

Con l’aumento di popolarità dei framework JavaScript, di Node e delle tecnologie container, negli ultimi anni si è assistito all’ascesa dei microservizi come modello principale nell’architettura delle applicazioni distribuite sul Web; la lingua franca di queste applicazioni sono, ovviamente, le API. Gli sviluppatori che adottano questi strumenti moderni per gli ambienti front-end hanno però dovuto affrontare sfide emergenti per quanto riguarda l’ottimizzazione dei motori di ricerca, il rendering dei contenuti e il servizio delle applicazioni rispetto al comune stack LAMP, in cui PHP svolge la maggior parte del lavoro e JavaScript fornisce solo le interazioni e gli elementi dinamici.
Dal lato client all’ibrido
Mentre in passato l’utilizzo di framework sul lato client significava applicazioni single page, con l’uso di “hack” come l’hashbang per fornire la navigazione, negli ultimi anni i principali framework JavaScript hanno abbracciato l’approccio ibrido al rendering, in cui sia il server che il client eseguivano lo stesso DOM virtuale e si riconnettevano al browser in un secondo momento, “reintegrando” l’applicazione sul client. In questo modo, le applicazioni supportavano sia i controlli di navigazione comuni del browser, sia l’accessibilità per gli utenti con browser meno recenti o addirittura senza JavaScript, poiché la pagina era immediatamente disponibile sul server. Ciò ha permesso di migliorare le prestazioni al primo caricamento e di supportare gli spider tradizionali dei motori di ricerca.
Tuttavia, ciò significava
- avere un’esperienza migliore per gli sviluppatori, poiché l’intera applicazione utilizza solo JavaScript e HTML, con un’unica base di codice… ma Node non supporta gli stessi moduli e le stesse funzionalità di un browser
- subire un impatto su una serie di metriche, come il Time To First Byte e il Time To Interactive, poiché il codice viene eseguito su entrambi i fronti
- fare affidamento su un’implementazione sempre più complessa sul server rispetto all’hosting condiviso tradizionale
- utilizzare la “forza bruta” per il prerendering e il caching delle applicazioni, come i browser headless.
Limiti del CMSs
Molte applicazioni web moderne non sono altro che elenchi meramente descrittivi di contenuti, che a volte consentono interazioni modeste – come il filtraggio o l’ordinamento dei contenuti – fornendo tassonomie e interagendo con componenti limitati – come i moduli per i commenti o la barra di ricerca. Poiché la maggior parte dei contenuti è statica, una soluzione front-end completa è considerata un costo aggiuntivo rispetto ai CMS monolitici esistenti; questi rimangono grandi comunità che offrono una moltitudine di temi e plugin e interfacce ben rodate per i creatori di contenuti.
Tuttavia, questi CMS non offrono ancora la stessa velocità o esperienza di sviluppo delle applicazioni scritte per Node, che possono essere avviate su qualsiasi macchina con nient’altro che il runtime di Node e hanno cicli molto veloci per le modifiche. Inoltre, di solito hanno un supporto limitato per i componenti, o li circoscrivono al livello dei contenuti, richiedendo allo sviluppatore di inserire parti aggiuntive personalizzate per il resto della pagina, spesso in un linguaggio diverso da quello utilizzato dal browser. L’interazione rimane ancora secondaria, con JavaScript che non è in grado di superare i confini della singola pagina statica.
Infine, ma non per questo meno importante, i CMS più diffusi, come WordPress, presentano una superficie di attacco più ampia, in quanto sono incredibilmente popolari e hanno spesso lo stesso endpoint sia per il back-end che per il front-end; sono ospitati sulla stessa macchina, con lo stesso indirizzo per entrambi: a seconda del carico sulla macchina, richiedono soluzioni di scaling orizzontale e soluzioni avanzate per la gestione delle cache.
I generatori di siti statici
Anche se i CMS sono in grado di renderizzare le pagine in modo rapido e di evitare il lungo lavoro di parsing della pagina e esecuzione nel contesto del browser, richiedono comunque un server e un supporto dedicato, con una elevata complessità, difficile riproducibilità dell’ambiente di produzione su una macchina locale, e l’esposizione a numerosi vettori di attacco rappresentati dai plugin e temi di terze parti.
I siti web statici, invece, non hanno tempi di caricamento sul server, non richiedono alcuna sessione sul server, nessuna istanza di Linux in esecuzione e nessun altro requisito reale se non un server web per distribuire le risorse statiche. Possono anche vivere con uno storage a costi estremamente bassi, come S3 di Amazon.
Una soluzione moderna ai contenuti statici
Mentre i framework tradizionali come Jekyll o Hugo sono veloci e rappresentano ancora una buona soluzione, i nuovi framework che hanno fatto il loro ingresso nel mercato negli ultimi anni (come Gatsby, Gridsome, Nuxt e Next.js) hanno portato i siti statici nel futuro. Prendendo spunto dalle applicazioni ibride e dalle SPA, si basano su strumenti migliorati che girano su Node; i moderni framework web sono ormai di prim’ordine e migliorano sia l’esperienza dell’utente che quella dello sviluppatore.
Sono caratterizzati da:
- supporto SEO completo, poiché le pagine sono solo HTML e CSS come in precedenza
- nessun servizio in esecuzione; il deploy consegna semplicemente i file statici al CDN
- prestazioni migliorate secondo tutte le metriche e soluzioni ben congegnate, per i bundle JavaScript più piccoli e pipeline per le altre risorse
- le stesse interazioni complesse di una SPA, come le transizioni e lo stato persistente, cosi come gli stessi strumenti di sviluppo (come Webpack, Parcel, ecc.)
- supporto per contenuti provenienti da diverse fonti: file statici, repository di versioni, CMS headless, API e altro ancora.
Framework come Gatsby e Gridsome prendono spunto dai CMS offrendo soluzioni a diverse esigenze sotto forma di temi e plugin, pur mantenendo un’unica base di codice coesa, con dipendenze gestite attraverso lo stesso ecosistema di JavaScript, ben noto agli sviluppatori già abituati a lavorare con i moderni framework. Vengono inoltre forniti con configurazioni per i browser più vecchi, risolvendo il rebus di produrre codice compatibile, e semplici comandi per costruire o avviare l’ambiente di sviluppo.
La riduzione della complessità è significativa. Una soluzione front-end semplificata consente agli sviluppatori di concentrarsi sull’esperienza principale degli utenti, invece di perdere tempo con la configurazione. L’assenza di un vero e proprio servizio che gestisce le pagine permette al sito web di funzionare praticamente ovunque, lasciando che gli sviluppatori del backend si concentrino sulla logica aziendale e, nel mezzo, sulle API che rappresentano il contratto tra le due parti. I DevOps hanno una cosa in meno di cui preoccuparsi. Si tratta di JAMstack: JavaScript, API e linguaggi di markup.
Le sfide del JAM Stack
The massive improvements brought forth by the stack still face issues that many of the other solutions don’t, and by the nature of static contents; consequently, its strong points also represent its main pain points.
First of all, static content is never entirely static: contents will be probably updated in time and might even be real time. While recreating the bundle every time the content changes represents the quickest solution, it takes time – more than in real time at least. There have been big improvements in the speed of the tools when generating this bundle; it used to take way longer than today and support up to a few thousands pages, while today, with solutions such as partial builds, it can be mitigated. It is still not real time; real time content can only be handled through dynamic components on the client side.
Secondly, by relying on the delivery through services such as Netlify, S3, Vercel and so on, we’re leaving to the middleman to handle security and performance optimization for static files. We can also do it on our own, of course.
Third and last (but also probably the trickiest part), is that by having static files we move the concern for sessions and authentication/authorization to external microservices instead of the server. With careful reliance on Service Workers, and/or solutions such as Firebase, we can solve this. The JAM stack also strongly favours a serverless approach to server interactions: by writing simple functions in Node, to be deployed in the same hands-off approach from the same codebase (possibly even sharing code), we can handle just about everything as before with traditional AJAX requests.
Both the serverless approach and the delivery of static files is a big reduction in costs compared to deploying virtual servers, as we only use what we need and scale naturally as more the resources are required. But rarely accessed contents or functions do require some extra time as the provider has to “boot up” the context of the functions for us.
Gli enormi miglioramenti apportati dallo stack devono ancora affrontare problemi che molte altre soluzioni non affrontano, data la natura dei contenuti statici; di conseguenza, i suoi punti di forza rappresentano anche i suoi principali punti dolenti.
Innanzitutto, i contenuti statici non sono mai del tutto statici: i contenuti saranno probabilmente aggiornati nel tempo e potrebbero anche essere in tempo reale. Sebbene ricreare il bundle ogni volta che il contenuto cambia rappresenti la soluzione più rapida, richiede tempo, almeno più che in tempo reale. Ci sono stati grandi miglioramenti nella velocità degli strumenti per la generazione di questo bundle; prima ci voleva molto più tempo rispetto a oggi e per supportare fino a qualche migliaio di pagine, mentre oggi, con soluzioni come le build parziali, si può attenuare il problema. Tuttavia, non è ancora in real time in quanto i contenuti in real time possono essere gestiti solo attraverso componenti dinamici sul lato client.
In secondo luogo, affidandoci alla delivery attraverso servizi come Netlify, S3, Vercel e così via, lasciamo che sia l’intermediario a gestire la sicurezza e l’ottimizzazione delle prestazioni per i file statici, delegando a terze parti scelte potenzialmente critiche.
Il terzo e ultimo punto è il fatto che, avendo file statici, trasferiamo la problematica delle sessioni e dell’autenticazione/autorizzazione a microservizi esterni, invece che al server. Con un accorto affidamento ai Service Worker e/o a soluzioni come Firebase, possiamo risolvere questo problema. Lo stack JAM favorisce inoltre un approccio serverless alle interazioni con il server: scrivendo semplici funzioni in Node, da distribuire con lo stesso approccio hands-off dalla stessa codebase (eventualmente anche condividendo il codice), possiamo gestire praticamente tutto come prima con le tradizionali richieste AJAX.
Sia l’approccio serverless che la distribuzione di file statici rappresentano una grande riduzione dei costi rispetto alla distribuzione di server virtuali, in quanto utilizziamo solo ciò che ci serve e scaliamo in modo naturale man mano che le risorse vengono richieste. Tuttavia, i contenuti o le funzioni a cui si accede raramente richiedono un po’ di tempo in più, poiché il provider deve “avviare” il contesto delle funzioni per noi.
Un caso d’uso comune: un Blog e le sue pagine
I siti web statici sono molto adatti a fornire i contenuti di un prodotto editoriale. Il testo e le immagini di solito non vengono aggiornati in tempo reale e i needs aziendali sono spesso allineati con la value proposition dei generatori di siti statici:
- Un ambiente sicuro con una ridotta area di attacco per il pubblico.
- Prestazioni veloci su tutte le metriche, per incrementare le prestazioni SEO e mobile.
- Costi ridotti, in termini di sviluppo, implementazione e manutenzione.
Negli ultimi decenni questo ambiente è stato dominato da WordPress e dai suoi temi, che forniscono una soluzione sufficientemente buona per la maggior parte delle aziende e, poiché sono così comunemente utilizzati, gli editor non hanno bisogno di imparare di nuovo come fare le cose.
Poiché WordPress ha sviluppato le proprie API nell’ultimo decennio, possiamo affidarci ad esso per fornire la base per i nostri contenuti e accedere all’ecosistema e al know-how esistente, distribuendolo su una soluzione a basso costo come WordPress.com o magari su un piccolo VPS. Tutto ciò di cui abbiamo bisogno è un modo sicuro per trasferire i nostri contenuti dalla nostra installazione al nostro generatore di siti statici, che genererà la pagina al momento della creazione chiamando le API. Potremmo facilmente implementare un CMS headless o anche una soluzione completamente personalizzata: dal punto di vista dello sviluppo frontend non ha molta importanza.
La scelta di un generatore di siti statici può essere decisa anche in base alle competenze degli sviluppatori che lavorano al progetto. Sul versante React, sia Gatsby che Next.js sono soluzioni molto popolari, con Gatsby che ha un set di plugin già consolidato e template molto simili a WordPress che possono accelerare lo sviluppo. Sul lato Vue, Vuepress e Gridsome sono due soluzioni comuni: la prima è la più semplice delle due in termini di funzionalità e approccio ai contenuti (utilizzando file Markdown), mentre la seconda è più simile a Gatsby, fornendo plugin e template. Sia Gridsome che Gatsby, infatti, utilizzano GraphQL come lingua franca per i nostri contenuti, in modo da poter integrare molte fonti e utilizzarle in modo comune.
Infine, ma non meno importante, possiamo decidere dove distribuire i nostri contenuti. C’è un numero enorme di possibilità, dalle CDN agli archivi (come S3) o a molti servizi che si vantano della loro semplicità, come Netlify e Heroku. In ogni caso, ciò di cui abbiamo bisogno è un canale per distribuire il bundle dei contenuti ai nostri utenti; ogni volta che aggiorniamo i nostri contenuti, chiameremo semplicemente un’API per attivare nuovamente il processo di creazione e ricaricare i file.
Un esempio con Gatsby
Per costruire un progetto di esempio, utilizzeremo DigitalOcean per ospitare la nostra installazione di WordPress. Il nostro generatore sarà Gatsby per questo esempio specifico, ma i concetti sono abbastanza simili per molti altri. Si noti che useremo solo una funzione per costruire le pagine, ma molti di questi generatori offrono l’integrazione con CMS esterni e potrebbero usare GraphQL e simili per fare le query; questo è solo un esempio generico.
Per iniziare, abbiamo creato un droplet su DigitalOcean usando la loro immagine per WordPress su Ubuntu 18.04. Potete trovare maggiori informazioni sul loro sito web, in quanto la loro procedura guidata farà la maggior parte del lavoro per voi. Non dimenticate di seguire l’installazione di WordPress stesso. Per questo esempio, non configureremo nemmeno un dominio per la nostra installazione, ma sicuramente vorrete utilizzare una configurazione adeguata. Molti hosting offrono anche soluzioni semplici per ospitare applicazioni come WordPress e svolgeranno il lavoro in modo adeguato.
Ora che WordPress è stato configurato, possiamo iniziare a lavorare sul nostro front-end. Per prima cosa, creiamo il progetto utilizzando l’interfaccia a riga di comando di Gatsby.
npm install -g gatsby-cli
gatsby new example-wordpress
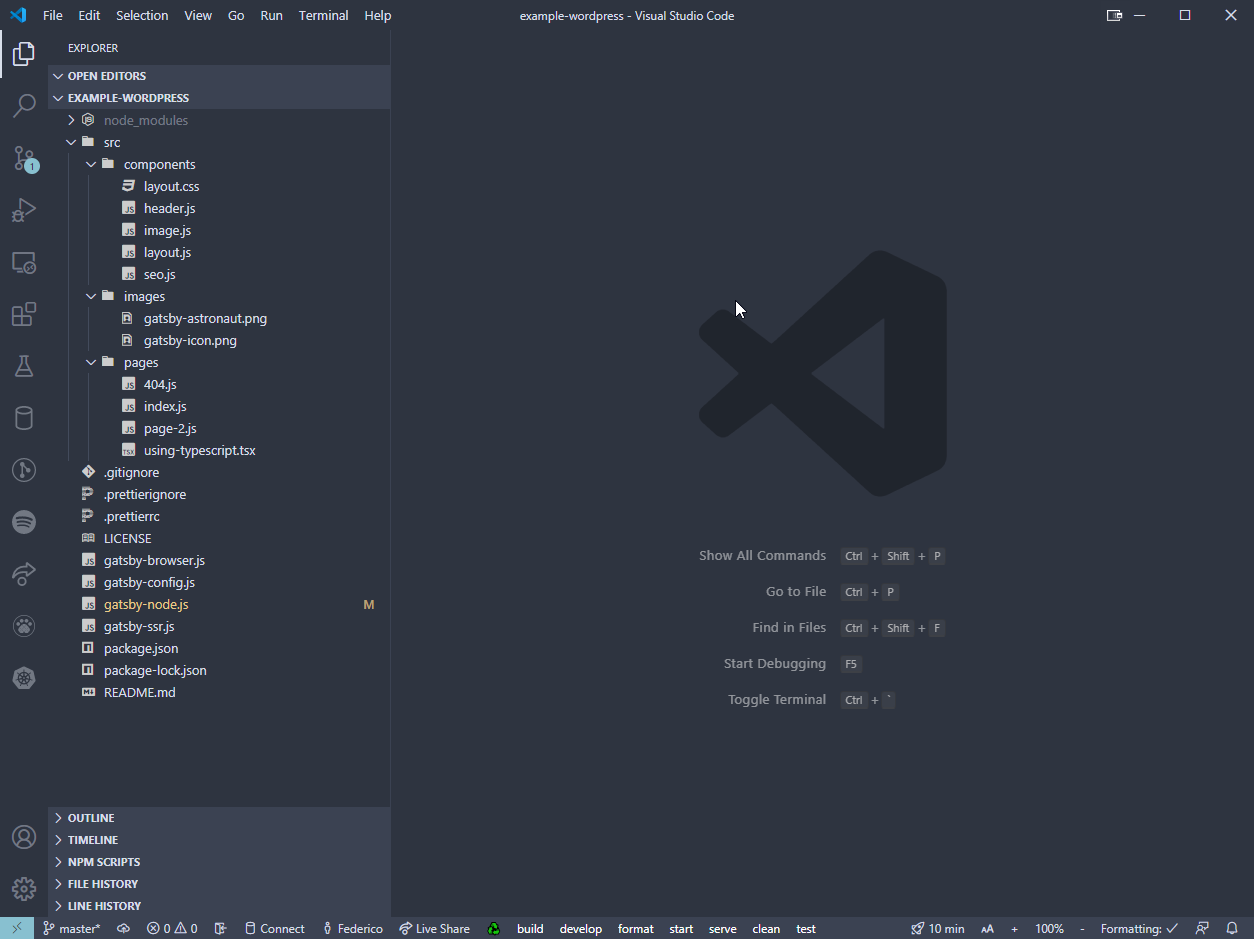
Questo crea il nostro progetto di base, utilizzando lo starter kit predefinito di Gatsby. All’interno di example-wordpress\\ possiamo trovare i moduli necessari già preinstallati, alcune configurazioni per lo styling del codice (con Prettier) e la cartella del codice sorgente (src\); quest’ultima ha al suo interno sia la cartella dei components\ React\ che quella delle pages\. I file all’interno della cartella pages\saranno accessibili per impostazione predefinita attraverso il loro nome di file (ad esempio, page-2\si troverà in example.com/page-2\).
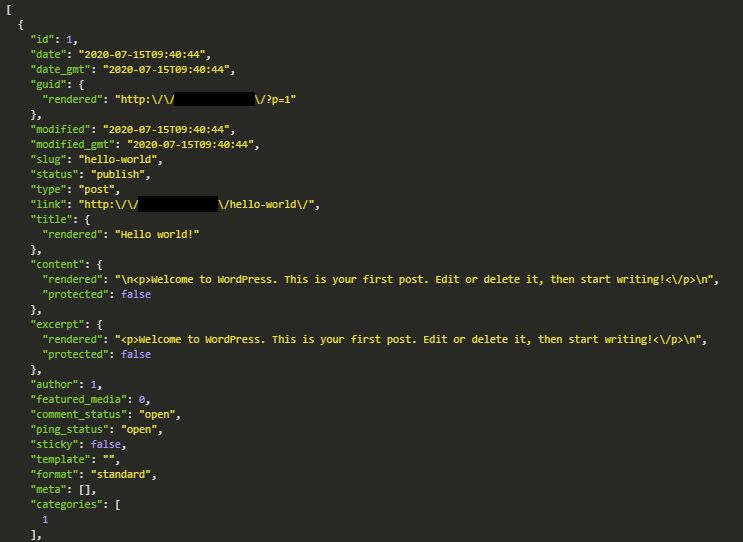
Quello che vogliamo fare è collegarci al processo di creazione di Gatsby e generare le nostre pagine dall’API di WordPress. Potete trovare maggiori informazioni sulle API nel REST API Handbook, ma il succo è che stiamo richiedendo la risorsa post utilizzando l’endpoint corretto. È possibile visualizzare un’anteprima delle risorse disponibili andando alla pagina example.com\\wp-json\; noi accediamo a wp\\v2\, sotto il quale abbiamo i contenuti editoriali, e interroghiamo i post. Il nostro URL sarà qualcosa come example.com/wp-json/wp/v2/posts\.
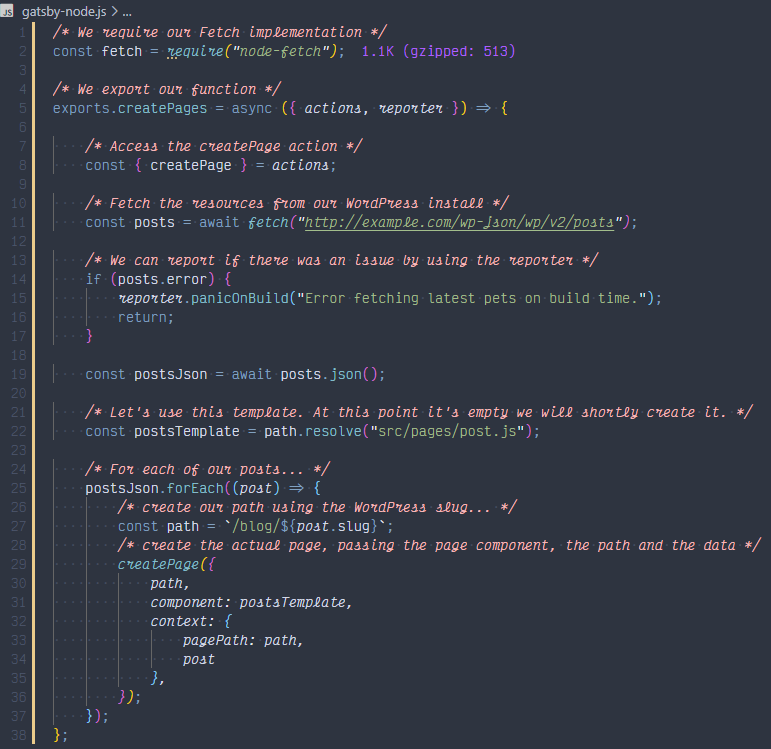
Ora dobbiamo solo inserirlo in Gatsby e costruire le pagine. Per farlo, apriamo il nostro progetto e navighiamo fino al file gatsby-node.js\, che dovrebbe trovarsi nella radice. Installiamo e importiamo il modulo \ node-fetch\, in modo da avere un’interfaccia facile da usare per ottenere la nostra risorsa:
npm install –save node-fetch
E mettiamo all’inizio del file la nostra importazione:
const fetch = require(\MARKDOWN_HASH03c697f1f26e7438c661b7bc6dd0f4b2MARKDOWNHASH)
Successivamente, prepariamo lo step di creazione delle pagine, ovvero \createPages\ di Gatsby. Per farlo, esporteremo un metodo asincrono dal nostro file, chiamato \createPages\, che riceve un oggetto con le \actions\ disponibili e un oggetto \reporter\ che può dire a Gatsby se qualcosa è andato storto. All’interno di questa funzione, recuperiamo i nostri post e creiamo una pagina per ciascuno di essi.
Creiamo il modello di pagina per i post del blog. Creiamo un file nella cartella \pages\ chiamato \post.js\ e accediamo ai dati dei post leggendoli dagli oggetti di scena del nostro componente di pagina.
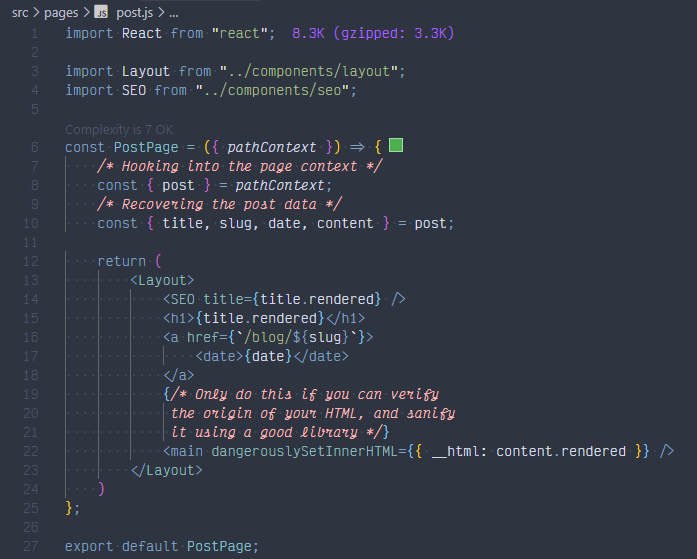
Ora dovremmo avere una pagina corrispondente nel nostro front-end:
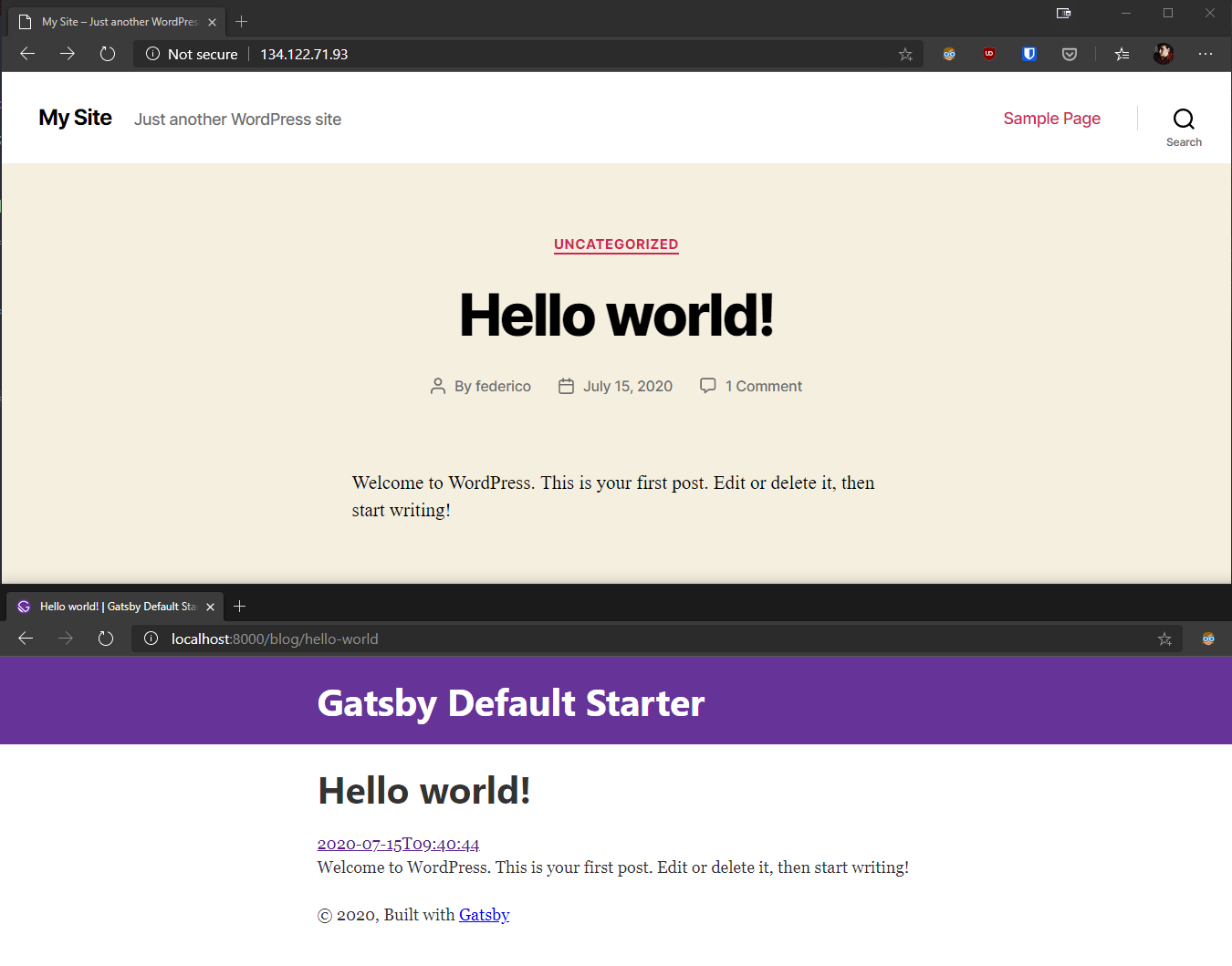
Naturalmente questo è solo l’inizio.
- Per ospitare i nostri contenuti online, potremmo affidarci a qualcosa come Netlify. Basta trasferire il nostro progetto su Github e aggiungere Netlify come applicazione.
- Per attivare la ricostruzione dei nostri contenuti, potremmo ad esempio effettuare una chiamata tramite cURL ai nostri servizi sull’on the \
save_post\. - Potremmo costruire le nostre pagine di tassonomia, utilizzando le API di WordPress o il JSON dei post. Per integrarlo meglio in Gatsby (o forse in Gridsome), potremmo aggiungere i nostri post come nodi GraphQL.
- Una critica comune a questo tipo di soluzione è che i redattori non hanno un’idea precisa di come i contenuti finiranno per apparire sul front-end. Possiamo costruire un semplice editor WYSIWYG sul lato front-end, affidandoci a una buona libreria come Draft.js. Naturalmente questo richiede anche l’autenticazione e così via. Potremmo anche condividere lo stesso CSS e lo stesso HTML tra l’ambiente WordPress e Gatsby.
- Potremmo bloccare le API di WordPress dietro una semplice autenticazione utilizzando Apache o Nginx, che sono piuttosto comuni in questo tipo di configurazioni. L’accesso tramite Node è banale.
Conclusioni
I generatori di siti statici ci permettono di fornire una buona esperienza utente e anche buone prestazioni, con un po’ più di sforzo rispetto all’utilizzo di CMS comuni come WordPress come approccio monolitico. Possiamo integrare fonti diverse e creare soluzioni molto personalizzate utilizzando scaffolding e strumenti moderni. Tuttavia, ciò richiede uno sforzo maggiore e la disconnessione tra frontend e backend può essere un punto dolente per i nostri redattori.
Autore: Federico Muzzo, UX/UI Engineer @Bitrock