

Introduzione
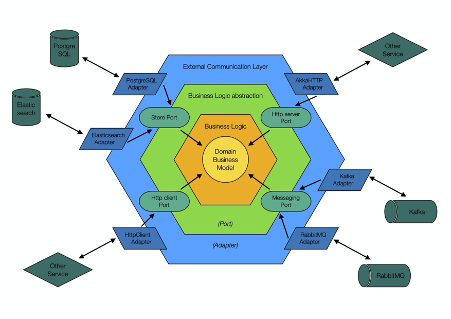
L’architettura esagonale (chiamata anche “ports and adapters”) è un modello architettonico utilizzato nella progettazione di software ideato nel 2005 da Alistair Cockburn.
L’architettura esagonale è presumibilmente all’origine dell’architettura a microservizi.
Cosa offre
L’architettura dei servizi più utilizzata è quella a strati. Spesso, questo tipo di architettura rende la logica di business dipendente da contratti esterni (ad esempio, database, servizi esterni e così via). Questo genera rigidità e coupling nel sistema, costringendoci a ricompilare le classi che contengono la logica di business ogni volta che un’API cambia.
Loose coupling
Nell’architettura esagonale, i componenti comunicano tra loro utilizzando una serie di porte esposte, che sono semplici interfacce. Si tratta di un’applicazione del principio di Dependency Inversion Principle (la “D” di SOLID).
Components intercambiabili
Un adattatore è un componente software che consente a una tecnologia di interagire con una porta dell’esagono. Gli adattatori facilitano lo scambio di un determinato livello dell’applicazione senza impattare sulla logica aziendale. Questo è un concetto fondamentale delle architetture evolutive.
Maximum isolamento
I componenti possono essere testati in isolamento dall’ambiente esterno, oppure si può ricorrere alla dependency injection e ad altre tecniche (ad esempio, mock, stub) per facilitare i test.
I contract testing sostituiscono i test di integrazione per un flusso di sviluppo più rapido e semplice.
Il dominio al centro
Gli oggetti del dominio possono contenere sia lo stato che il comportamento. Più il comportamento è vicino allo stato, più il codice sarà facile da capire, da ragionare e da mantenere.
Poiché gli oggetti di dominio non hanno dipendenze da altri livelli dell’applicazione, i cambiamenti in altri livelli non li influenzano. Questo è un ottimo esempio del Single Responsibility Principle (la “S” di “SOLID”).
Come implementarlo
Vediamo ora cosa significa costruire un progetto seguendo l’architettura esagonale per capire meglio la differenza e i suoi vantaggi rispetto a una più comune architettura a strati semplici.
Layout del progetto
In un progetto con architettura a strati, la struttura dei pacchetti è solitamente la seguente:
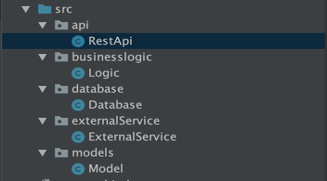
Qui possiamo trovare un pacchetto per ogni livello applicativo:
- quello responsabile dell’esposizione del servizio per la comunicazione esterna (ad esempio, API REST);
- quello in cui viene definita la logica di business principale;
- quello con tutto il codice di integrazione del database;
- quello responsabile della comunicazione con altri servizi esterni;
e altro ancora…
Layers Coupling
A prima vista, questa potrebbe sembrare una soluzione ottimale per mantenere i diversi pezzi dell’applicazione separati e ben organizzati, ma, se ci addentriamo un po’ di più nel codice, possiamo trovare alcuni segnali che dovrebbero metterci in guardia. Infatti, dopo una rapida ispezione della logica di business principale dell’applicazione, troviamo subito qualcosa di decisamente in contrasto con la nostra idea di separazione pulita e ben definita dei vari componenti. La logica di business che vorremmo mantenere isolata da tutti i livelli esterni fa chiaramente riferimento ad alcune dipendenze dal database e dal pacchetto di servizi esterni.
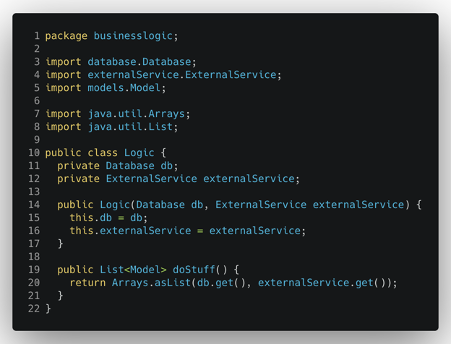
Queste dipendenze implicano che, in caso di modifiche al codice del database o alla comunicazione con i servizi esterni, dovremo ridefinire la logica principale e probabilmente modificarla e adattarla, per renderla compatibile con le nuove versioni del database e dei servizi esterni. Ciò significa che dobbiamo dedicare tempo a questa nuova integrazione, testarla adeguatamente e, durante questo processo, esporci all’introduzione di alcuni bug.
Interfacce in soccorso
È qui che l’architettura esagonale si rivela davvero vincente e ci aiuta a evitare tutto questo. Per prima cosa dobbiamo disaccoppiare la logica aziendale dalle sue dipendenze dal database: questo si può ottenere facilmente con l’introduzione di una semplice interfaccia (chiamata anche “porta”) che definisca il comportamento che una certa classe del database deve implementare per essere compatibile con la nostra logica principale.
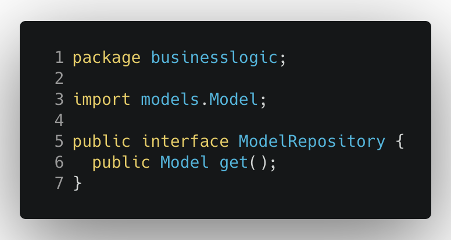
Possiamo quindi usare questo vincolo nell’implementazione effettiva del database, per essere sicuri che sia conforme al comportamento definito.
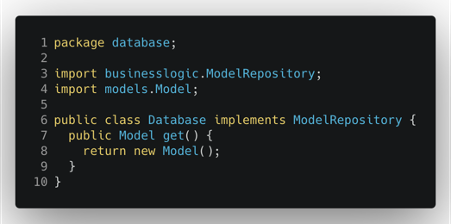
Tornando alla nostra classe logica principale grazie alle modifiche descritte in precedenza, possiamo finalmente evitare la dipendenza dal database e avere la logica di business completamente disaccoppiata dai persistence details.
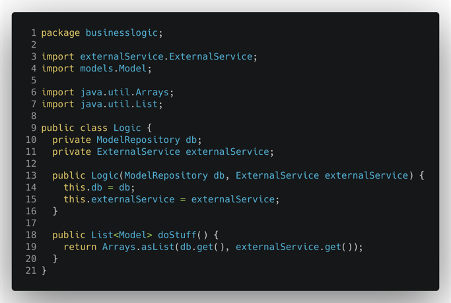
È importante notare che la nuova interfaccia introdotta è definita all’interno del pacchetto della logica di business e, quindi, fa parte di esso e non del livello del database. Questo trucco ci permette di applicare il Dependency Inversion Principle e di mantenere il core della nostra applicazione puro e isolato da tutti i dettagli esterni.
Possiamo poi applicare lo stesso approccio alla dipendenza dal servizio esterno e infine liberare l’intera classe logica da tutte le sue dipendenze dall’altro livello dell’applicazione.
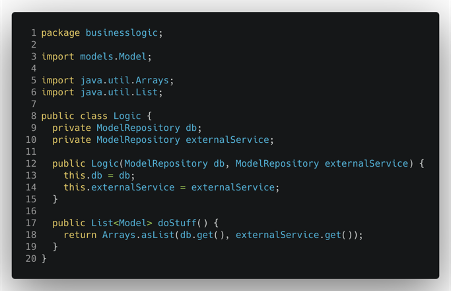
DTO per l’estrazione del modello
Questo ci dà già un buon livello di separazione, ma c’è ancora margine di miglioramento. Infatti, se si guarda alla definizione della classe Database, si noterà che stiamo usando lo stesso modello della nostra logica principale per operare sul persistence layer. Sebbene questo non sia un problema per l’isolamento della nostra logica principale, potrebbe essere una buona idea creare un modello separato per il persistence layer, in modo che se dobbiamo apportare delle modifiche alla struttura della tabella, per esempio, non siamo costretti a replicare le modifiche anche al business logic layer. Questo si può ottenere con l’introduzione di un DTO (Data Transfer Object).
Un DTO non è altro che un nuovo modello esterno con una coppia di funzioni di mappatura che ci permettono di trasformare il nostro modello di business interno in quello esterno e viceversa. Prima di tutto, dobbiamo definire il nuovo modello privato per il nostro database e i livelli di servizio esterni.
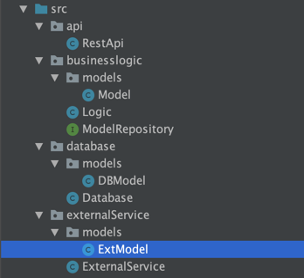
Occorre poi creare una funzione adeguata per trasformare questo nuovo modello di database nel modello di logica aziendale interna (e viceversa, in base alle esigenze dell’applicazione).
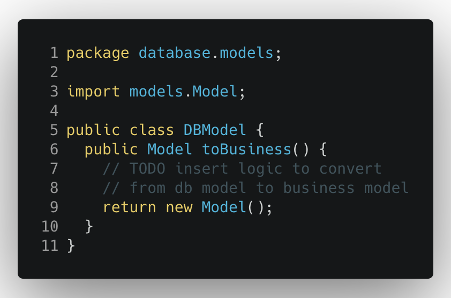
Ora possiamo finalmente modificare la classe Database per lavorare con il nuovo modello introdotto e trasformarlo in quello logico quando comunica con il business logic layer.
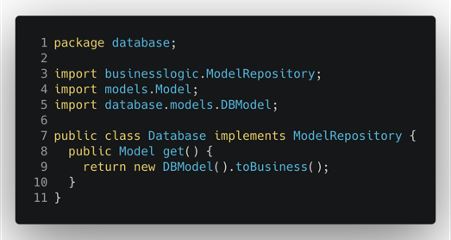
Questo approccio funziona molto bene per proteggere la nostra logica da interferenze esterne, ma ha alcune conseguenze. La principale è l’ aumento del numero di modelli, quando il più delle volte i modelli sono gli stessi; l’altra è che la logica di trasformazione dei modelli può essere complicata e deve sempre essere testata adeguatamente per evitare errori. Un compromesso che si può adottare è quello di iniziare solo con i modelli di business (definendoli nel pacchetto corretto) e introdurre i modelli esterni solo quando i due modelli divergono.
Quando adottarla
L’architettura esagonale non è una formula magica. Se si sta costruendo un’applicazione con svariate regole di business esprimibili in un modello di dominio ricco che combina stato e comportamento, allora questa architettura brilla davvero perché mette il domain model al centro.
Combinandola con l’architettura a microservizi, si ottiene un’architettura evolutiva future-proof.