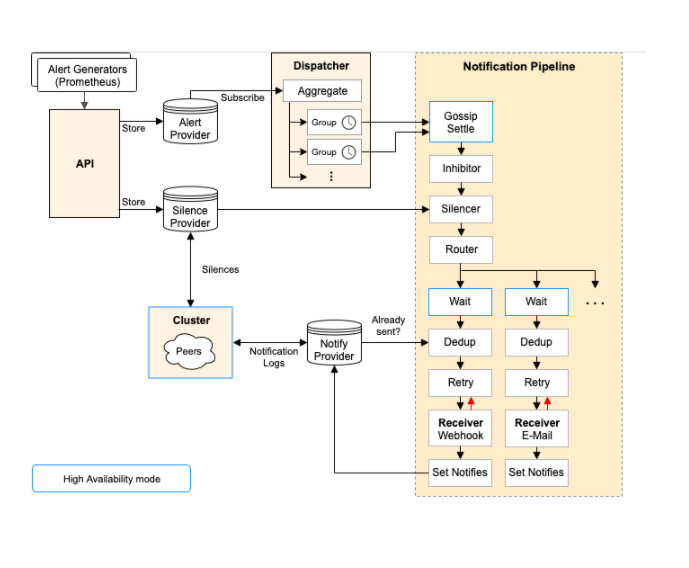
Prometheus valuterà regolarmente la regola di avviso e la contrassegnerà come attiva se la regola corrisponde. Tuttavia, il componente centrale di Prometheus non si occuperà direttamente dell’invio degli avvisi agli utenti finali. Alertmanager si occuperà invece di eseguire le operazioni relative agli avvisi.
Alertmanager :
- Riceve gli avvisi da Prometheus
- Li raggruppa
- li inibisce, ad esempio in caso di falsi positivi
- Li invia ai servizi a valle, come Slack o PagerDuty e molti altri.
- HA integrato che sfrutta il protocollo gossip
Referenze
- Documentazione ufficiale del progetto https://prometheus.io/docs/
- Un blog sul monitoraggio, la scala e la sanità operativa https://www.robustperception.io/blog
- https://github.com/prometheus/alertmanager#high-availability
Note
(2)[https://prometheus.io/docs/instrumenting/exporters]
https://github.com/prometheus/prometheus/wiki/default-port-allocations
Autore: Matteo Gazzetta, DevOps Engineer @Bitrock