

Molti di voi hanno probabilmente sentito la frase “i dati sono il nuovo petrolio“, e questo perché ogni cosa nel nostro mondo produce informazioni preziose. Sta a noi essere in grado di estrarre il valore da tutti i dati rumorosi e disordinati che vengono prodotti ogni istante.
Ma lavorare con i dati non è facile: come abbiamo visto prima, i dati reali sono sempre rumorosi, disordinati e spesso incompleti, e anche il processo di estrazione a volte soffre di alcuni difetti.
È quindi molto importante rendere i dati utilizzabili attraverso un processo noto come data wrangling (ovvero il processo di pulizia, strutturazione e arricchimento dei dati grezzi nel formato desiderato) per migliorare il processo decisionale. L’aspetto cruciale da comprendere è che i dati scadenti portano a decisioni sbagliate, quindi è importante rendere questo processo stabile, ripetibile e idempotente, per garantire che le nostre trasformazioni migliorino la qualità dei dati e non la degradino.
Vediamo uno degli aspetti del processo di data wrangling: come gestire le fonti di dati che non possono garantire la qualità di ciò che forniscono.
Il contesto
In un recente progetto in cui siamo stati coinvolti, abbiamo affrontato uno scenario in cui le fonti di dati erano fortemente inaffidabili.
In base alle prime definizioni, i dati attesi, provenienti da una serie di sensori, avrebbero dovuto essere:
- circa dieci tipi di dati diversi
- ogni tipo a un ritmo fisso (ogni 10 minuti)
- i dati arriveranno in un bucket di atterraggio
- i dati saranno in formato CSV, con uno schema predefinito e un numero fisso di righe.
A partire da questi dati, avremmo eseguito la validazione, la pulizia e l’aggregazione, al fine di calcolare alcuni KPI. Questi KPI erano il punto di partenza di una successiva previsione basata sul Machine Learning.
Inoltre, era necessario produrre rapporti e previsioni aggiornati ogni 10 minuti con le informazioni più recenti ricevute.
Come in molti progetti reali nel mondo dati, i dati di partenza presentavano diversi problemi, come dati mancanti nel CSV (a volte mancava qualche valore in alcune celle, mancavano intere righe, oppure presentavano righe duplicate), o dati che arrivavano in ritardo (addirittura non arrivavano affatto).
La soluzione
In scenari simili, è fondamentale tenere traccia delle trasformazioni che la pipeline dati applicherà ed essendo capaci di rispondere a domande come queste:
- quali sono i valori di origine di un determinato risultato?
- il valore di un risultato proviene da dati reali o da dati imputati?
- tutte le fonti sono arrivate in tempo?
- quanto è affidabile un determinato risultato?
Per poter rispondere a questo tipo di domande, dobbiamo prima isolare i diversi tipi di dati, in almeno tre aree:

In particolare, la Landing Area è un luogo in cui i sistemi esterni (cioè le fonti di dati) scrivono, mentre la pipeline dati può solamente leggere o cancellare dopo un tempo di conservazione sicuro.
Nella Raw Area, invece, copieremo i CSV dalla Landing Area mantenendo i dati così come sono, ma arricchendone i metadati (ad esempio etichettando il file o inserendolo in una struttura di cartelle meglio organizzata). Questo sarà il nostro Data Lake dal quale potremo sempre recuperare i dati originali, sia in caso di errori durante l’elaborazione o in caso di sviluppo di una nuova funzionalità.
Infine, nella Processed Area conserviamo i dati convalidati e puliti. Quest’area sarà il punto di partenza per la componente di Visualizzazione e la componented di Machine Learning.
Dopo aver definito le tre aree precedenti per memorizzare i dati, dobbiamo introdurre un altro concetto che ci permette di tracciare le informazioni attraverso la pipeline: il Run Control Value (valore di controllo dell’esecuzione).
Il valore di controllo dell’esecuzione è un metadato, spesso un valore seriale o un timestamp, o altro, e ci dà la possibilità di correlare i dati nelle diverse aree con le esecuzioni della pipeline.
Questo concetto è abbastanza semplice da implementare, ma non è così ovvio da capire. D’altra parte, è facile essere tratti in inganno; qualcuno potrebbe pensare che sia superfluo e che possa essere rimosso in favore di informazioni già presenti nei dati, come un timestamp, ma sarebbe sbagliato.
Vediamo ora, con alcuni esempi, i vantaggi dell’utilizzo della separazione dei dati descritta sopra, insieme al Run Control Value.
Esempio 1: Tracciamento dell’imputazione dei dati
Consideriamo innanzitutto uno scenario in cui l’output è strano e sembra apparentemente sbagliato. La colonna RCV rappresenta il Run Control Value e viene aggiunta dalla pipeline.
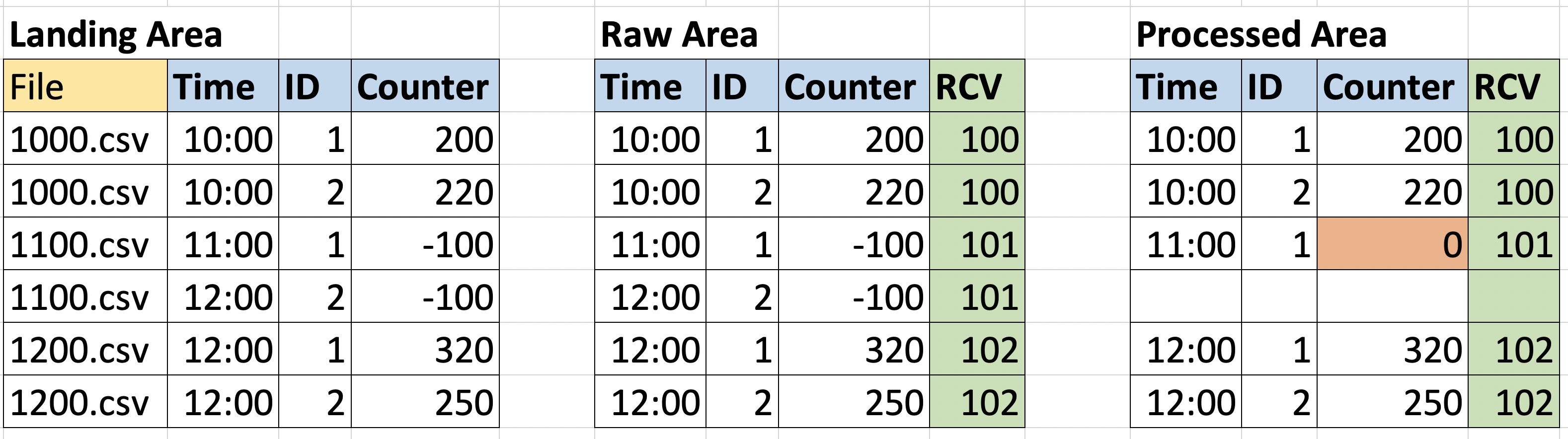
Qui possiamo vedere che, se guardiamo solo ai dati elaborati, per l’input alle ore 11:00 manca la voce con ID=2, e il contatore con ID=1 ha uno strano zero come valore (supponiamo che il nostro esperto di dominio abbia detto che gli zeri nella colonna del contatore sono anomali).
In questo caso, possiamo risalire alle fasi della pipeline, usando il Run Control Value, e vedere quali valori hanno concretamente contribuito all’output, se tutti gli input erano disponibili nel momento in cui il calcolo è stato eseguito, o se alcuni file mancavano nella Raw Area e quindi sono stati completati con i valori imputati.
Nell’immagine qui sopra, si può notare che nella Raw area gli input con RCV=101 erano entrambi negativi, e l’entità con ID=2 è relativa a time=12:00. Se poi si controlla il file originale nella Landing Area, si può notare che questo file era denominato 1100.csv (nell’immagine rappresentato come una coppia di righe di tabella per semplicità), quindi la voce relativa all’ora 12:00 era un errore; la voce è stata quindi rimossa nella Processed Area, mentre l’altra è stata azzerata da una regola di imputazione.
La soluzione di mantenere la Landing Area distinta dalla Raw Area ci permette di gestire anche il caso di dati arrivati in ritardo.
Dato lo scenario descritto all’inizio dell’articolo, riceviamo i dati in batch con uno scheduler che guida l’ingestione. Quindi, cosa succede se, al momento dell’ingestione programmata, uno degli input era mancante ed è stato soddisfatto con i valori imputati, ma, al momento del debug, possiamo vedere che è disponibile?
In questo caso, sarà disponibile nella Landing Area ma mancherà nella Raw area; quindi, senza nemmeno aprire il file per controllare i valori, possiamo capire rapidamente che per quella specifica corsa, quei valori sono stati imputati.
Esempio 2: Errore dalle fonti con la ripresentazione dei dati in input
Nel primo esempio abbiamo discusso di come analizzare retrospettivamente l’elaborazione o di come eseguire il debug. Consideriamo ora un altro caso: una fonte con un problema ha inviato dati errati in una determinata esecuzione; dopo che il problema è stato risolto, vogliamo analizzare nuovamente i dati per la stessa esecuzione per aggiornare il nostro output, e ri-eseguirlo nello stesso contesto.
L’immagine seguente mostra lo stato del data warehouse quando l’input alle ore 11.00 presenta un paio di problemi: la voce conID=2 è mancante e la voce ID=1 ha un valore negativo e abbiamo una regola di convalida per convertire in zero i valori negativi. Quindi la tabella Processed Area contiene i dati convalidati.
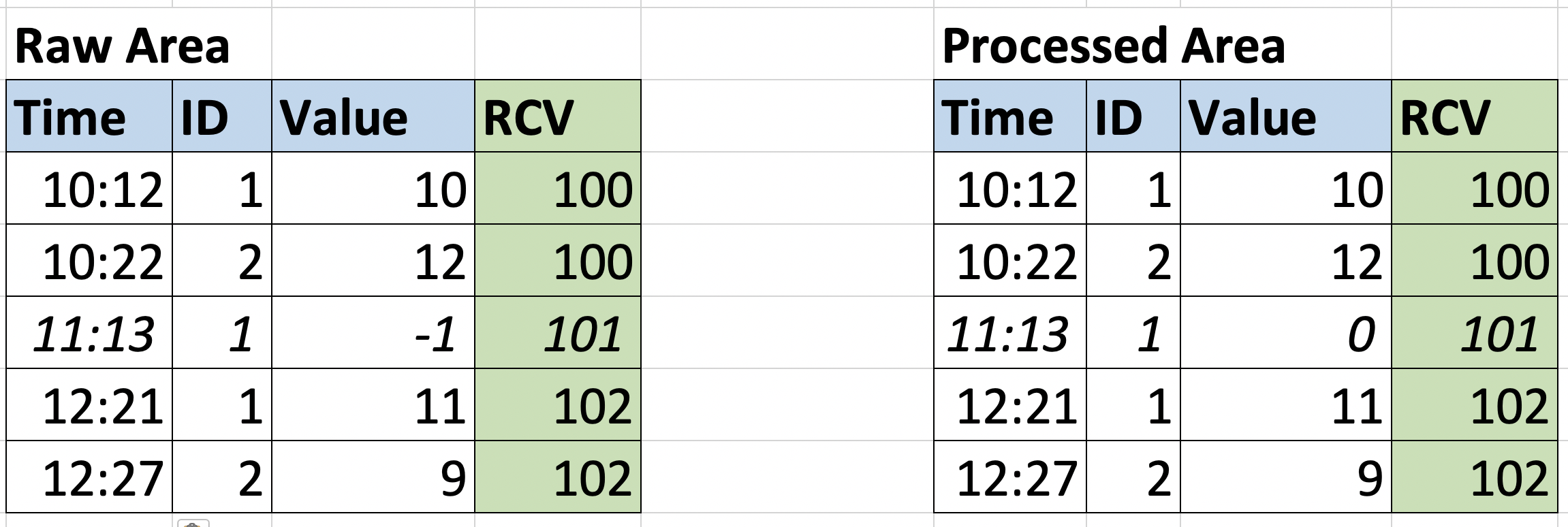
Nella versione corretta del file, c’è una voce valida per ogni entità. La pipeline utilizzerà l’RCV=101 come riferimento per ripulire la tabella dall’esecuzione precedente e ingerire il nuovo file.
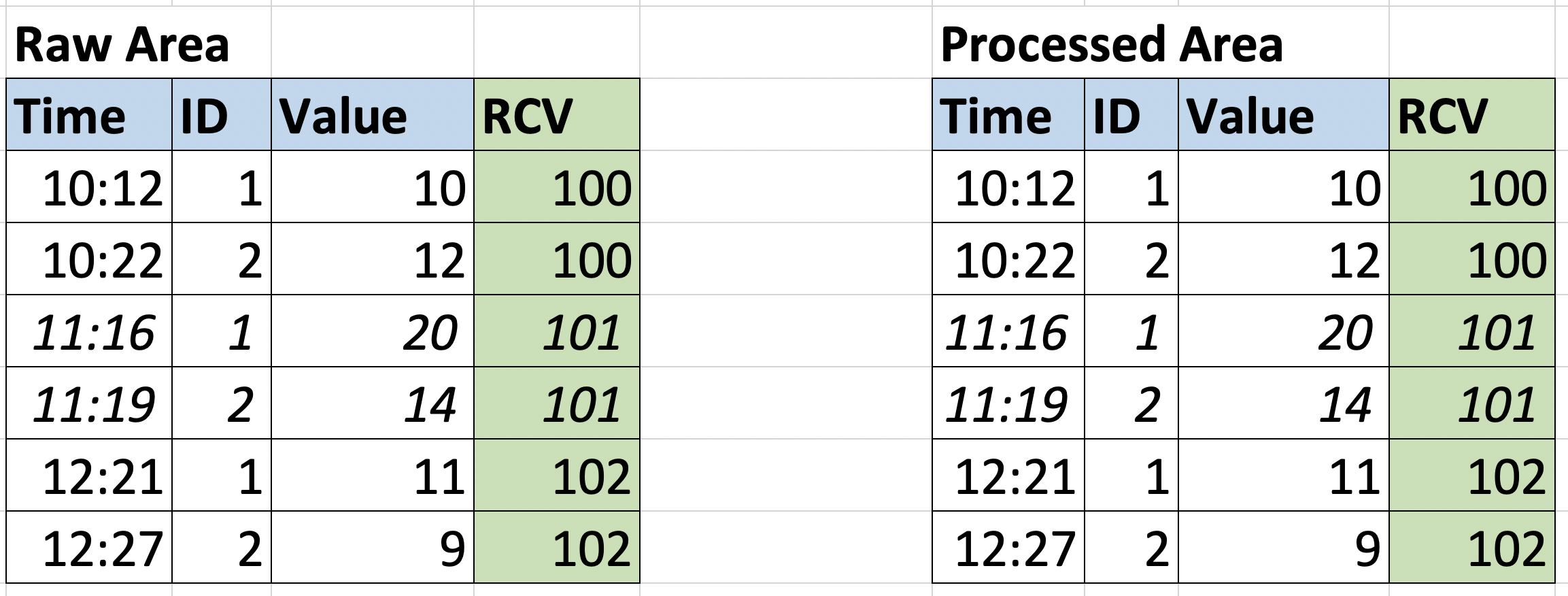
In questo caso, il Run Control Value ci permette di identificare con precisione quale porzione di dati è stata ingerita con l’esecuzione precedente, in modo da poterla rimuovere con sicurezza e rieseguire l’esecuzione con quella corretta.
Questi sono solo due semplici scenari che possono essere affrontati con questa tecnica, ma molti altri problemi della pipeline di dati possono trarre vantaggio da questo approccio.
Inoltre, questo meccanismo ci permette di avere l’idempotenza degli stadi della pipeline, cioè la possibilità di tracciare i dati che passano attraverso i diversi stadi, e di riapplicare le trasformazioni sullo stesso input e ottenendo il medesimo risultato.
Conclusioni
In questo articolo ci siamo immersi un po’ nel mondo dell’ingegneria dei dati, scoprendo in particolare come gestire i dati provenienti da fonti inaffidabili, la maggior parte dei casi nei progetti reali.
Abbiamo visto perché la separazione delle fasi è importante nella progettazione di una pipeline dati e anche quali proprietà avrà ogni “area“; questo ci aiuta a capire meglio cosa sta succedendo e ad identificare i potenziali problemi.
Un altro aspetto che abbiamo evidenziato è come questa tecnica faciliti la gestione dei dati che arrivano in ritardo o il reingesting dei dati corretti, nel caso in cui un problema possa essere risolto all’origine.
Autore: Luca Tronchin, Software Engineer @Bitrock